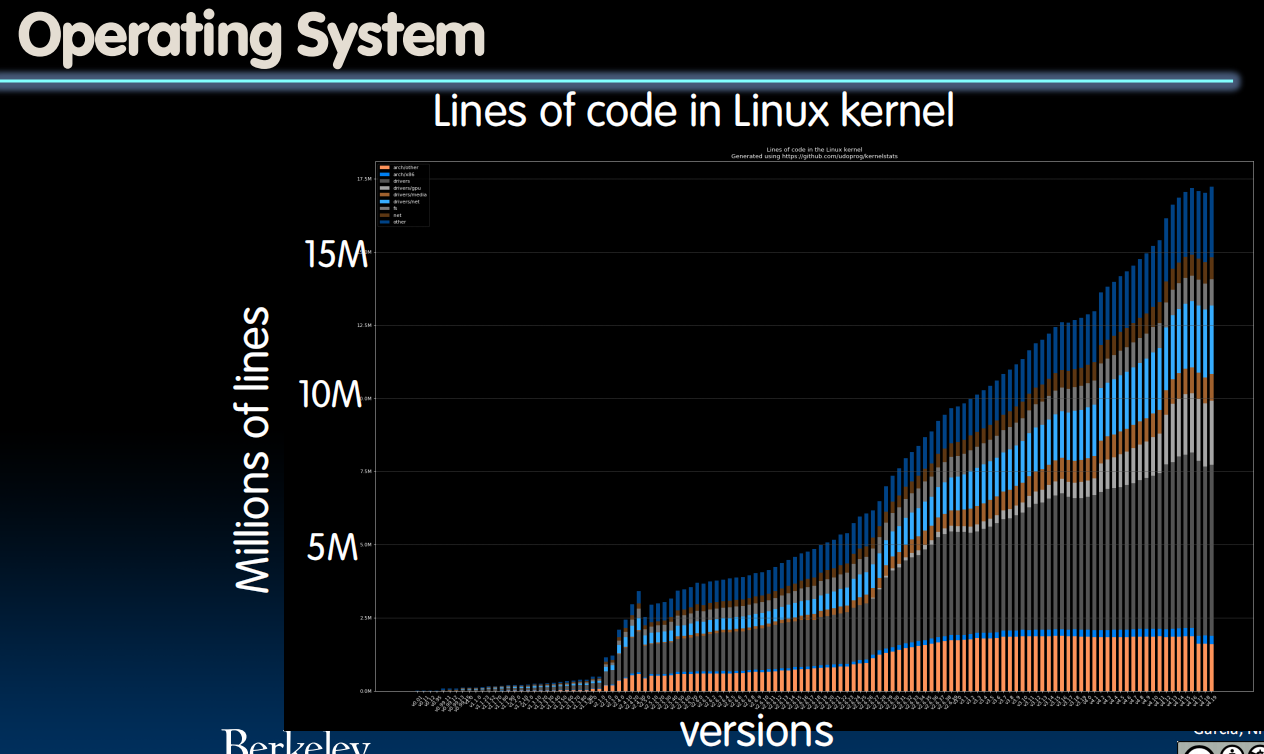
这是一个CS61C的笔记,由于是边上课边记的,很多地方选择偷懒进行截图,,,
Lecture 21 (Pipelining 1)
Pipelining
-
- Performance Measurement & Improvement
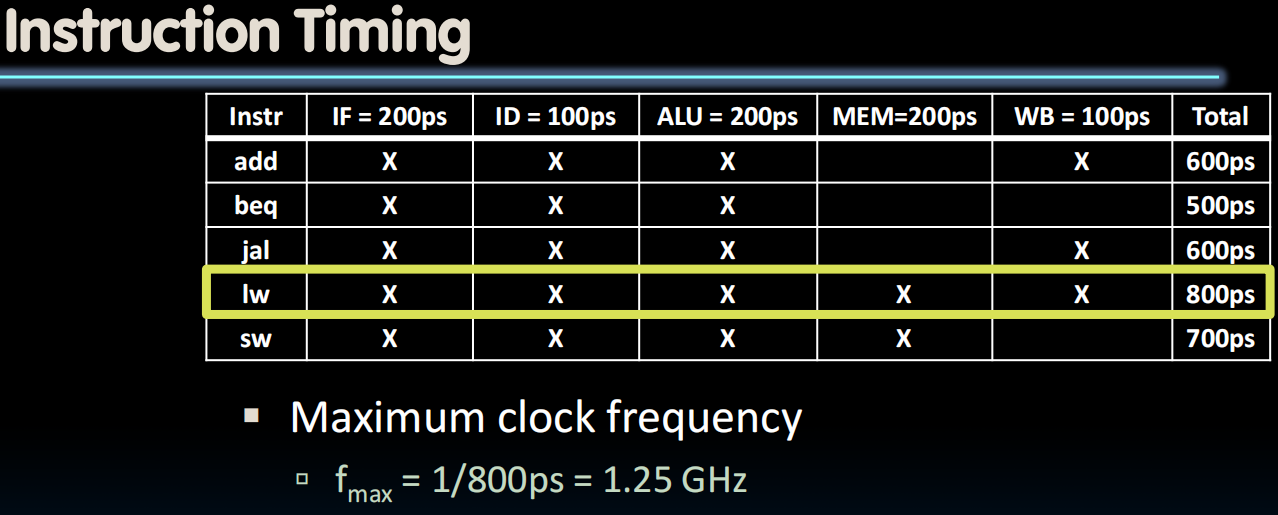
- Performance Measurement & Improvement
- “Our” Single-cycle RISC-V CPU executes instructions at 1.25 GHz
- 1 instruction every 800 ps
- Can we improve its performance?
- Quicker response time, so one job finishes faster?
- More jobs per unit time (e.g. web server returning pages, spoken words recognized)?
- Longer battery life?
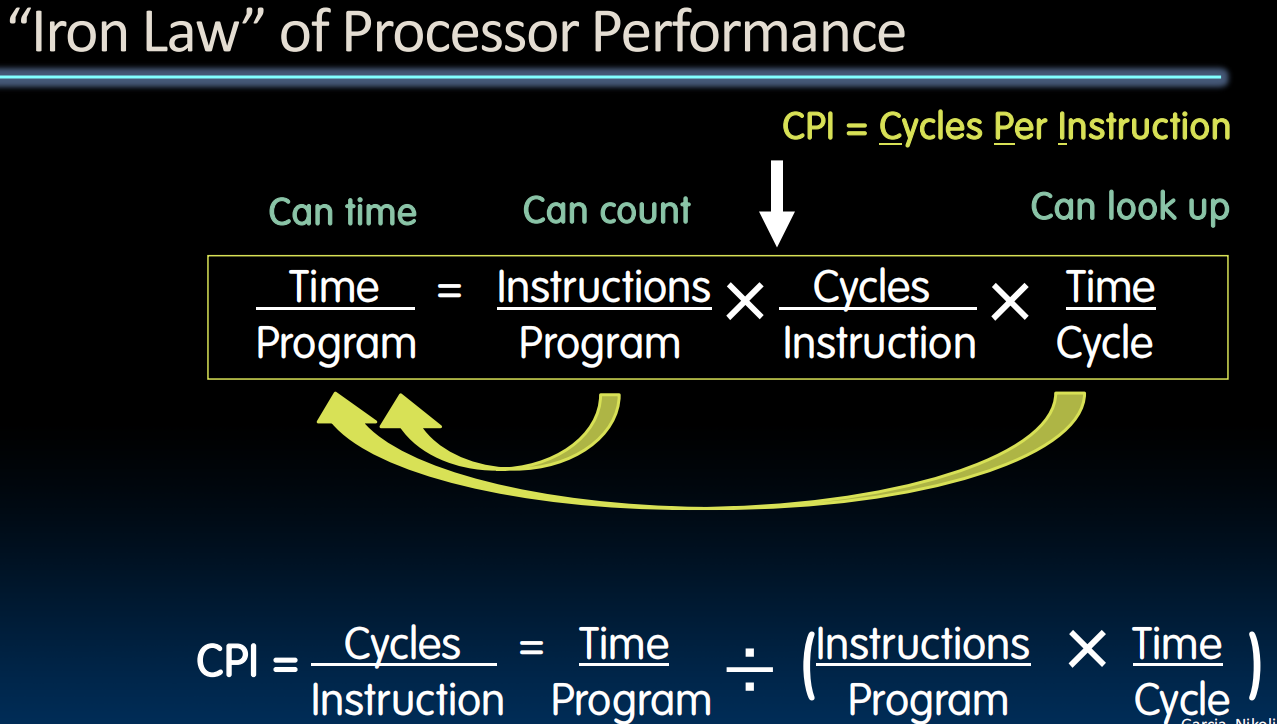
Processor Performance Iron Law
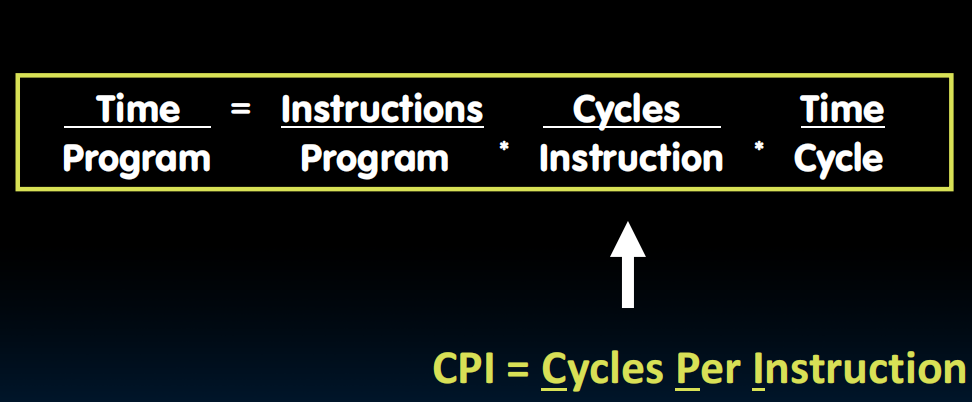
- Instructions per Program
- Determined by
- Task
- Algorithm
- Programming language
- Compiler
- Instruction Set Architecture (ISA)
- Determined by
- (Average) Clock Cycles per Instruction (CPI)
- Determined by
- ISA
- Processor implementation (or microarchitecture)
- For “our” single-cycle RISC-V design, CPI = 1
- Complex instructions (e.g. strcpy), CPI >> 1
- Superscalar processors, CPI < 1 (next lectures)
- Determined by
- Time per Cycle (1/Frequency)
- Determined by
- Processer microarchitecture
determines critical path through logic gates
- Techinology
5nm versus 28nm
- Power budget
lower voltages reduce transistor speed
- Processer microarchitecture
- Determined by
Energy Efficiency

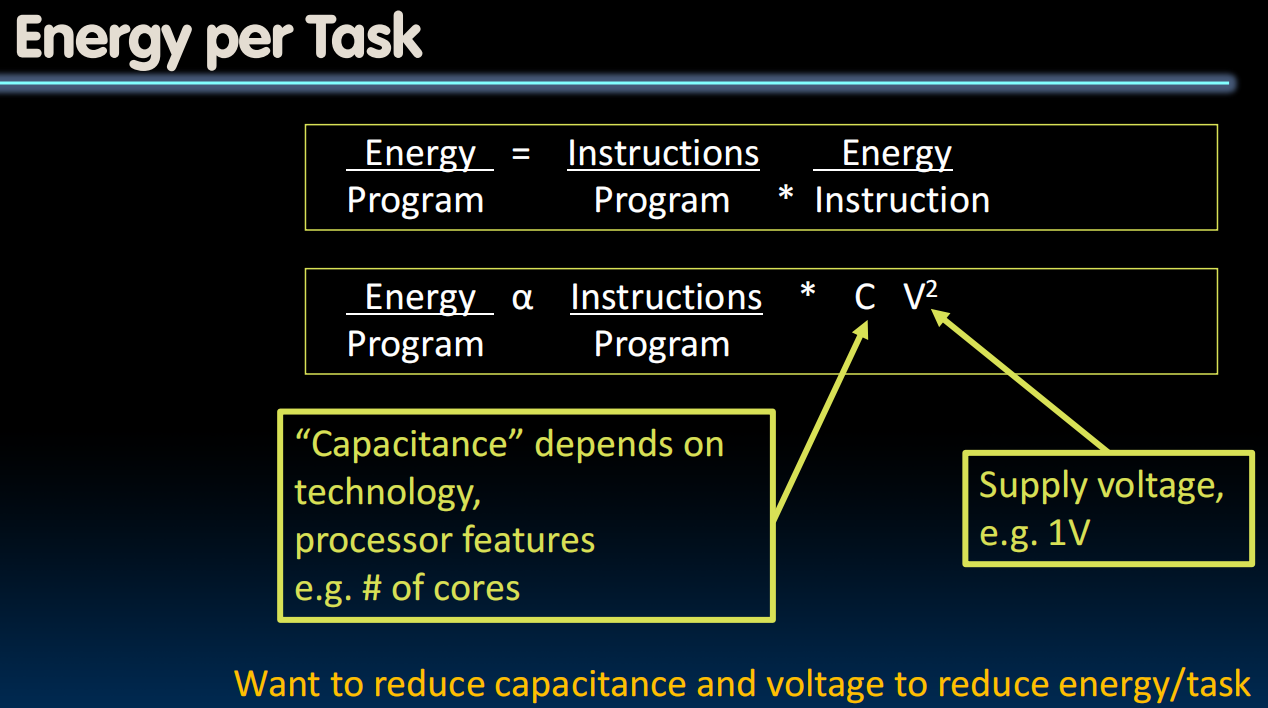
- voltage is a more powerful knob.
lowering the voltage affects the performance, because transistors are slower when running at a lower supply voltage.
- End of Scaling
- Industry not been able to reduce supply voltage much, as reducing it further would mean increasing “leakage power” where transistor switches don’t fully turn off (more like dimmer switch than on-off switch)
- Size of transistors and hence capacitance, not shrinking as much as before between transistor generations
- Need to go to 3D
- Power becomes a growing concern – the “power wall”
- Energy iron Law

- Energy efficiency (e.g., instructions/Joule) is key metric in all computing devices
- For power-constrained systems (e.g., 20MW datacenter), need better energy efficiency to get more performance at same power
- For energy-constrained systems (e.g., 1W phone), need better energy efficiency to prolong battery life
Introducing to Pipelining
- Pipelining doesn’t help latency of single task, it helps throughput of entire workload
- Multiple tasks operating simultaneously using different resources
- Potential speedup = Number of pipe stages
- Time to “fill” pipeline and time to “drain” it reduces speedup:
- 2.3X v. 4X in this example
- Pipeline rate limited by slowest pipeline stage
- Unbalanced lengths of pipe stages reduce speedup
Lecture 22 (Pipelining 2)
Pipelining RISC-V
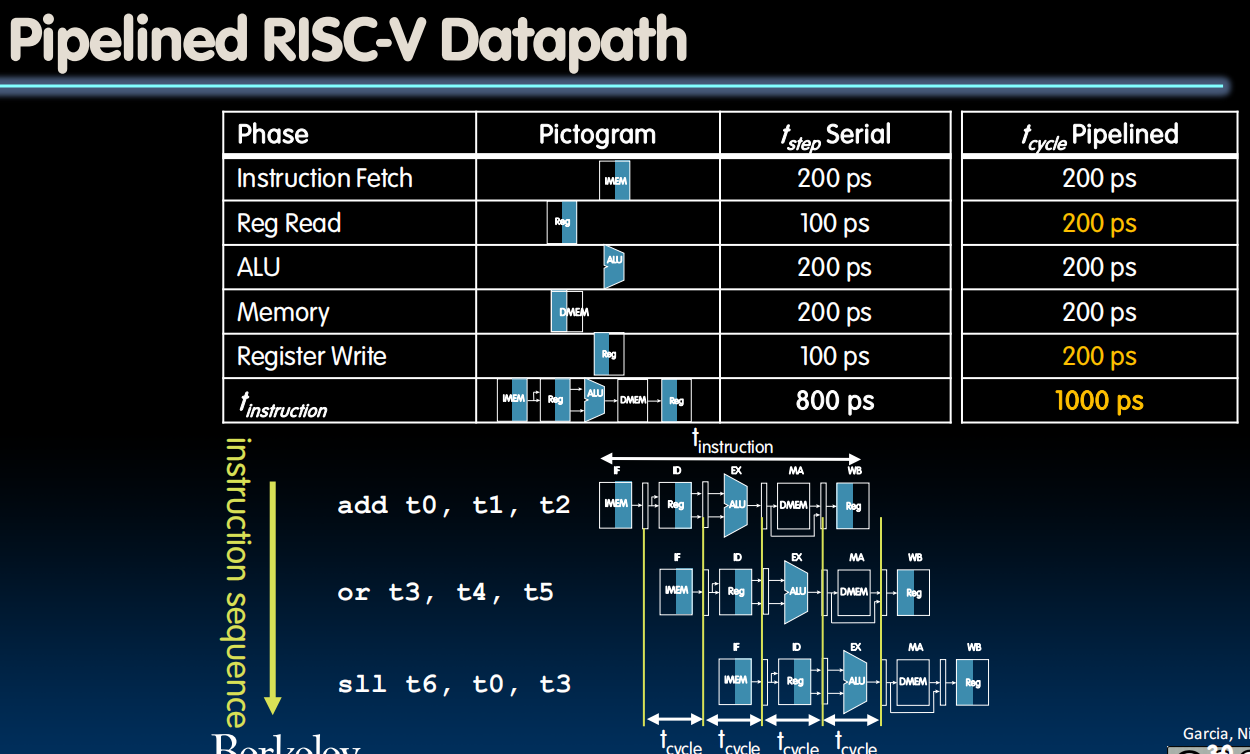
- clk is 200ps to support all the instructions
- We lose on the latency od the single instruction, but we gain dramatically on the throughput
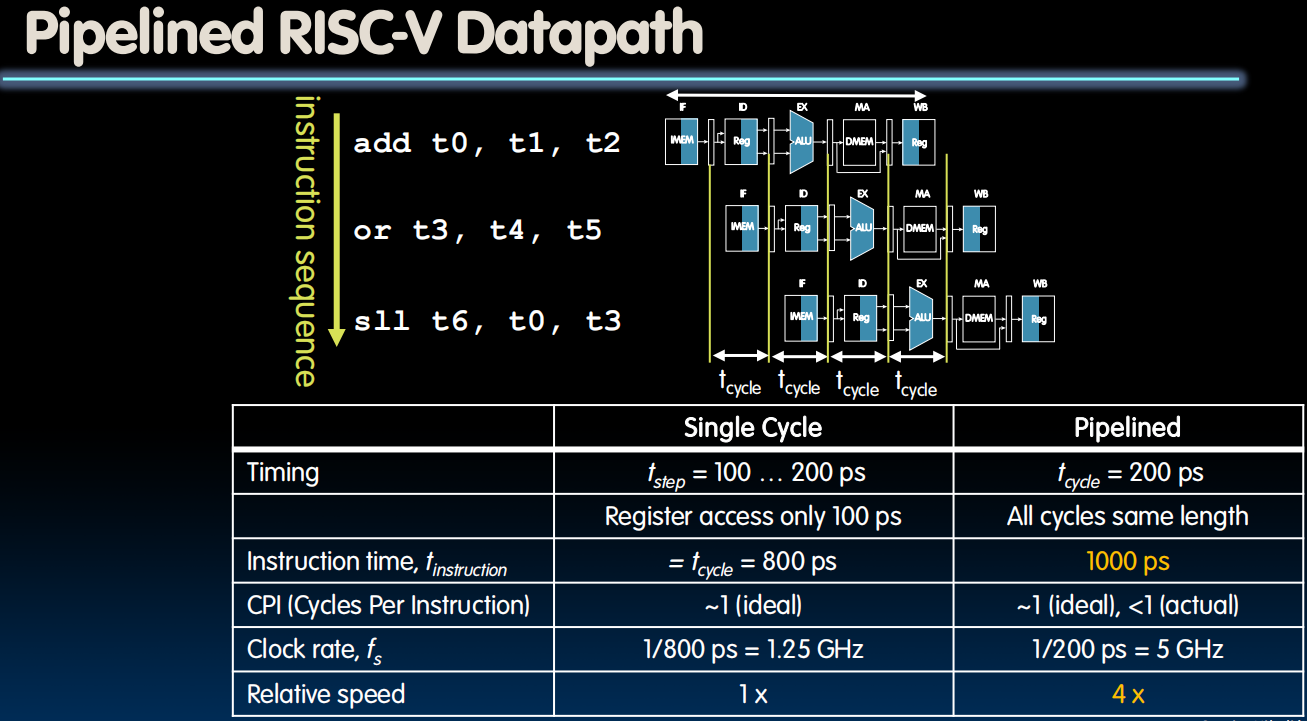
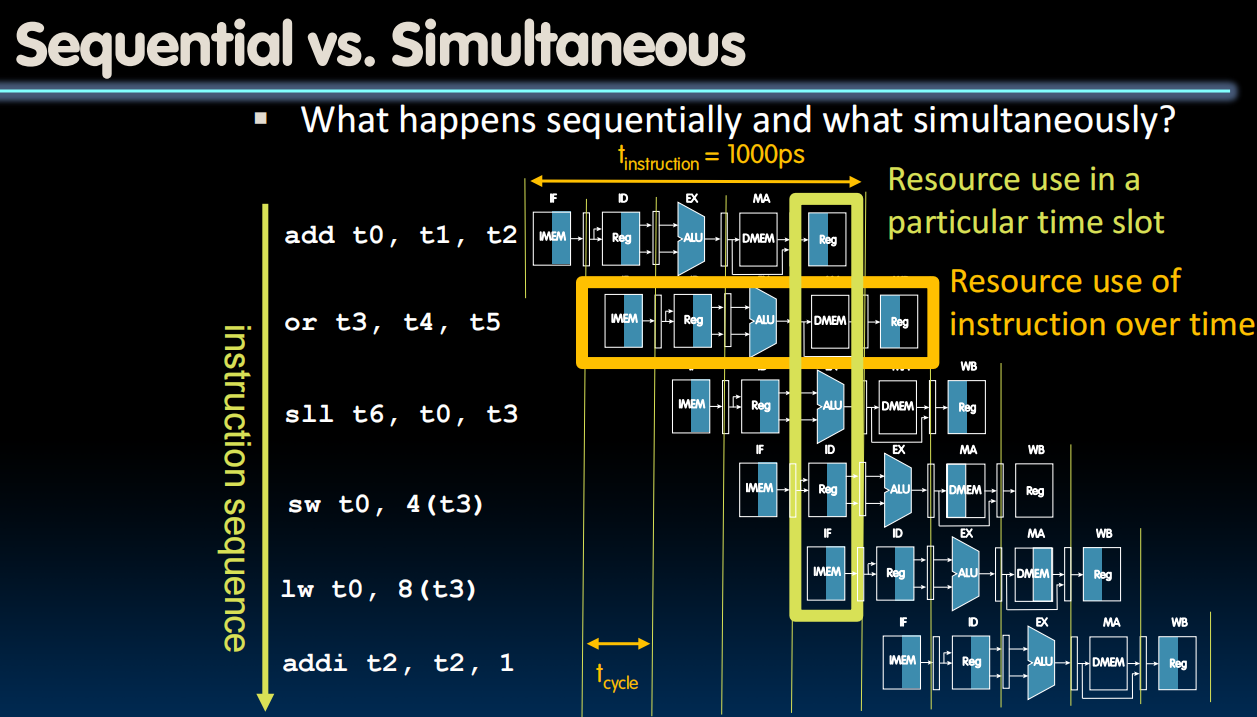
Pipelining Datapath
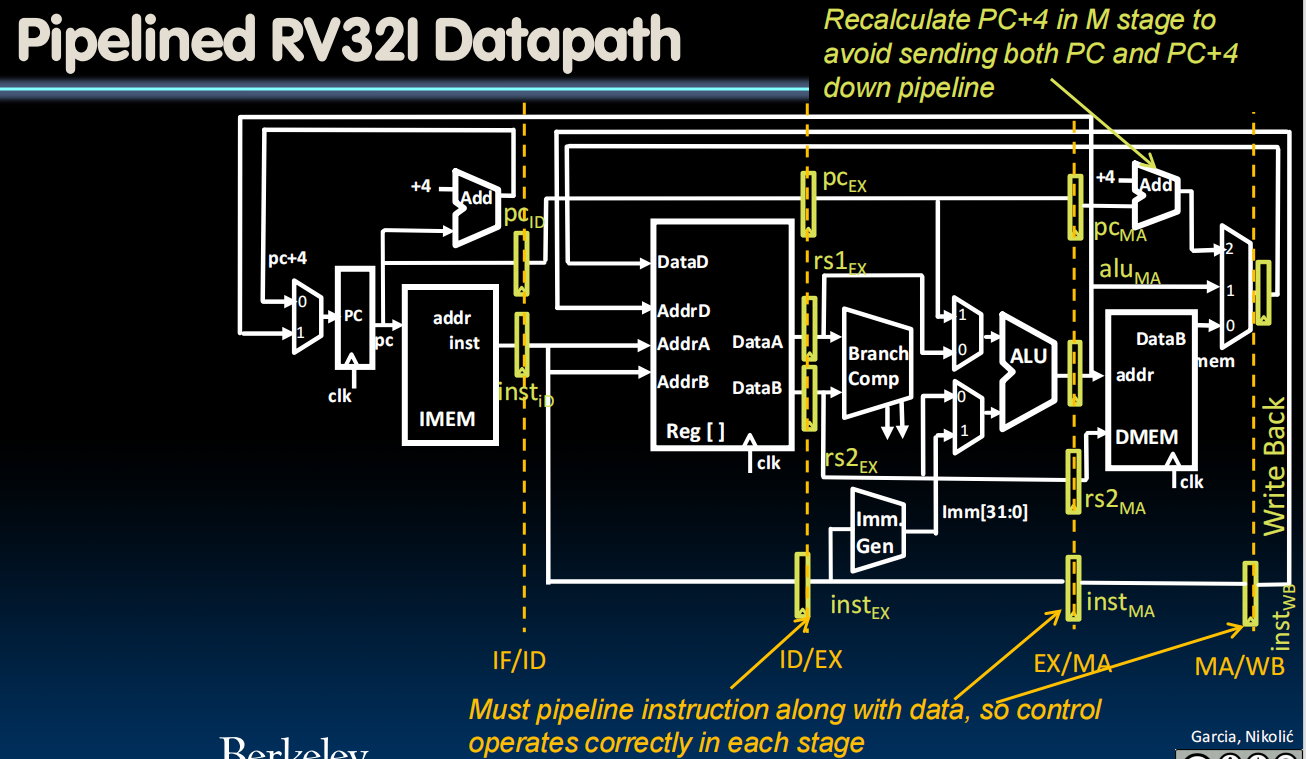
Insert registers at appropriate places on the boundary between each of these execution phases.
- Pipeline registers separate stages, hold data for each instruction in flight
- Pipelined Control
- Control signals derived from instruction
- As in single-cycle implementation
- Information is stored in pipeline registers for use by later stages
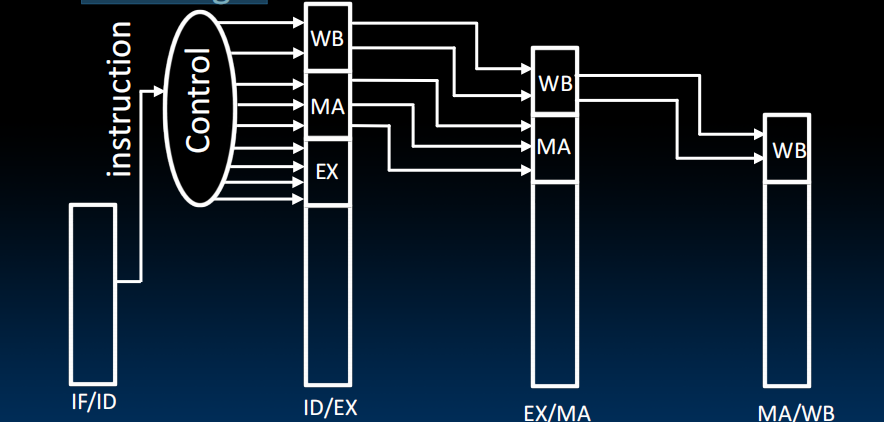
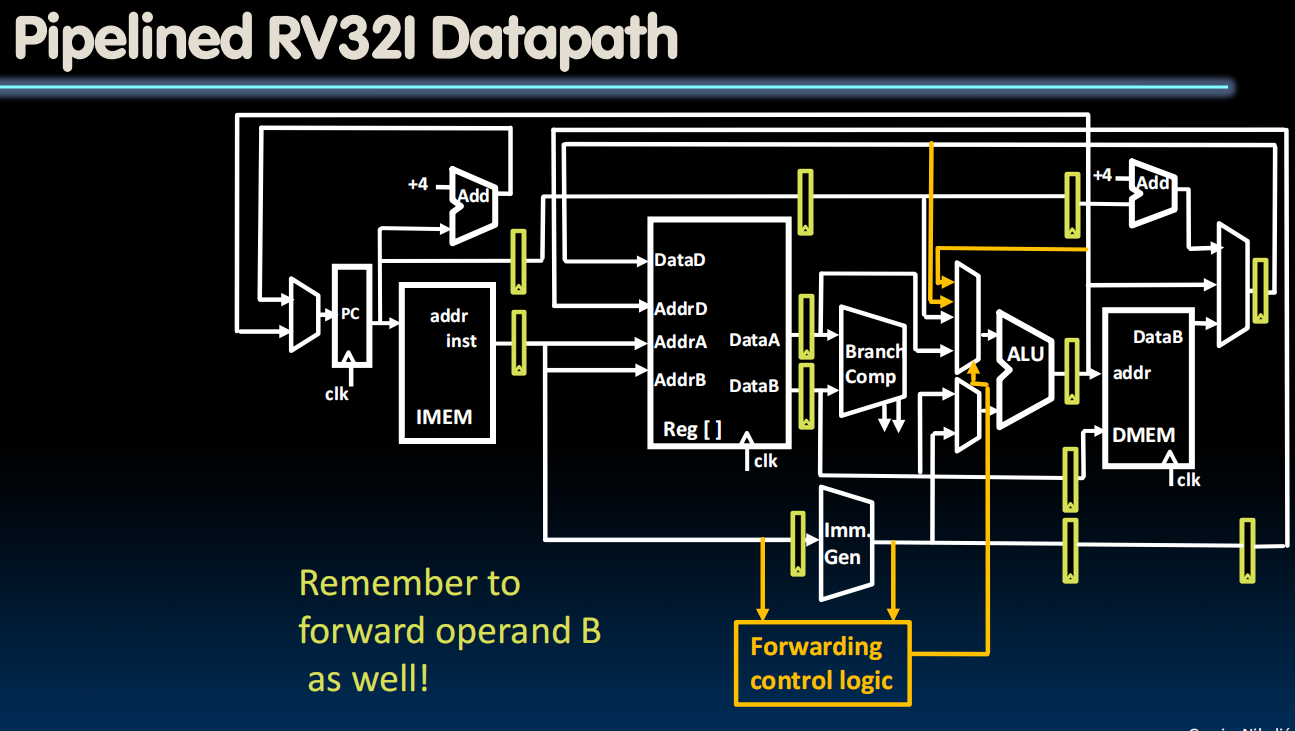
Once when we decode the instruction, we, in addition to our instruction, need to send down the stream all the control bits that correspond to that instruction.
So each of these registers that are storing the program counter are going to be a bit wider to save the necessary control signals. - Control signals derived from instruction
Pipeline Hazards
- A hazard is a situation that prevents starting the next instruction in the next clock cycle
- Structural hazard
- A required resource is busy (e.g. needed in multiple stages)
- Data hazard
- Data dependency between instructions
- Need to wait for previous instruction to complete its data read/write
- Control hazard
- Flow of execution depends on previous instruction
- Structural hazard
- Structural Hazard
- Problem: Two or more instructions in the pipeline compete for access to a single physical resource
- Solution 1: Instructions take it in turns to use resource, some instructions have to stall
- Solution 2: Add more hardware to machine
- (Can always solve a structural hazard by adding more hardware)
- Regfile Structural Hazards
- Each instruction:
- Can read up to two operands in decode stage
- Can write one value in writeback stage
- Avoid structural hazard by having separate “ports”
- Two independent read ports and one independent write port
- Three accesses per cycle can happen simultaneously
- Each instruction:
- Structural Hazard: Memory Access
- 区分IMEM和DMEM,是因为在pipeline中同一时期会有对内存的两种访问
- Instruction and Data Caches
- Fast, on-chip memory, separate for instructions and data
- Summary
- Conflict for use of a resource
- In RISC-V pipeline with a single memory
- Load/store requires data access
- Without separate memories, instruction fetch would have to stall for that cycle
- All other operations in pipeline would have to wait
- Pipelined datapaths require separate instruction/data memories
- Or separate instruction/data caches
- RISC ISAs (including RISC-V) designed to avoid structural hazards
- e.g. at most one memory access/instruction
Data Hazards
-
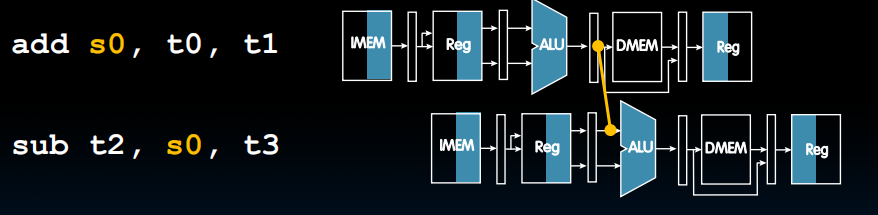
Separate ports, but what if write to same register as read?
Does sw in the example fetch the old or new value?
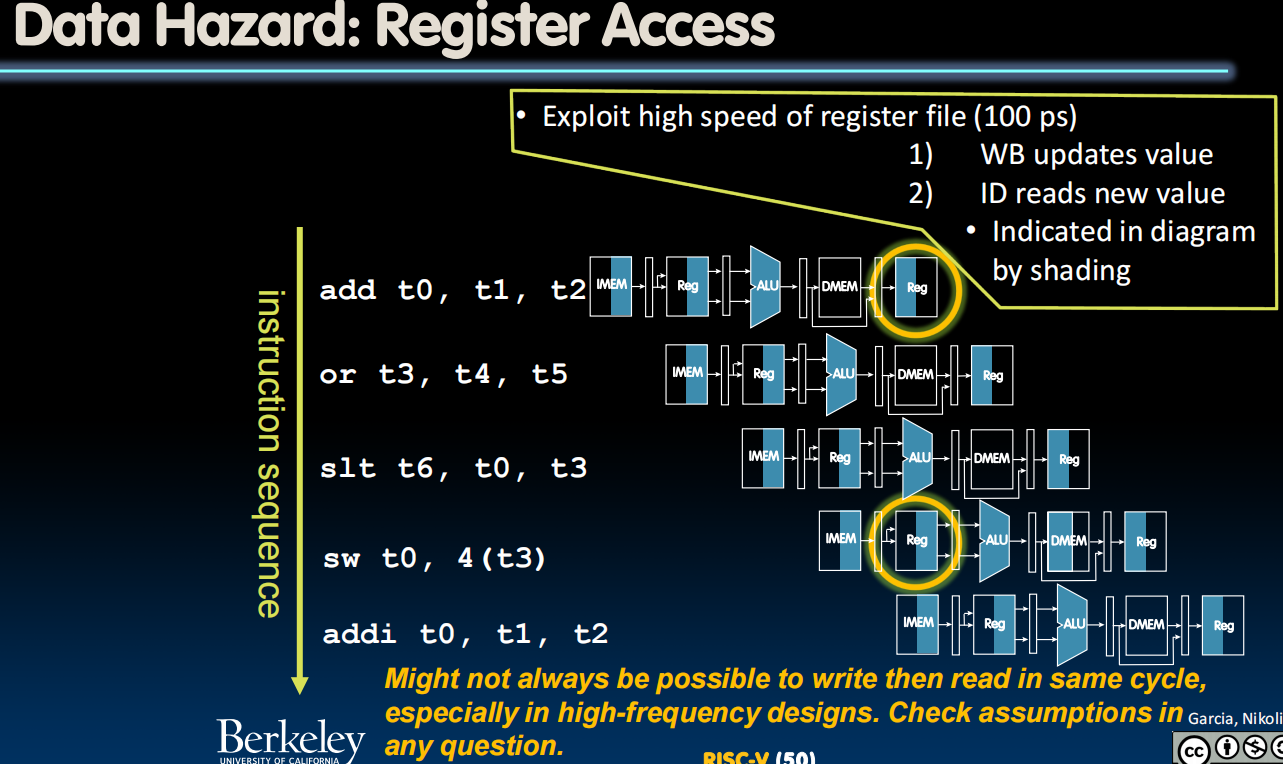
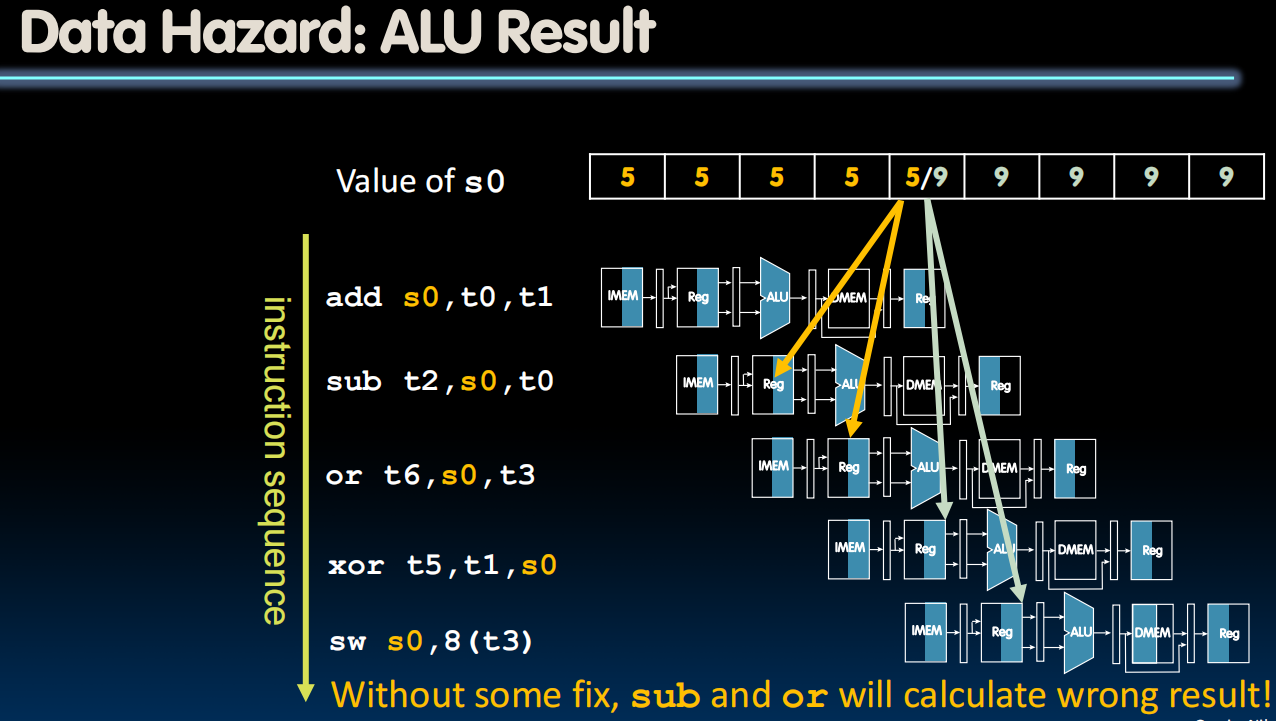
-
Solution
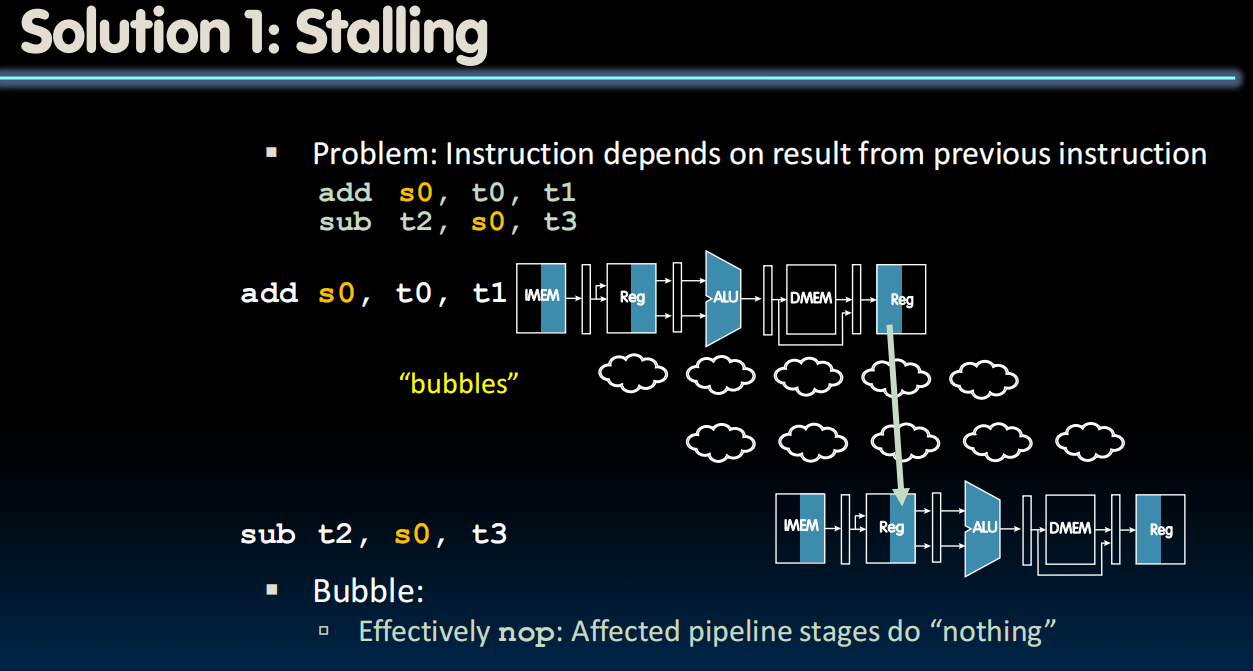
- Stalls reduce performance
- But stalls are required to get correct results
- Compiler can arrange code or insert nops(addi x0, x0, 0) to avoid hazards and stalls
- Requires knowledge of the pipeline structure
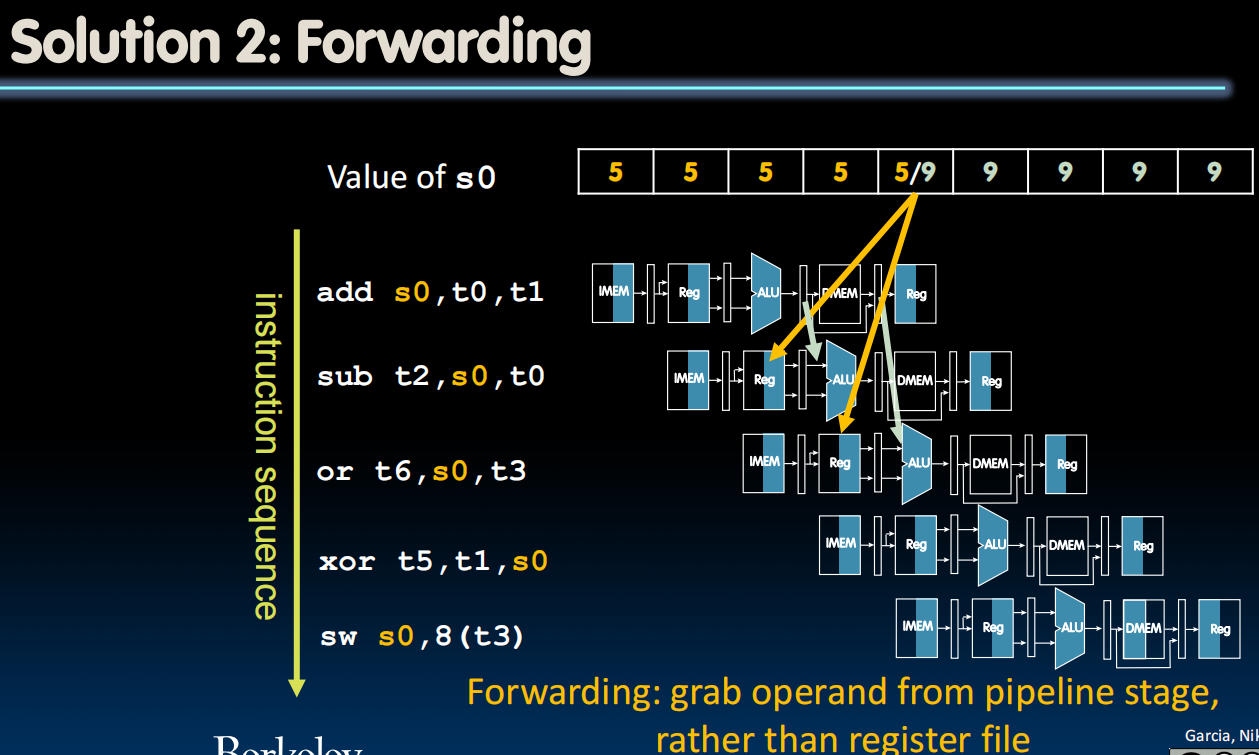
- Use result when it is computed
- Don’t wait for it to be stored in a register
- Requires extra connections in the datapath

- Stalls reduce performance
Lecture 23 (Pipelining 3)
Load Data Hazard
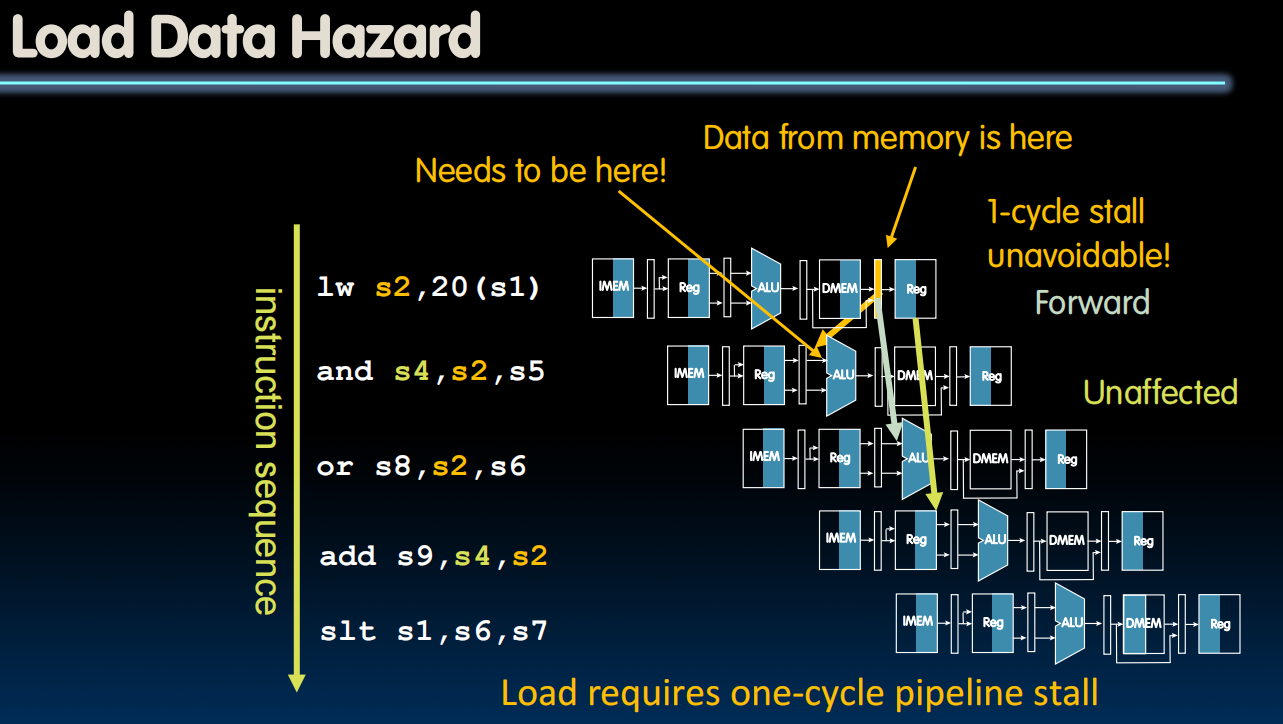
- We can only stall
- Slot after a load is called a load delay slot
- If that instruction uses the result of the load, then the hardware will stall for one cycle
- Equivalent to inserting an explicit nop in the slot
- except the latter uses more code space
- Performance loss
- Idea:
- Put unrelated instruction into load delay slot
- No performance loss!

Control Hazards
We won't know whether a branch is taken or not for two cycles after we fetch it.
We should not be executing the two following instructions. So we should have two stall cycles after every single branch in the pipeline. (not quite)
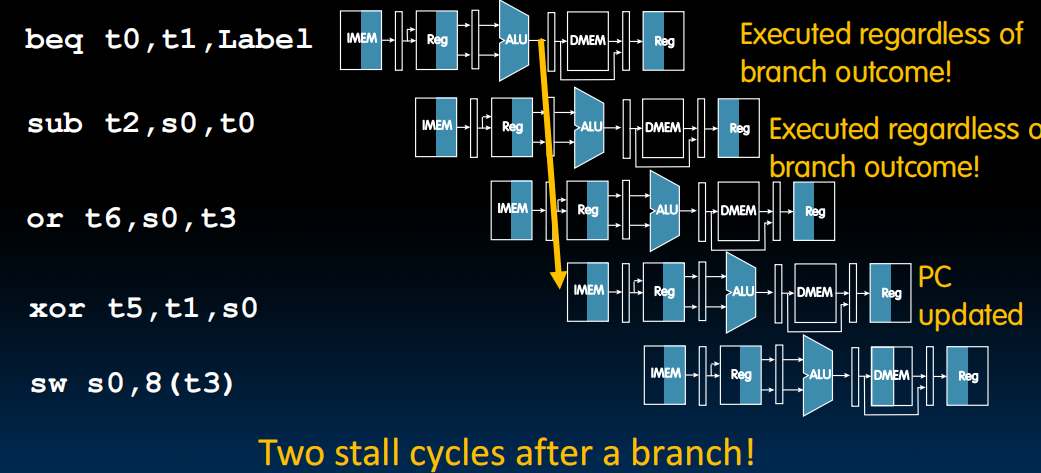
- If branch not taken, then instructions fetched sequentially after branch are correct
- If branch or jump taken, then need to flush incorrect instructions from pipeline by converting to NOPs

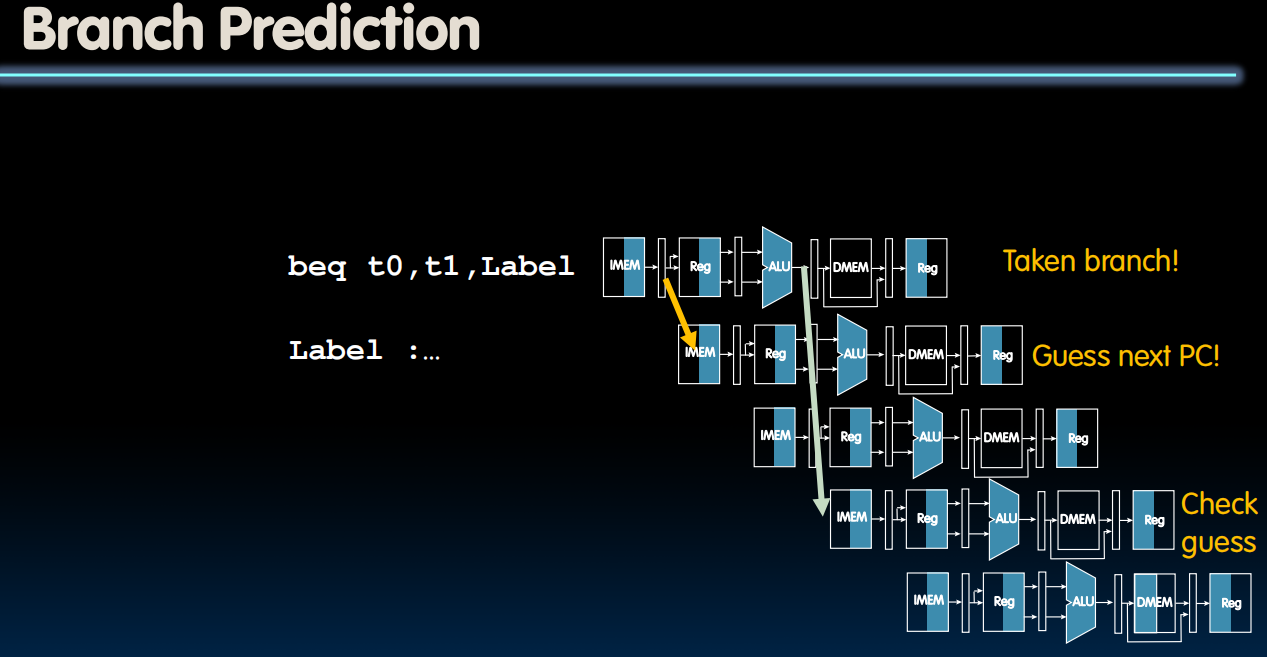
- Reducing Branch Penalties
- Every taken branch in simple pipeline costs 2 dead cycles
- To improve performance, use “branch prediction” to guess which way branch will go earlier in pipeline
- Only flush pipeline if branch prediction was incorrect
Superscalar Processors
-
Increasing Processor Performance
- Clock rate
- Limited by technology and power dissipation
- Pipelining
- “Overlap” instruction execution
- Deeper pipeline: 5 => 10 => 15 stages
- Less work per stage shorter clock cycle
- But more potential for hazards (CPI > 1)
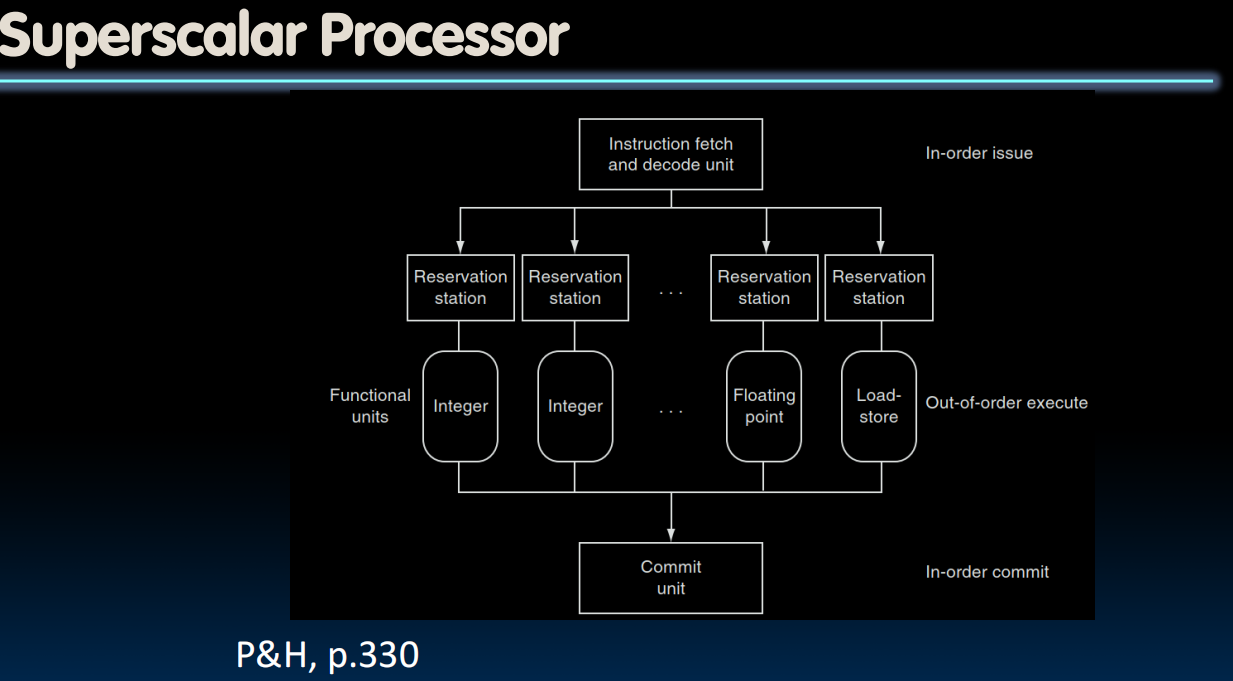
- Multi-issue “superscalar” processor
- Clock rate
-
Superscalar Processor
- Multiple issue “superscalar”
- Replicate pipeline stages ⇒ multiple pipelines
- Start multiple instructions per clock cycle
- CPI < 1, so use Instructions Per Cycle (IPC)
- E.g., 4GHz 4-way multiple-issue
- 16 BIPS, peak CPI = 0.25, peak IPC = 4
- Dependencies reduce this in practice
- “Out-of-Order” execution
- Reorder instructions dynamically in hardware to reduce impact of hazards
- (CS152 discusses these techniques!)
- Multiple issue “superscalar”
-
Pipelining and ISA Design
- RISC-V ISA designed for pipelining
- All instructions are 32-bits
- Easy to fetch and decode in one cycle
- Versus x86: 1- to 15-byte instructions
- Few and regular instruction formats
- Decode and read registers in one step
- Load/store addressing
- Calculate address in 3rd stage, access memory in 4th stage
- Alignment of memory operands
- Memory access takes only one cycle
- All instructions are 32-bits
- RISC-V ISA designed for pipelining
Conclusion

Lecture 24 (Caches 1)
Binary Prefix
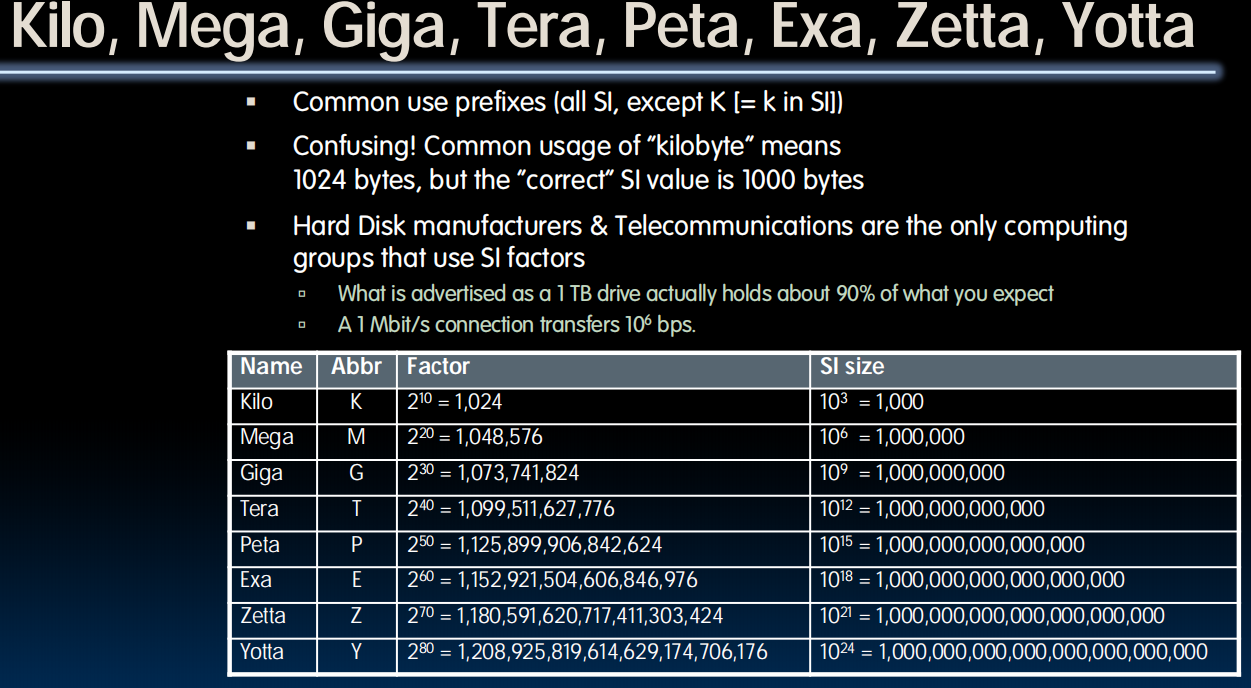

tricks to memorize

Library Analogy
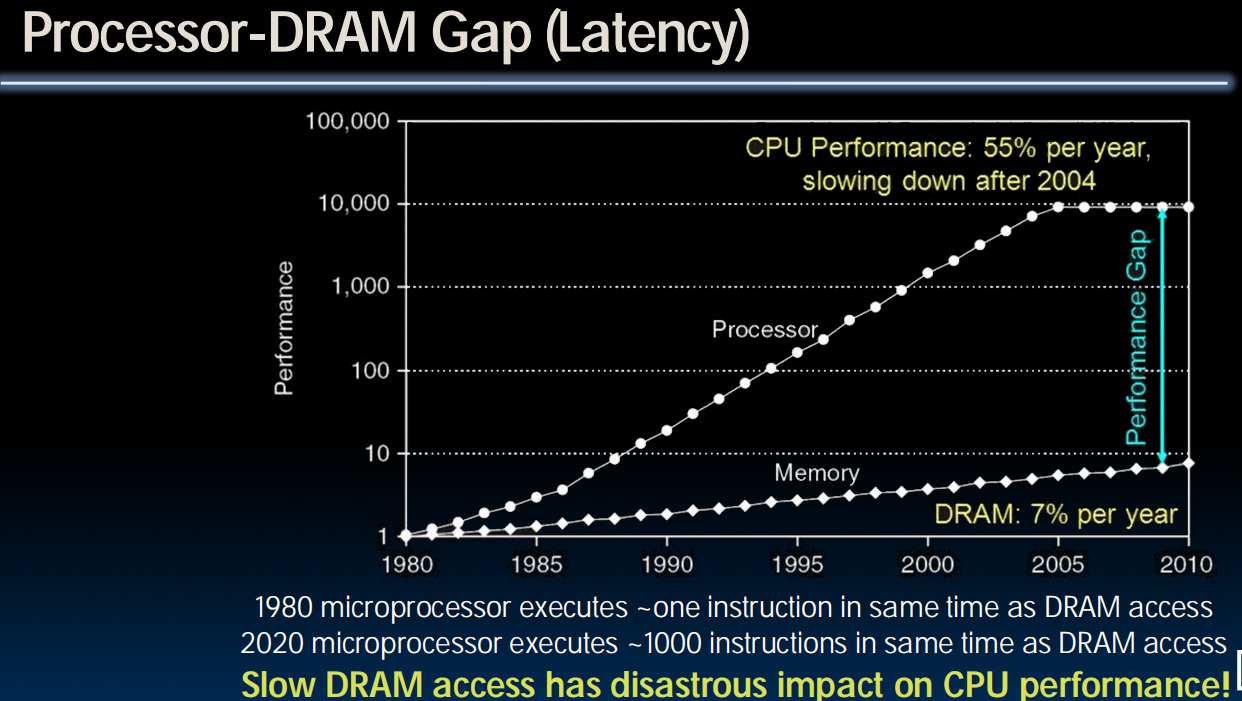
- Why are Large Memories Slow? Library Analogy
- Time to find a book in a large library
- Search a large card catalog – (mapping title/author to index number)
- Round-trip time to walk to the stacks and retrieve the desired book
- Larger libraries worsen both delays
- Electronic memories have same issue, plus the technologies used to store a bit slow down as density increases (e.g., SRAM vs. DRAM vs. Disk)
- Time to find a book in a large library
Memory Hierarchy
(What To Do: Library Analogy)
- Write a report using library books
- E.g., works of J.D. Salinger
- Go to library, look up books, fetch from stacks, and place on desk in library
- If need more, check out, keep on desk
- But don’t return earlier books since might need them
- You hope this collection of ~10 books on desk enough to write report, despite 10 being only 0.00001% of books in UC Berkeley libraries
Memory Caching
- Mismatch between processor and memory speeds leads us to add a new level…
- Introducing a “memory cache”
- Implemented with same IC processing technology as the CPU (usually integrated on same chip)
- faster but more expensive than DRAM memory.
- Cache is a copy of a subset of main memory
- Most processors have separate caches for instructions and data.
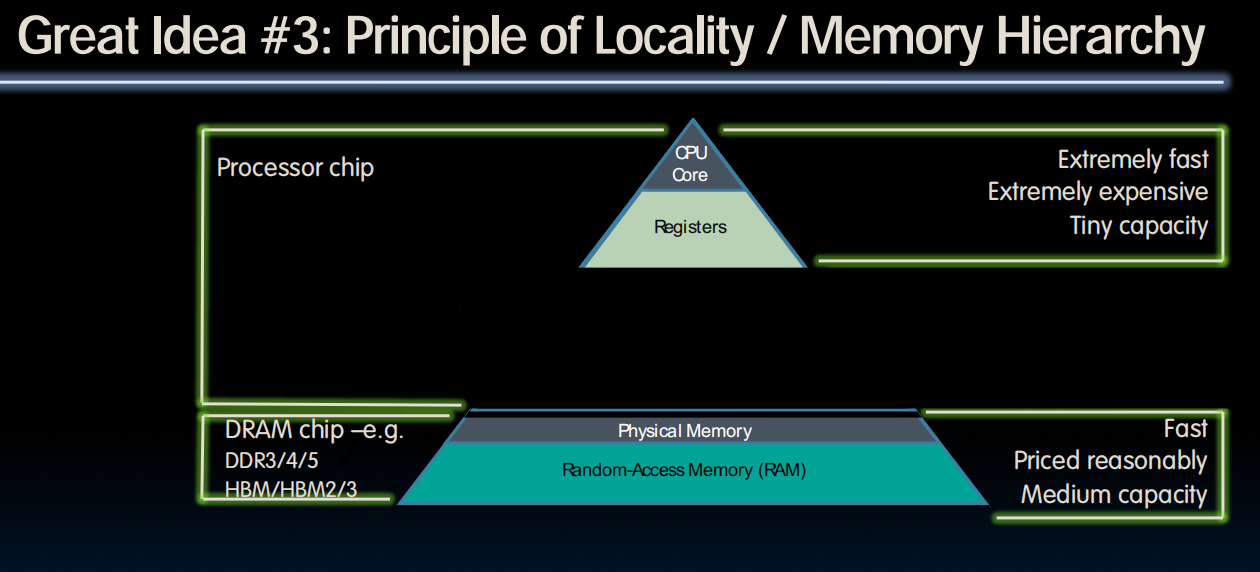
Cache is right under the Registers
Faster, Expensive, Small capacity
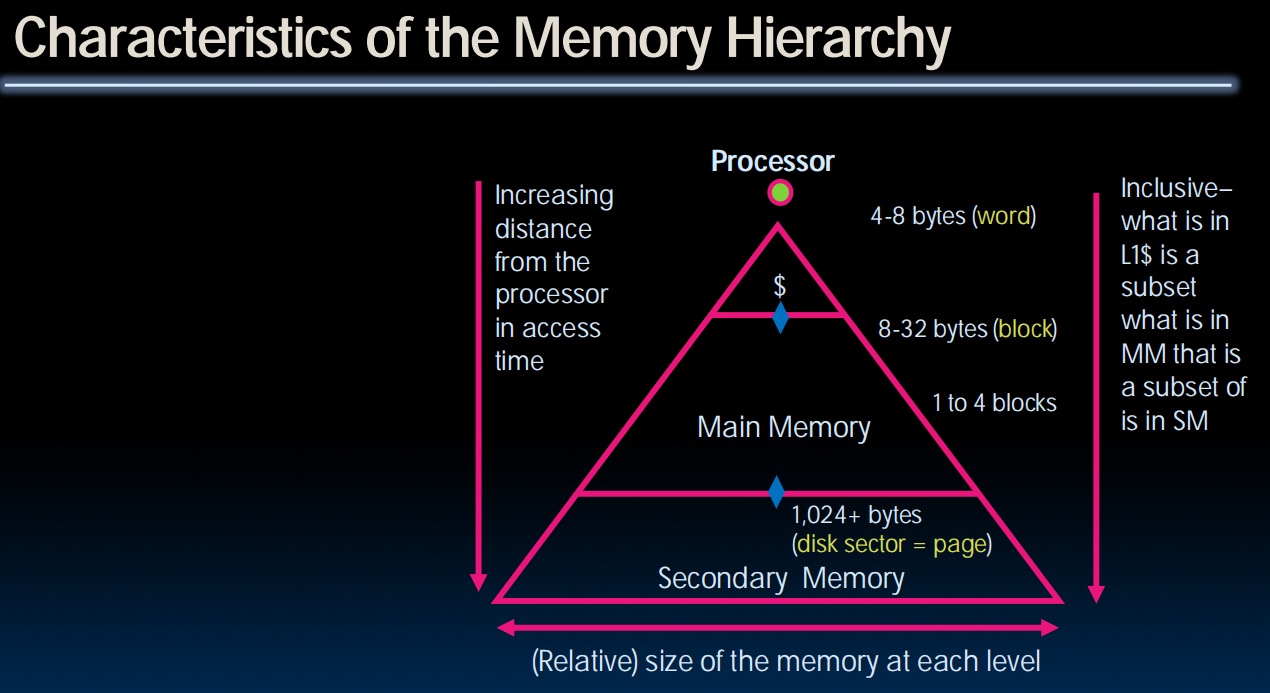

Memory Hierarchy
- If level closer to Processor, it is:
- Smaller
- Faster
- More expensive
- subset of lower levels (contains most recently used data)
- Lowest Level (usually disk=HDD/SSD) contains all available data (does it go beyond the disk?)
- Memory Hierarchy presents the processor with the illusion of a very large & fast memory
Locality, Design, Management
Memory Hierarchy Basis
- Cache contains copies of data in memory that are being used.
- Memory contains copies of data on disk that are being used.
- Caches work on the principles of temporal and spatial locality.
- Temporal locality (locality in time): If we use it now, chances are we’ll want to use it again soon.
- Spatial locality (locality in space): If we use a piece of memory, chances are we’ll use the neighboring pieces soon.
What to Do About Locality
- Temporal Locality
- If a memory location is referenced then it will tend to be referenced again soon
Keep most recently accessed data items closer to the processor
- If a memory location is referenced then it will tend to be referenced again soon
- Spatial Locality
- If a memory location is referenced, the locations with nearby addresses will tend to be referenced soon
Move blocks consisting of contiguous words closer to the processor
- If a memory location is referenced, the locations with nearby addresses will tend to be referenced soon
Cache Design
- How organize cache
- Where each memory address map to
(Remember that cache is subset of memory, so multiple memory addresses map to the same cache location.)
- Know which elements are in cache
- quickly locate them

Conclusion
- Caches provide an illusion to the processor that the memory is infinitely large and infinitely fast.
Lecture 25 (Caches 2)
Direct Mapped Caches
-
In a direct-mapped cache, each memory address is associated with one possible block within the cache (block的位置总是确定的,无需搜索)
- Therefore, we only need to look in a single location in the cache for the data if it exists in the cache
- Block is the unit of transfer between cache and memory
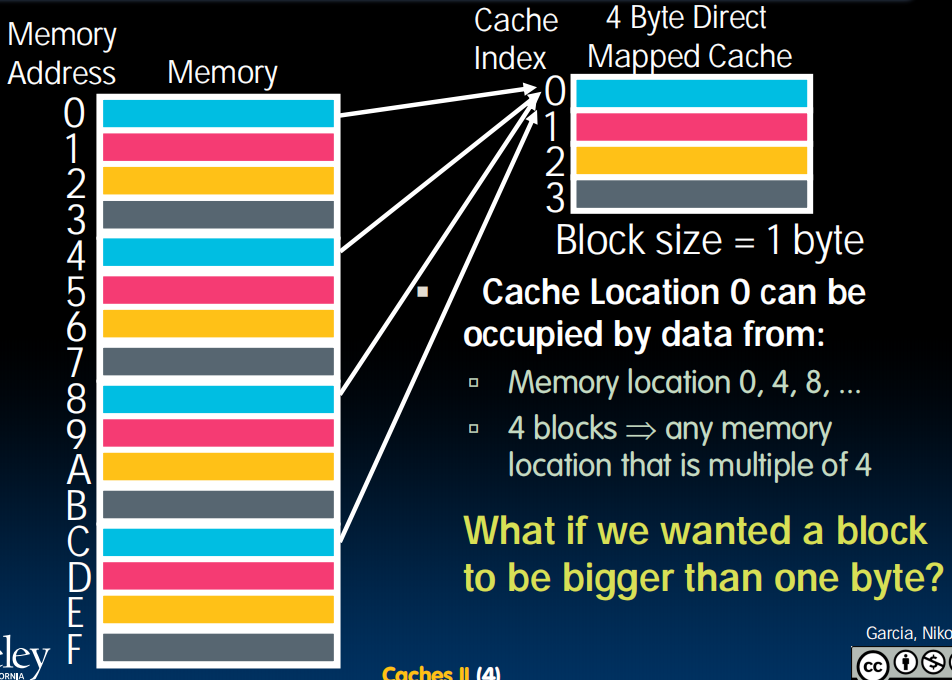
every 4 elements knows where should it go. 编码二进制的最后两位。
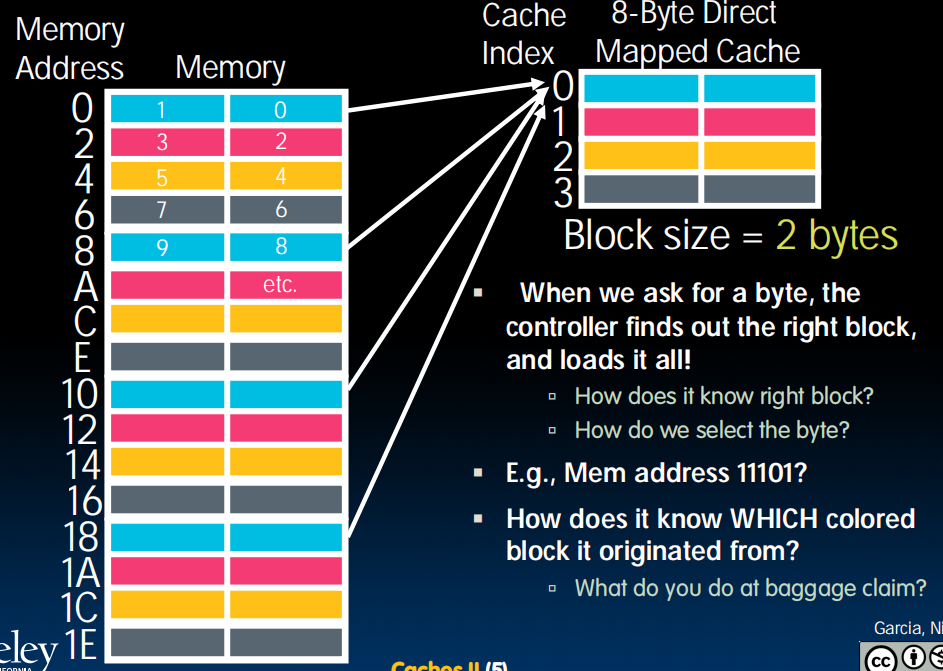
存在一个tag,包含了对应内存的地址。不需要二进制的最后三位 (已经由在cache的位置确定了) Cache Number。
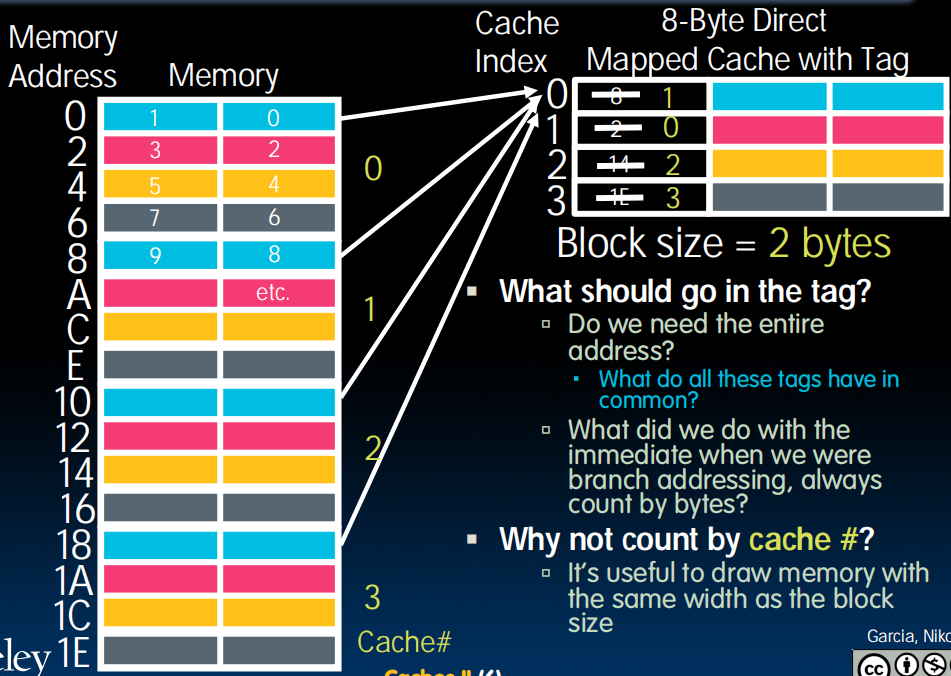
Issues with Direct-Mapped
- 通过内存地址的二进制,可以确定它对应缓存的位置以及Tag:

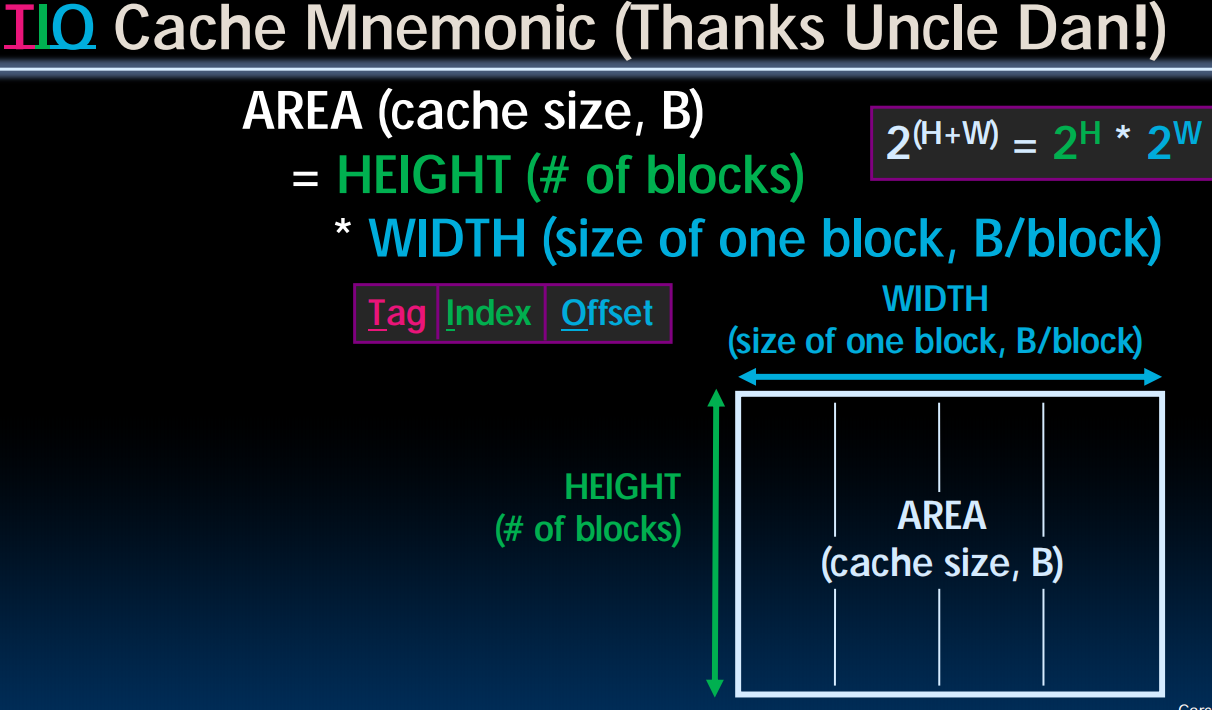
Direct-Mapped Cache Terminology
- All fields are read as unsigned integers.
- Index
- specifies the cache index (which “row”/block of the cache we should look in)
- Offset
- once we’ve found correct block, specifies which byte within the block we want
- Tag
- the remaining bits after offset and index are determined; these are used to distinguish between all the memory addresses that map to the same location
记忆小技巧:
Direct Mapped Example
- Suppose we have a 8B of data in a direct-mapped cache with 2-byte blocks
- Determine the size of the tag, index and offset fields if using a 32-bit arch (RV32)
- Offset
- need to specify correct byte within a block
- block contains 2 bytes
= bytes - need 1 bit to specify correct byte
- Index: (~index into an “array of blocks”)
- need to specify correct block in cache
- cache contains 8 B = 23 bytes
- block contains 2 B = 21 bytes
- # blocks/cache
- need 2 bits to specify this many blocks
- Tag: use remaining bits as tag
- tag length = addr length – offset - index
= 32 - 1 - 2 bits
= 29 bits - so tag is leftmost 29 bits of memory address
- Tag can be thought of as “cache number”
- tag length = addr length – offset - index
- Why not full 32-bit address as tag?
- All bytes within block need same address
- Index must be same for every address within a block, so it’s redundant in tag check, thus can leave off to save memory
Memory Access without Cache
- Load word instruction: lw t0, 0(t1)
- t1 contains , Memory[1022] = 99
- Processor issues address to Memory
- Memory reads word at address
- Memory sends 99 to Processor
- Processor loads 99 into register t0
Memory Access with Cache
- Load word instruction: lw t0, 0(t1)
- t1 contains , Memory[1022] = 99
- With cache (similar to a hash)
- Processor issues address to Cache
- Cache checks to see if has copy of data at address
2a. If finds a match (Hit): cache reads 99, sends to processor
2b. No match (Miss): cache sends address 1022 to Memory
1. Memory reads 99 at address
2. Memory sends 99 to Cache
3. Cache replaces word with new 99
4. Cache sends 99 to processor - Processor loads 99 into register t0
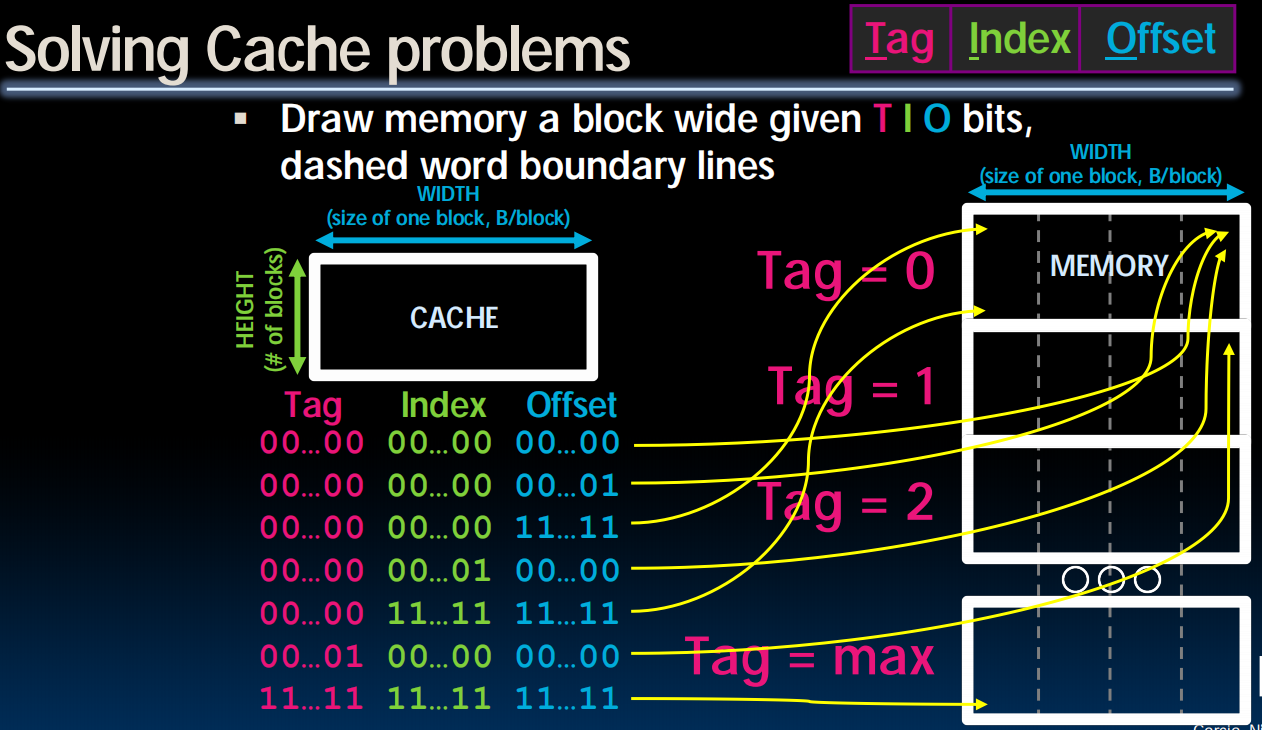
从右上角开始
Cache Terminology
- When reading memory, 3 things can happen:
cache hit:- cache block is valid and contains proper address, so read desired word
cache miss:- nothing in cache in appropriate block, so fetch from memory
cache miss, block replacement:- wrong data is in cache at appropriate block, so discard it and fetch desired data from memory (cache always copy)
Cache Temperatures
- Cold
- Cache empty
- Warming
- Cache filling with values you'll hopefully be accessing again soon
- Warm
- Cache is doing its job, fair % of hits
- Hot
- Cache is doing very well, high % of hits
Cache Terms
Hit rate:fraction of access that hit in the cacheMiss rate:1 – Hit rateMiss penalty:time to replace a block from lower level in memory hierarchy to cacheHit time:time to access cache memory (including tag comparison)- Abbreviation: "$" = cache
Valid Bit (One More Detail)
- When start a new program, cache does not have valid information for this program
- Need an indicator whether this tag entry is valid for this program
- Add a “valid bit” to the cache tag entry
0 cache miss, even if by chance, address = tag
1 cache hit, if processor address = tag

Conclusion
- We have learned the operation of a direct-mapped cache
- Mechanism for transparent movement of data among levels of a memory hierarchy
- set of address/value bindings
- address index to set of candidates
- compare desired address with tag
- service hit or miss
- load new block and binding on miss
Lecture 26 (Caches 3)
Direct Mapped Example
图片太多就不放了。。。
- Index -> Valid -> (Load data if Valid is 0) -> Tag -> (Load data if Tag don't match) -> Offset -> return
如果dirty bit被设置,在替换block时需要把内容重写入memory。
Writes, Block, Sizes, Misses
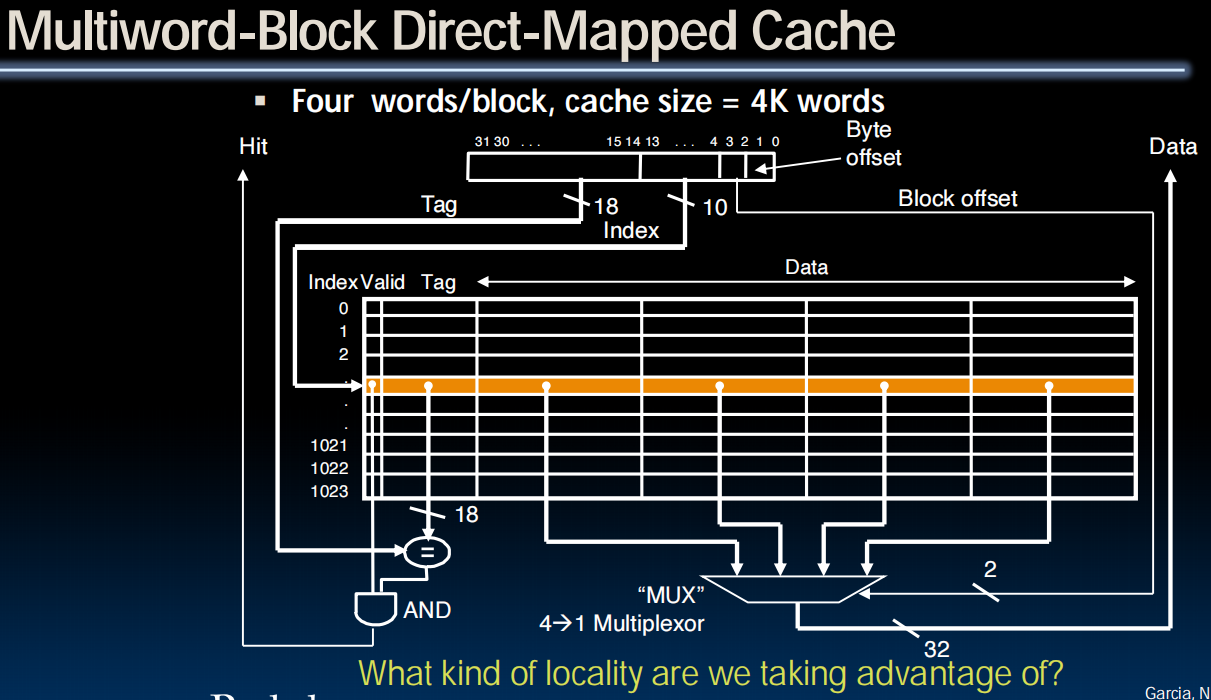
4个bytes都被装进mux,由offset决定读取哪个。
几个check的步骤同时发生。
What to do on a write hit
- Write-through (保存cache和memory同步)
- Update both cache and memory
- Write-back (只对cache更新)
- update word in cache block
- allow memory word to be “stale”
- add ‘dirty’ bit to block
- memory & Cache inconsistent
- needs to be updated when block is replaced
- …OS flushes cache before I/O…
Block Size Tradeoff
-
Benefits of Larger Block Size
- Spatial Locality: if we access a given word, we’re likely to access other nearby words soon
- Very applicable with Stored-Program Concept
- Works well for sequential array accesses
-
Drawbacks of Larger Block Size
- Larger block size means larger miss penalty
- on a miss, takes longer time to load a new block from next level
- on a miss, takes longer time to load a new block from next level
- Larger block size means larger miss penalty
- If block size is too big relative to cache size, then there are too few blocks
- Result: miss rate goes up
Extreme Example: One Big Block

Block Size Tradeoff Conclusions
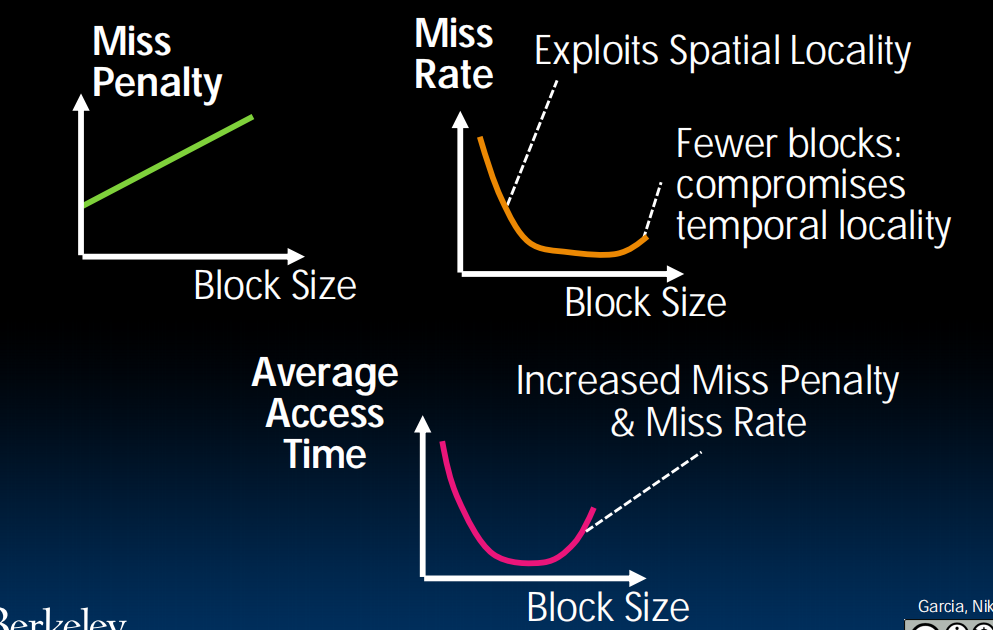
Types of Cache Misses
- “Three Cs” Model of Misses
- 1st C: Compulsory Misses
- occur when a program is first started
- cache does not contain any of that program’s data yet, so misses are bound to occur
- can’t be avoided easily, so won’t focus on these in this course
- Every block of memory will have one compulsory
miss (NOT only every block of the cache)
- 2nd C: Conflict Misses
- miss that occurs because two distinct memory addresses map to the same cache location
- two blocks (which happen to map to the same location) can keep overwriting each other
- big problem in direct-mapped caches
- how do we lessen the effect of these?
- Dealing with Conflict Misses
-
Solution 1: Make the cache size bigger
- Fails at some point
-
Solution 2: Multiple distinct blocks can fit in the same cache Index?
-
Fully Associative Caches
- Memory address fields:
- Tag: same as before
- Offset: same as before
- Index: non-existant (需要与所有的tag比较)
- What does this mean?
- no “rows”: any block can go anywhere in the cache
- must compare with all tags in entire cache to see if data is there
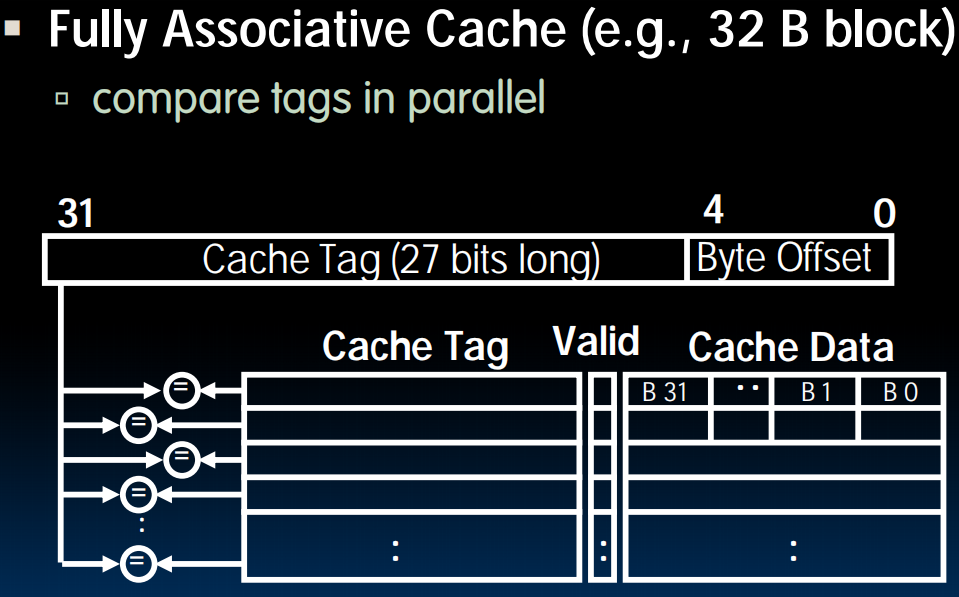
- Benefit of Fully Assoc Cache
- No Conflict Misses (since data can go anywhere)
- Drawbacks of Fully Assoc Cache
- Need hardware comparator for every single entry: if we have a 64KB of data in cache with 4B entries, we need 16K comparators: infeasible
Final Type of Cache Miss
- 3rd C: Capacity Misses
- miss that occurs because the cache has a limited size
- miss that would not occur if we increase the size of the cache
- sketchy definition, so just get the general idea
- This is the primary type of miss for Fully Associative caches.
How to categorize misses
- Run an address trace against a set of caches:
- First, consider an infinite-size, fully-associative cache. For every miss that occurs now, consider it a compulsory miss.
- Next, consider a finite-sized cache (of the size you want to examine) with full-associativity. Every miss that is not in #1 is a capacity miss.
- Finally, consider a finite-size cache with finite-associativity. All of the remaining misses that are not #1 or #2 are conflict misses.
Conclusion

Lecture 27 (Cache 4)
Set-Associative Caches

N-Way Set Associative Cache
- Memory address fields:
- Tag
- Offset: same as before
- Index: points us to the correct “row” (called a set in this case)
- each set contains multiple blocks
- once we’ve found correct set, must compare with all tags in that set to find our data
- Size of $ is # sets x N blocks/set x block size
- cache is direct-mapped w/respect to sets
- each set is fully associative with N blocks in it
- Find correct set using Index value.
- Compare Tag with all Tag values in that set.
- If a match occurs, hit!, otherwise a miss.
- Finally, use the offset field as usual to find the desired data within the block.
- even a 2-way set assoc cache avoids a lot of conflict misses
- hardware cost isn’t that bad: only need N comparators
- it’s Direct-Mapped if it’s 1-way set assoc
- it’s Fully Assoc if it’s M-way set assoc
- so these two are just special cases of the more general set associative design
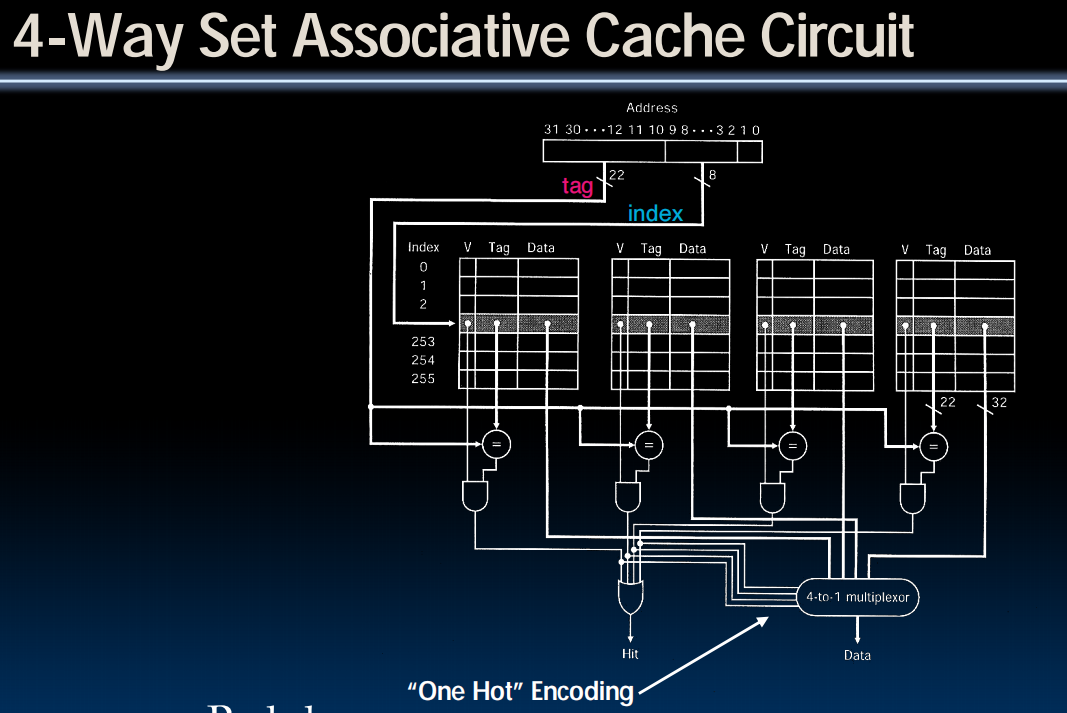
一行是一个set,mux决定采用哪个data
Block Replacement with Example
Block Replacement Policy
-
Direct-Mapped Cache
- index completely specifies position which position a block can go in on a miss
-
N-Way Set Assoc
- index specifies a set, but block can occupy any position within the set on a miss
-
Fully Associative
- block can be written into any position
-
Question: if we have the choice, where should we write an incoming block?
- If there’s a valid bit off, write new block into first invalid.
- If all are valid, pick a replacement policy
- rule for which block gets “cached out” on a miss.
-
LRU (Least Recently Used)
- Idea: cache out block which has been accessed (read or write) least recently
- Pro: temporal locality recent past use implies likely future use: in fact, this is a very effective policy
- Con: with 2-way set assoc, easy to keep track (one LRU bit); with 4-way or greater, requires complicated hardware and much time to keep track of this
-
FIFO
- Idea: ignores accesses, just tracks initial order
-
Random
- If low temporal locality of workload, works ok


Average Memory Access Time (AMAT)
Big Idea
- How to choose between associativity, block size, replacement & write policy?
- Design against a performance model
- Minimize: Average Memory Access Time
= Hit Time + Miss Penalty x Miss Rate即使miss了,在从memory取回element后也要再取出,还是有Hit time,所以这里的计算不用乘 Hit rate。
- influenced by technology & program behavior
- Minimize: Average Memory Access Time
- Create the illusion of a memory that is large, cheap, and fast - on average
- How can we improve miss penalty?
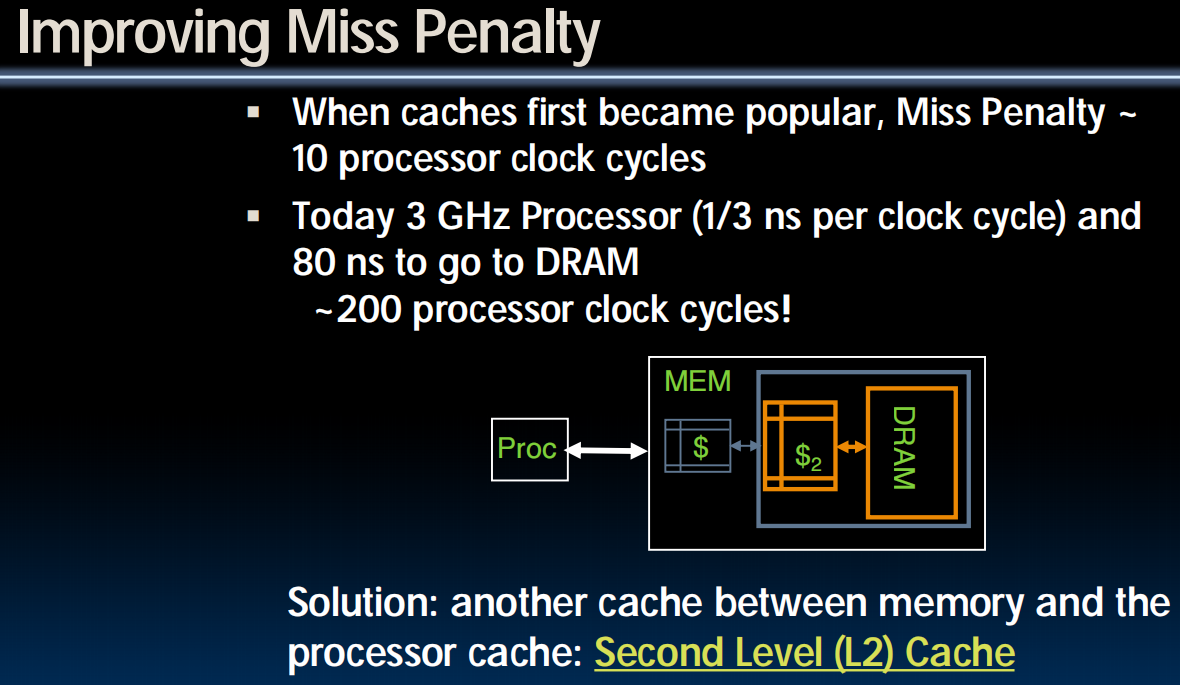
Analyzing Multi-level cache hierarchy
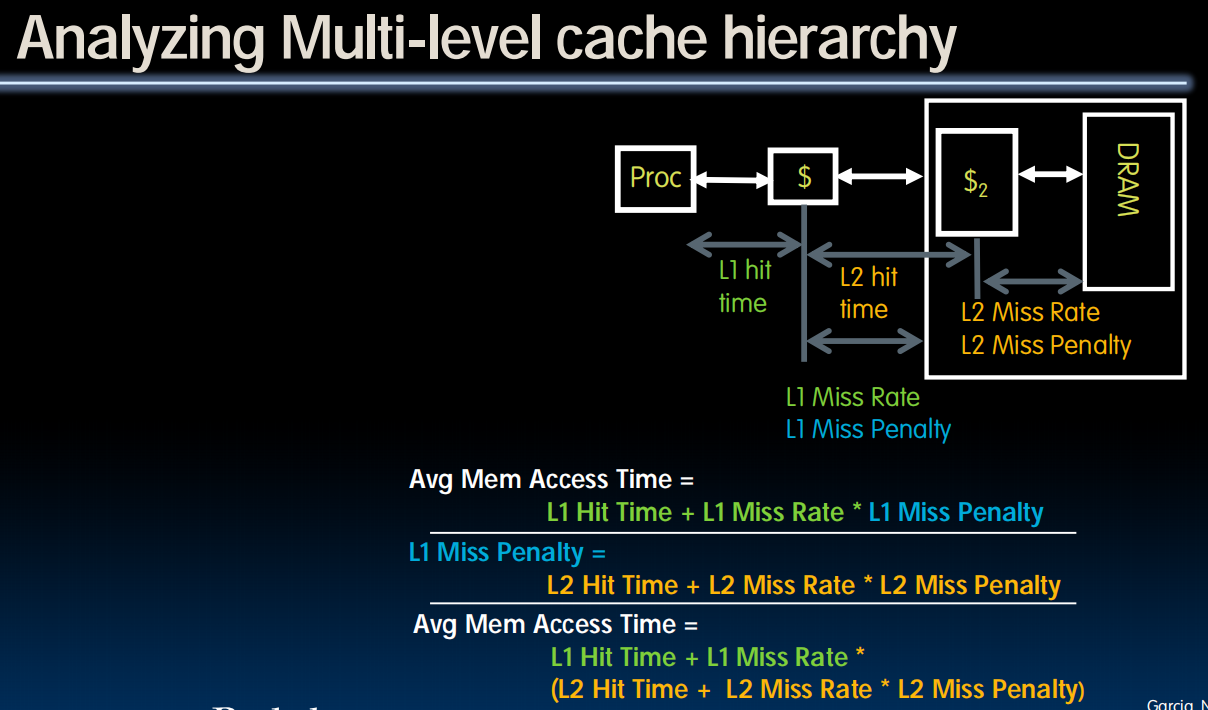
- Example
- Assume
- Hit Time = 1 cycle
- Miss rate = 5%
- Miss penalty = 20 cycles
- Calculate AMAT
- Avg mem access time
cycles
cycles
- Assume
Ways to reduce miss rate
- Larger cache
- limited by cost and technology
- hit time of first level cache < cycle time (bigger caches are slower)
- More places in the cache to put each block of memory – associativity
- fully-associative
- any block any line
- N-way set associated
- N places for each block
- direct map: N=1
- fully-associative
Typical Scale
- L1:
- size: tens of KB
- hit time: complete in one clock cycle
- miss rates: 1-5%
- L2:
- size: hundreds of KB
- hit time: few clock cycles
- miss rates: 10-20%
- L2 miss rate is fraction of L1 misses that also miss in L2
- why so high? (L1 holds all good stuffs)
Example


Actual CPUs
- Early PowerPC
- Pentium M
- Intel core i7
Conclusion

Lecture 28 (OS & Virtual Memory Intro)
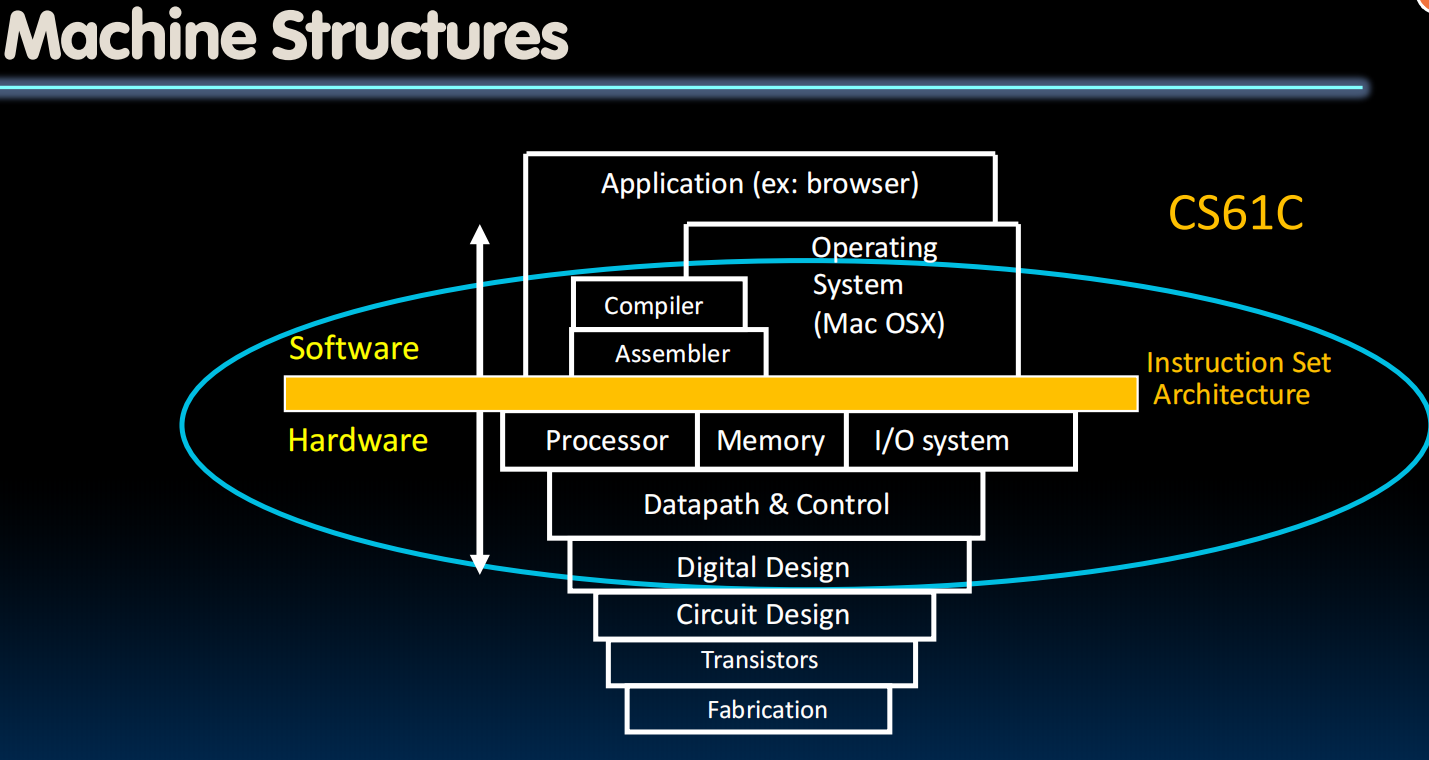
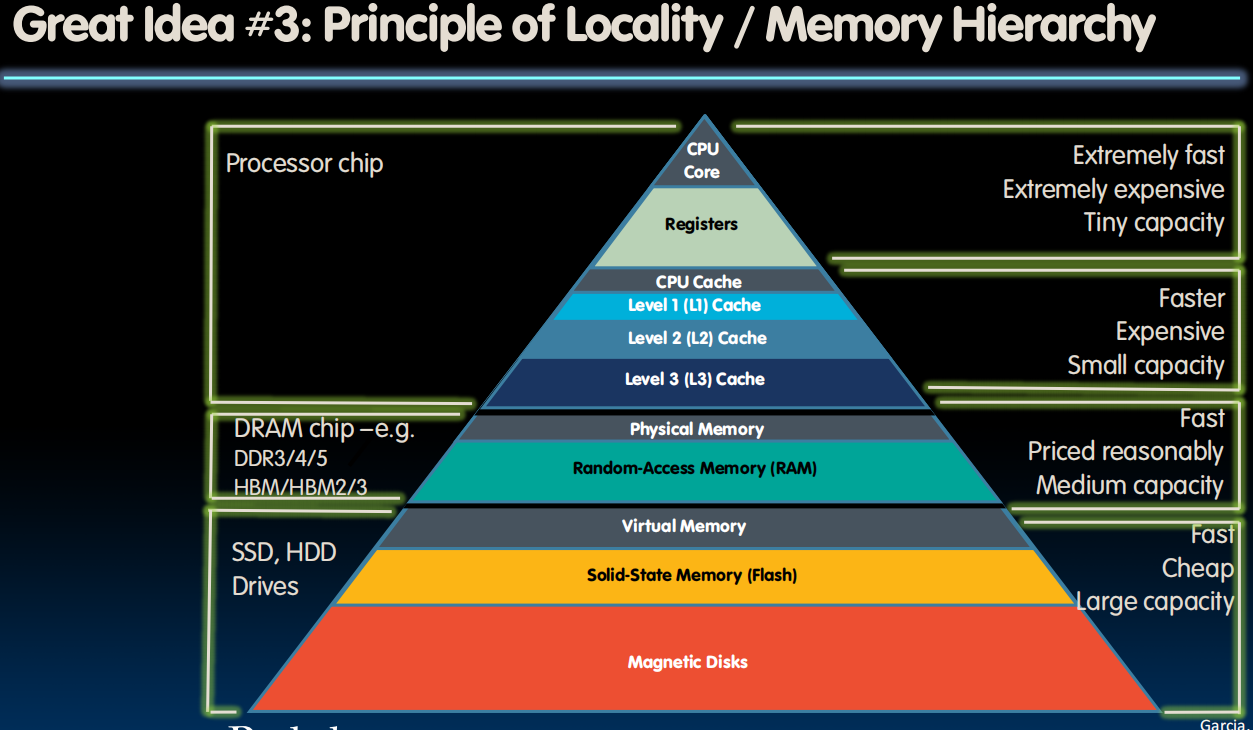
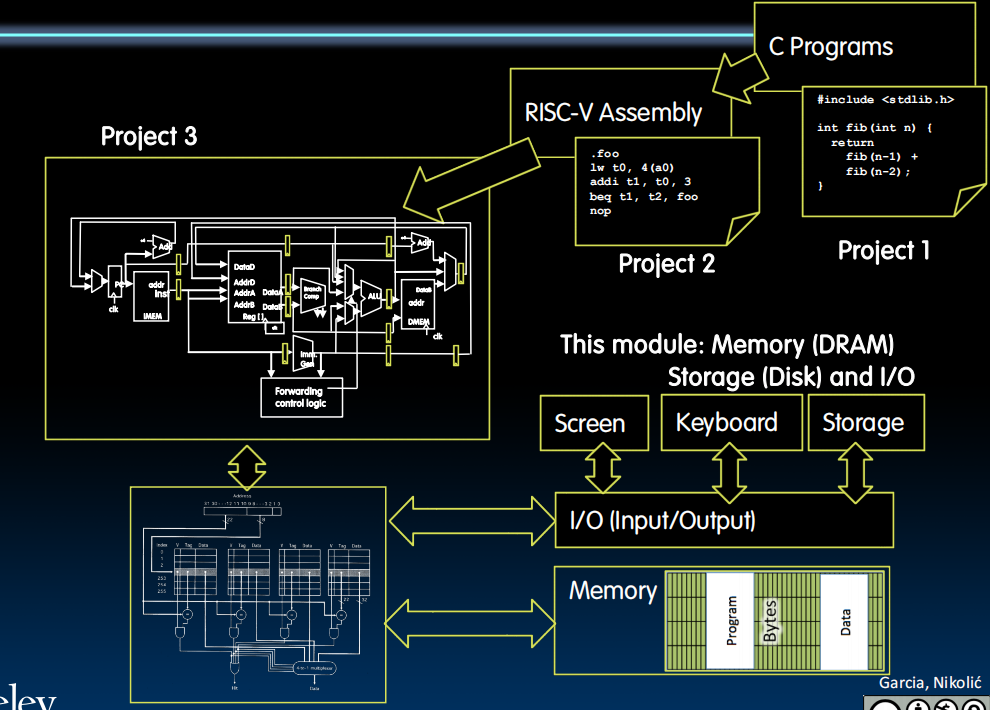
Operating System Basics
What Does the OS do?
- OS is the (first) thing that runs when computer starts
- Finds and controls all devices in the machine in a general way
- Relying on hardware specific “device drivers”
- Starts services (100+)
- File system,
- Network stack (Ethernet, WiFi, Bluetooth, …),
- TTY (keyboard),
- ...
- Loads, runs and manages programs:
- Multiple programs at the same time (time-sharing)
- Isolate programs from each other (isolation)
- Multiplex resources between applications (e.g., devices)
What Does the Core of the OS Do?
- Provide isolation between running processes
- Each program runs in its own little world •
- Provide interaction with the outside world
- Interact with "devices": Disk, display, network, etc... 11
What Does OS Need from Hardware?
- Memory translation (不同的进程可以使用相同的虚拟地址,映射到不同的物理地址)
- Each running process has a mapping from "virtual" to "physical" addresses that are different for each process
- When you do a load or a store, the program issues a virtual address... But the actual memory accessed is a physical address
- Protection and privilege
- Split the processor into at least two running modes: "User" and "Supervisor"
- RISC-V also has "Machine" below "Supervisor"
- Lesser privilege can not change its memory mapping
- But "Supervisor" can change the mapping for any given program
- And supervisor has its own set of mapping of virtual->physical
- Split the processor into at least two running modes: "User" and "Supervisor"
- Traps & Interrupts
- A way of going into Supervisor mode on demand
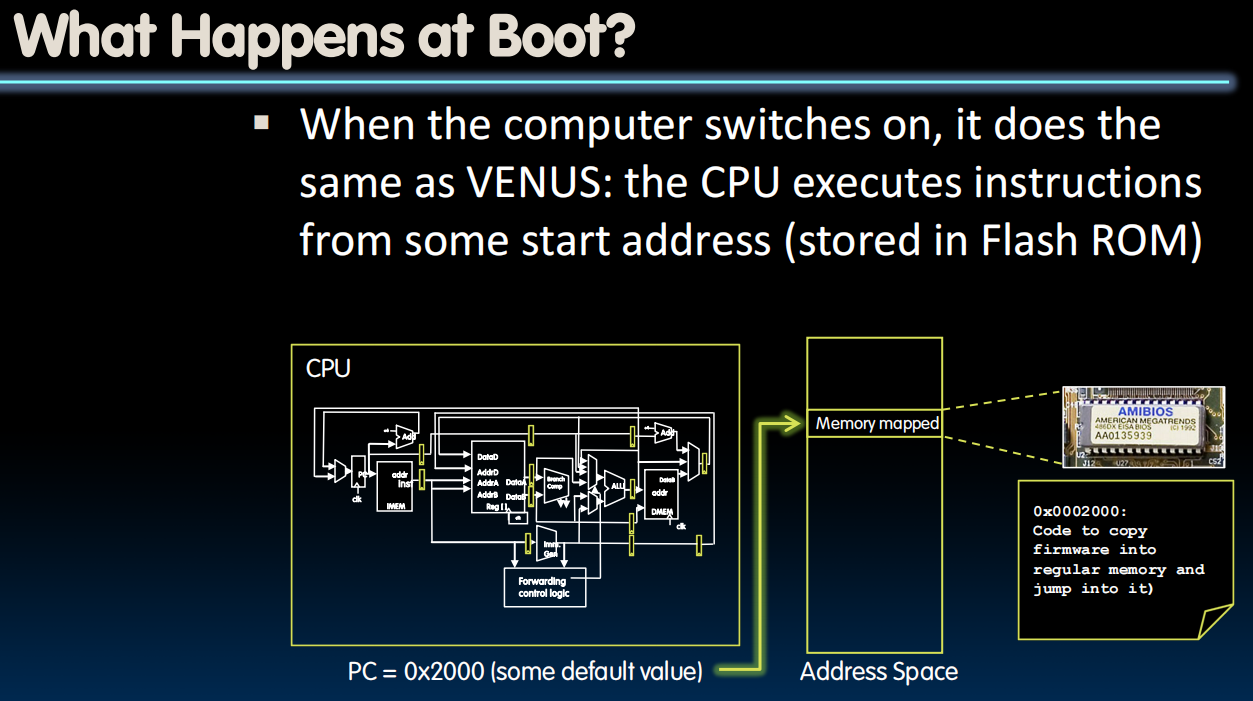
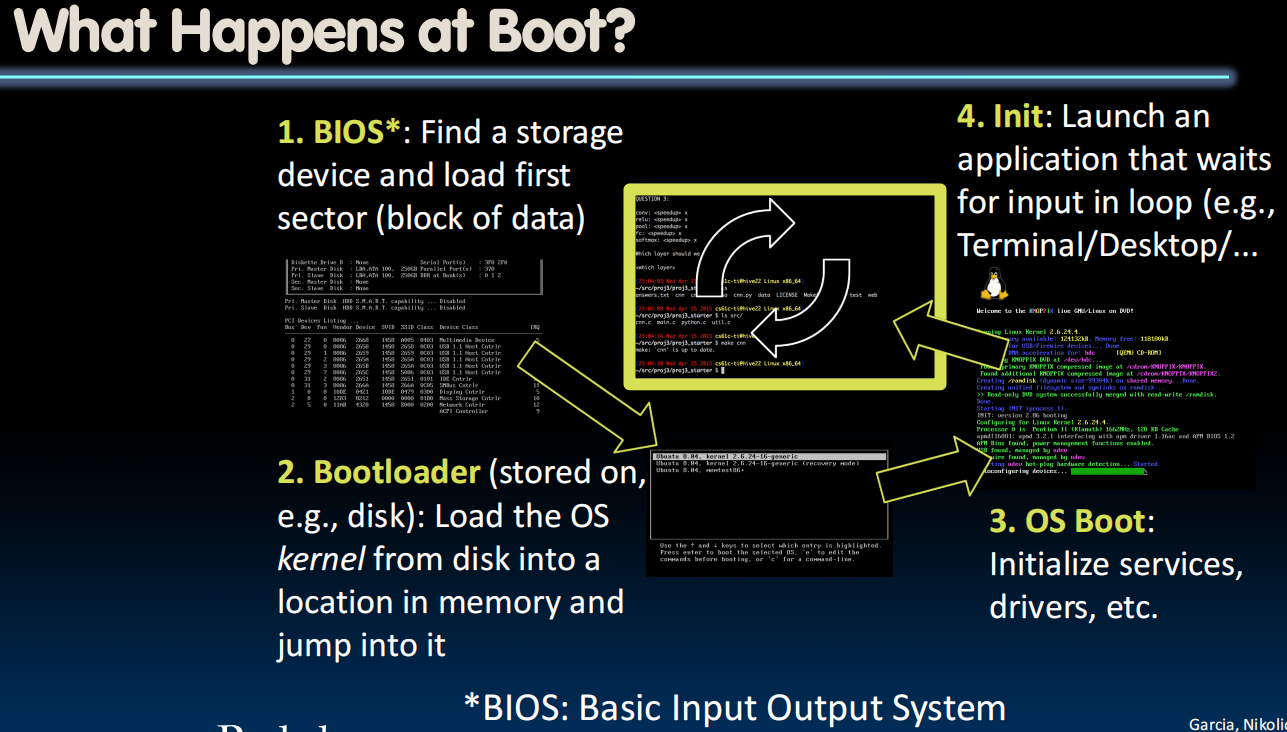
What Happens at Boot?
Operating System Functions
Launching Applications
- Applications are called “processes” in most OSs
- Thread: shared memory
- Process: separate memory
- Both threads and processes run (pseudo) simultaneously
- Apps are started by another process (e.g., shell) calling an OS routine (using a “syscall”)
- Depends on OS; Linux uses fork to create a new process, and execve (execute file command) to load application
- Loads executable file from disk (using the file system service) and puts instructions & data into memory (.text, .data sections), prepares stack and heap
- Set argc and argv, jump to start of main
- Shell waits for main to return (join)
Supervisor Mode
- If something goes wrong in an application, it could crash the entire machine. And what about malware, etc.?
- The OS enforces resource constraints to applications (e.g., access to memory, devices)
- To help protect the OS from the application, CPUs have a supervisor mode (e.g., set by a status bit in a special register)
- A process can only access a subset of instructions and (physical) memory when not in supervisor mode (user mode)
- Process can change out of supervisor mode using a special instruction, but not into it directly – only using an interrupt
- Supervisory mode is a bit like “superuser”
- But used much more sparingly (most of OS code does not run in supervisory mode)
- Errors in supervisory mode often catastrophic (blue “screen of death”, or “I just corrupted your disk”)
Syscalls
- What if we want to call an OS routine? E.g.,
- to read a file,
- launch a new process,
- ask for more memory (malloc),
- send data, etc.
- Need to perform a syscall:
- Set up function arguments in registers,
- Raise software interrupt (with special assembly instruction)
- OS will (接管并) perform the operation and return to user mode
- This way, the OS can mediate access to all resources, and devices
Interrupts, Exceptions
- We need to transition into Supervisor mode when "something" happens
Interrupt: Something external to the running program- Something happens from the outside world
Exception: Something (internal) done by the running program- Accessing memory it isn't "supposed" to, executing an illegal instruction, reading a csr not supposed at that privilege
- ECALL: Trigger an exception to the higher privilege
- How you communicate with the operating system: Used to implement "syscalls"
- EBREAK: Trigger an exception within the current privilege
Terminology (In 61C)
Interrupt– caused by an event external to current running program- E.g., key press, disk I/O
- Asynchronous to current program
- Can handle interrupt on any convenient instruction
- “Whenever it’s convenient, just don’t wait too long”
Exception– caused by some event during execution of one instruction of current running program- E.g., memory error, bus error, illegal instruction, raised exception
- Synchronous
- Must handle exception precisely on instruction that causes exception
- “Drop whatever you are doing and act now”
Trap– action of servicing interrupt or exception by hardware jump to “interrupt or trap handler” code
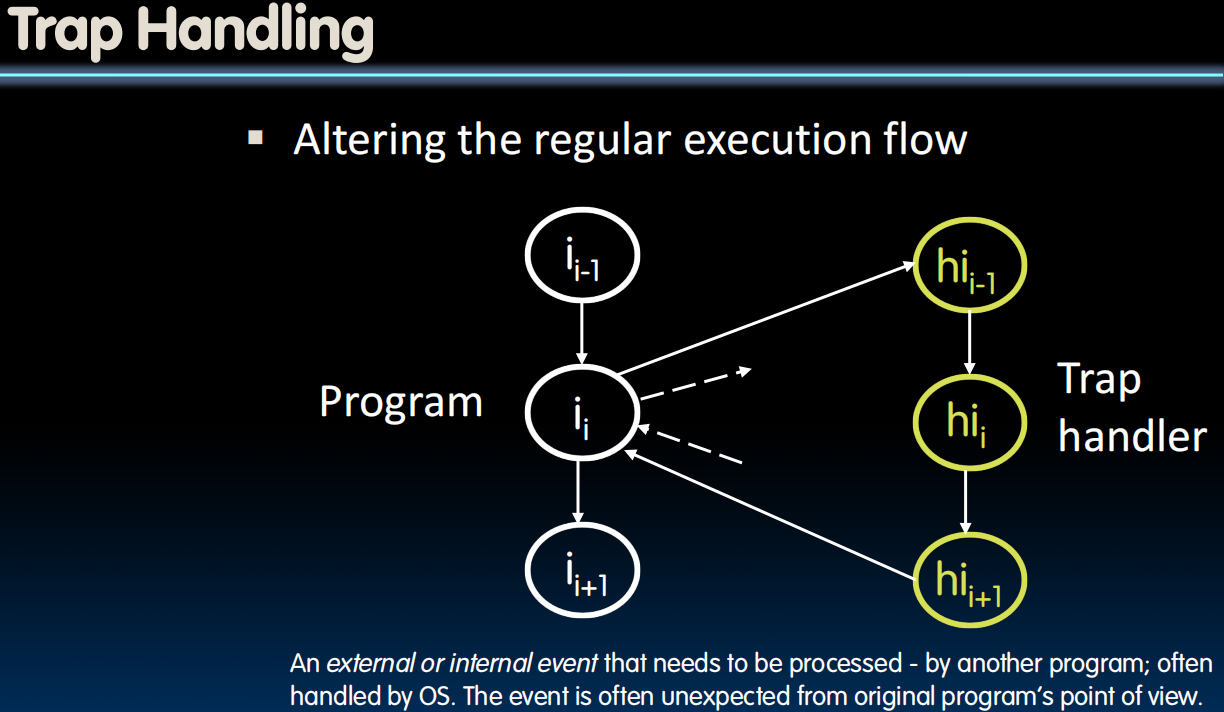
Precise Traps
- Trap handler’s view of machine state is that every instruction prior to the trapped one (e.g., memory error) has completed, and no instruction after the trap has executed.
- Implies that handler can return from an interrupt by restoring user registers and jumping back to interrupted instruction
- Interrupt handler software doesn’t need to understand the pipeline of the machine, or what program was doing!
- More complex to handle trap caused by an exception than interrupt
- Providing precise traps is tricky in a pipelined uperscalar out-of-order processor!
- But a requirement for things to actually work right!
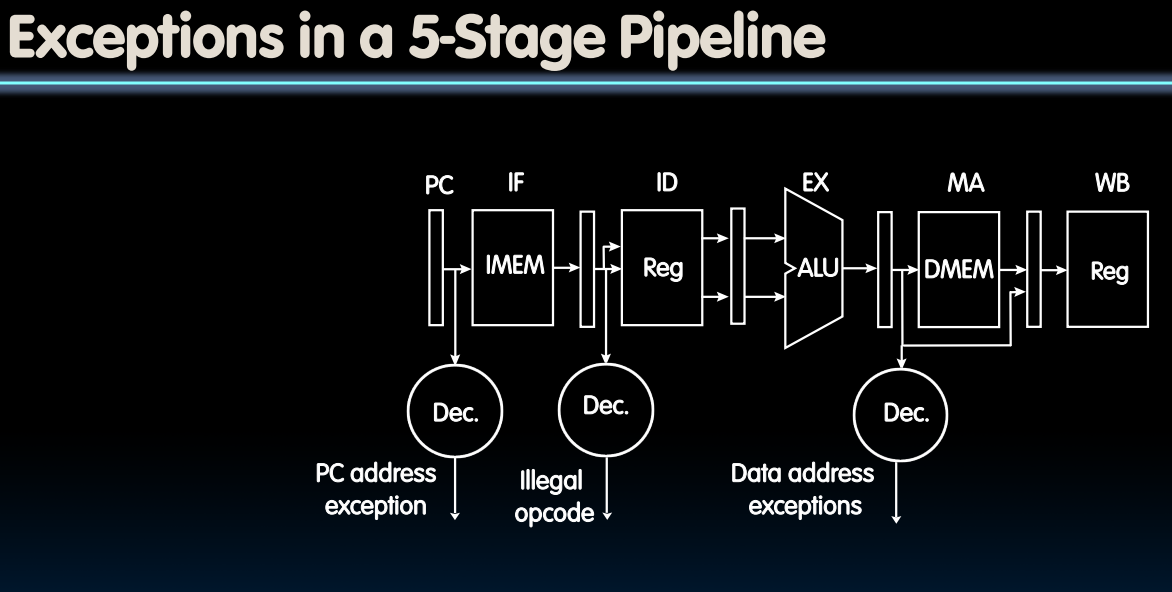
Trap Handling
- Exceptions are handled like pipeline hazards
- Complete execution of instructions before exception occurred
- Flush instructions currently in pipeline (i.e., convert to nops or “bubbles”)
- Optionally store exception cause in status register
- Indicate type of exception
- Transfer execution to trap handler
- Optionally, return to original program and re-execute instruction
Multiprogramming
- The OS runs multiple applications at the same time
- But not really (unless you have a core per process)
- Switches between processes very quickly (on human time scale) – this is called a “context switch”
- When jumping into process, set timer (we will call this ‘interrupt’)
- When it expires, store PC, registers, etc. (process state)
- Pick a different process to run and load its state
- Set timer, change to user mode, jump to the new PC
- Deciding what process to run is called scheduling
Protection, Translation, Paging
- Supervisor mode alone is not sufficient to fully isolate applications from each other or from the OS
- Application could overwrite another application’s memory.
- Typically programs start at some fixed address, e.g. 0x8FFFFFFF
- How can 100’s of programs share memory at location 0x8FFFFFFF?
- Also, may want to address more memory than we actually have (e.g., for sparse data structures)
- Solution: Virtual Memory
- Gives each process the illusion of a full memory address space that it has completely for itself
Lecture 29 (Virtual Memory 1)
Virtual Memory Concepts
Virtual Memory
- Virtual memory - Next level in the memory hierarchy:
- Provides program with illusion of a very large main memory: Working set of “pages” reside in main memory - others are on disk
- Demand paging: Provides the ability to run programs larger than the primary memory (DRAM) (我们可以使用disk作为扩展的DRAM)
- Hides differences between machine configurations
- Also allows OS to share memory, protect programs from each other (every process is its own world and the OS is there to orchestrate that)
- Today, more important for protection than just another level of memory hierarchy
- Each process thinks it has all the memory to itself
- (Historically, it predates caches)
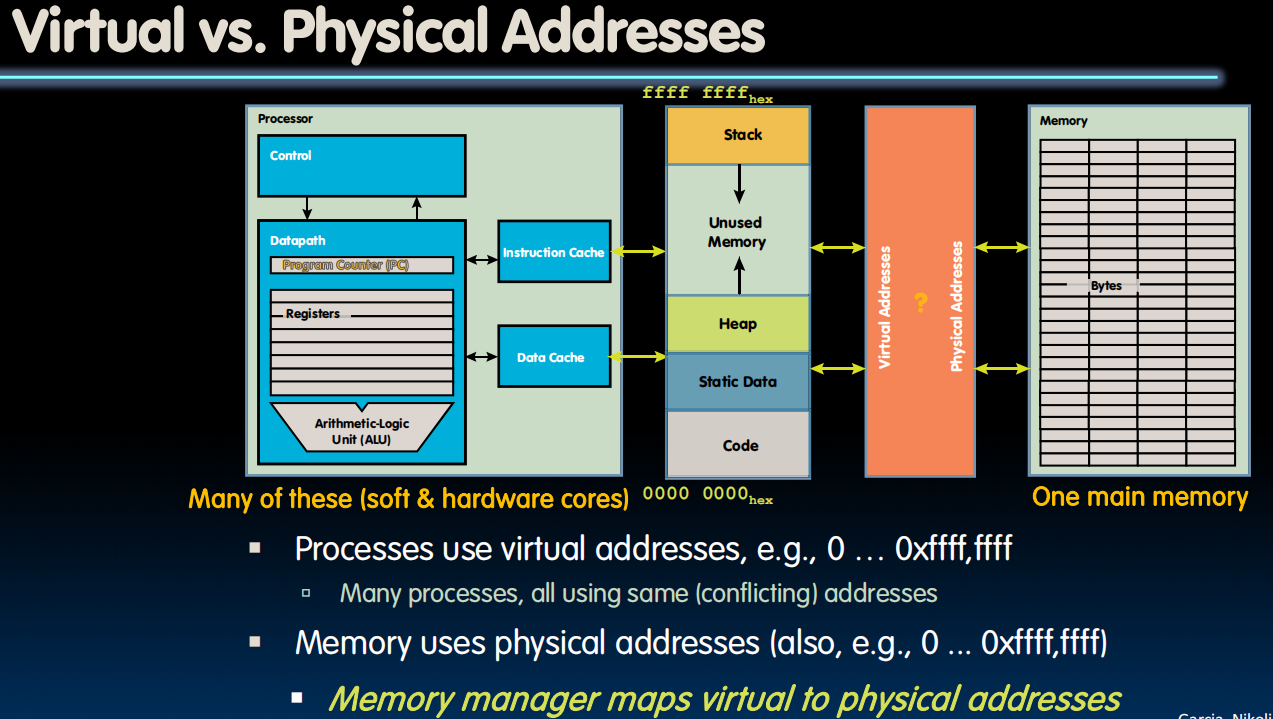
Address Spaces
- Address space = set of addresses for all available memory locations
- Now, two kinds of memory addresses:
- Virtual Address Space
- Set of addresses that the user program knows about
- Physical Address Space
- Set of addresses that map to actual physical locations in memory
- Hidden from user applications
- Virtual Address Space
- Memory manager maps (‘translates’) between these two address spaces
Analogy
- Book title like virtual address
- Library of Congress call number like physical address
- Card catalogue like page table, mapping from book title to call #
- On card for book, in local library vs. in another branch like valid bit indicating in main memory vs. on disk (storage)
- On card, available for 2-hour in library use (vs. 2-week checkout) like access rights
Memory Hierarchy Requirements
- Allow multiple processes to simultaneously occupy memory and provide protection – don’t let one program read/write memory from another
- Address space – give each program the illusion that it has its own private memory
- Suppose code starts at address 0x40000000. But different processes have different code, both residing at the same address. So each program has a different view of memory.
Physical Memory and Storage
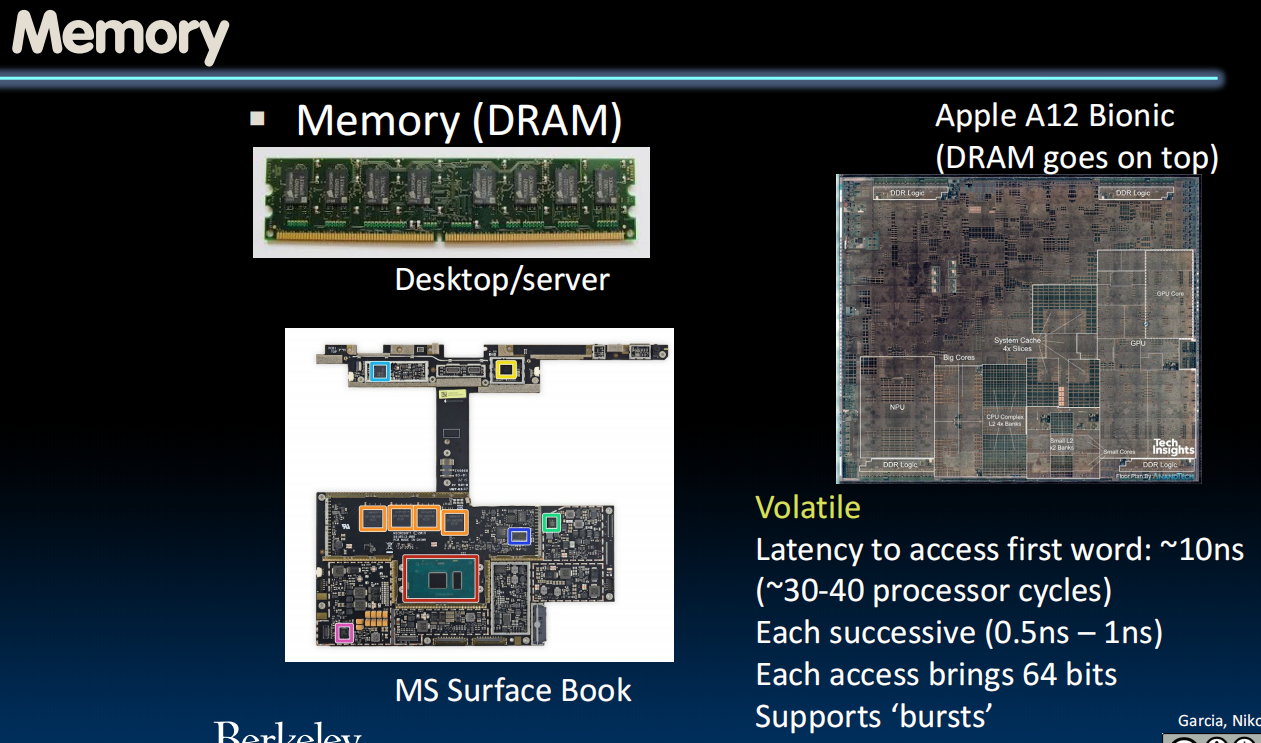
- 如果我们写入 DRAM 上的附近位置,则每次连续的读取或写入都会快得多。
- DRAM 通常支持所谓的 burst 模式,这意味着我们通常可以进行 8 次或 16 次读取或写入的bursts (会带来 8 或 16 倍的 64 bits 并填充一个缓存行)。
- DRAM 比 SRAM 稍微不稳定一些,只要电源通电,SRAM 就会保留数据,但 DRAM 会忘记,数据以电荷的形式动态存储,并且电荷可能会从 DRAM 单元泄漏。(需要控制器定期刷新以保持数据,这就是它被称为动态随机存取存储器的原因)。


how hard drive works
What About SSD?
- Made with transistors
- Nothing mechanical that turns
- Like “Ginormous” register file
- Does not ”forget” when power is off (non-volatile)
- Fast access to all locations, regardless of address
- Still much slower than register, DRAM
- Read/write blocks, not bytes
- Read/write blocks, not bytes
- Some unusual requirements:
- Can’t erase single bits – only entire blocks
flash有点类似于DRAM,it is built out of these non-volatile cells, so you somehow trap the charge inside the cell,断电后数据仍然保持。
在组织上很像DRAM,但是排列更加密集。对blocks做操作而不针对words或者bytes(如果要修改words或bytes需要修改整个block)
graph LB
A[Flash 闪存] --> B[电荷陷阱存储]
C[DRAM 动态随机存取存储器] --> D[电容充放电存储]

Memory Manger
Virtual Memory

裸机(Bare Metal)系统的内存访问特性
关键问题:在无操作系统的裸机环境中,程序直接使用物理地址访问内存
风险示例:
- 恶意程序可随意读写内核数据结构(如中断向量表)
- 驱动程序错误可能覆盖其他硬件映射区域(如 GPU 显存)
- 缺乏隔离性:所有进程共享同一物理地址空间
- 无权限控制:无法区分用户态/内核态内存区域
因此需要一个
地址转换机制
- 虚拟化:进程使用虚拟地址(Virtual Address),硬件自动转换为物理地址(Physical Address)
- 权限校验:检查页表项(Page Table Entry)中的权限位
- 隔离性:不同进程的虚拟地址空间相互独立
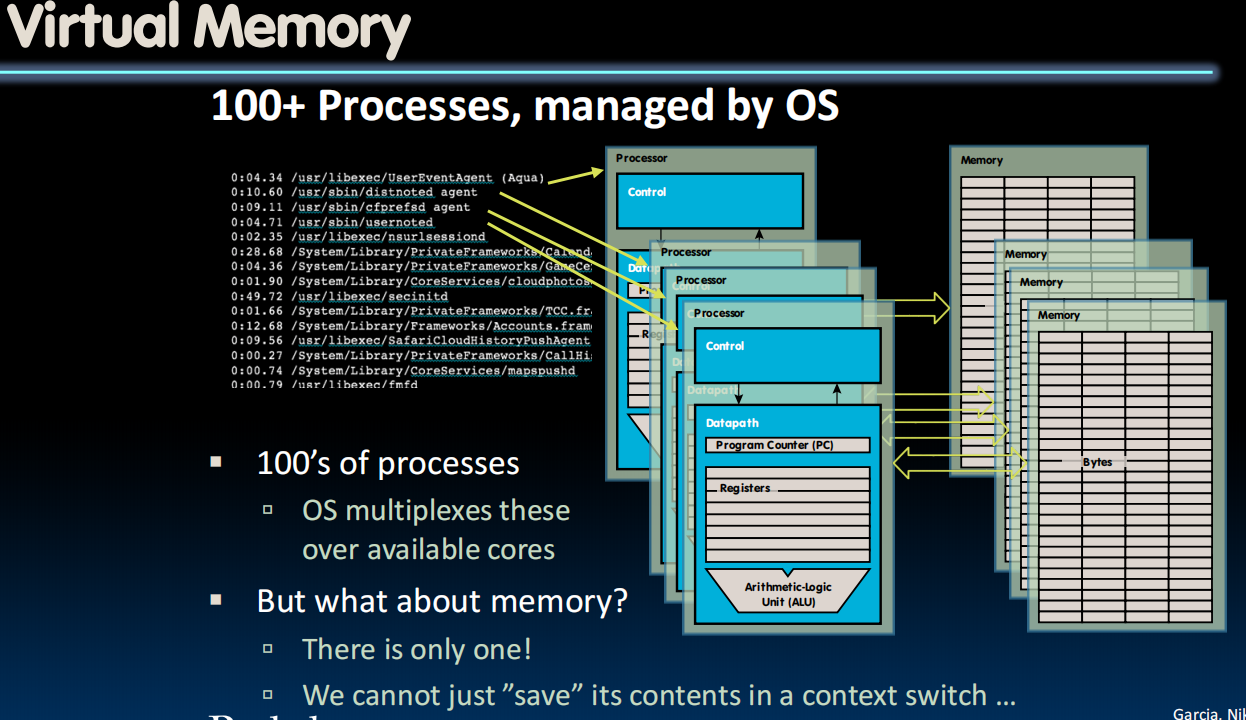
在单内存系统中频繁执行进程间上下文切换时,仅保存进程内存映像是不够的——因为所有进程共享同一物理内存空间,可能引发数据冲突。因此必须引入地址转换机制(如页表),通过虚拟化隔离各进程的内存访问。
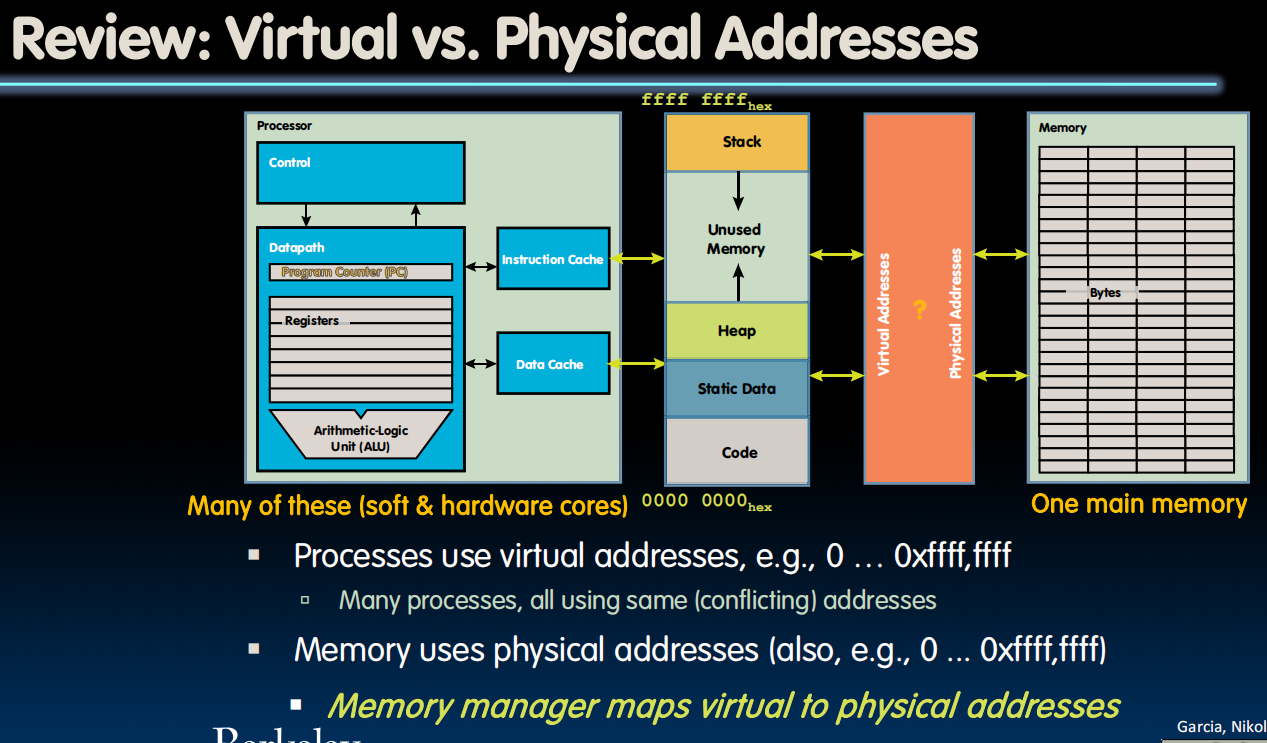
内存管理器是将虚拟地址映射到物理地址的东西。
每个进程虽然都认为它是从零地址运行到地址顶部的,但实际上它只使用了内存的一部分。内存的这些部分不一定是连续的(实际上,它们更像是交错的)。
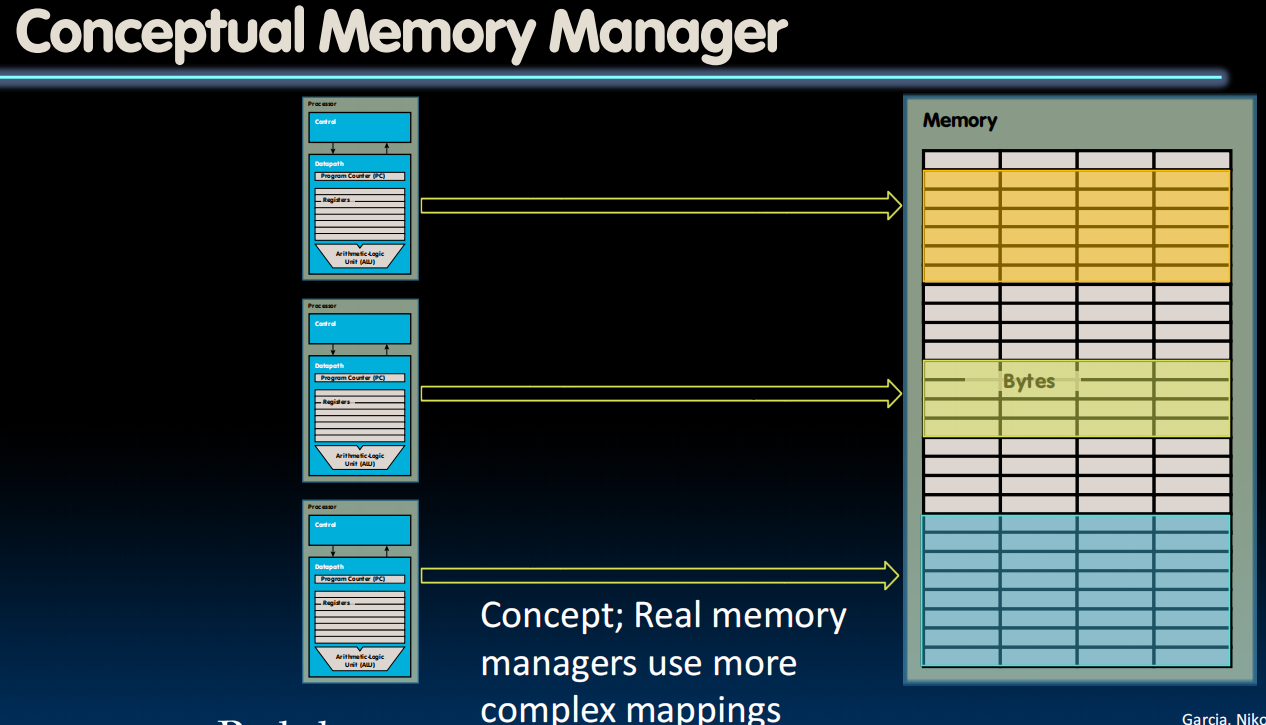
Responsibilities of Memory Manager
Mapvirtual to physical addressesProtection:- Isolate memory between processes
- Each process gets dedicate ”private” memory
- Errors in one program won’t corrupt memory of other program
- Prevent user programs from messing with OS’s memory
Swapmemory to disk- Give illusion of larger memory by storing some content on disk
- Disk is usually much larger and slower than DRAM
- Use “clever” caching strategies
Paged Memory
How does swap be performed?
我们希望在memory和disk的一些固定数据块移动来保持simplicity,这块数据被称为page。

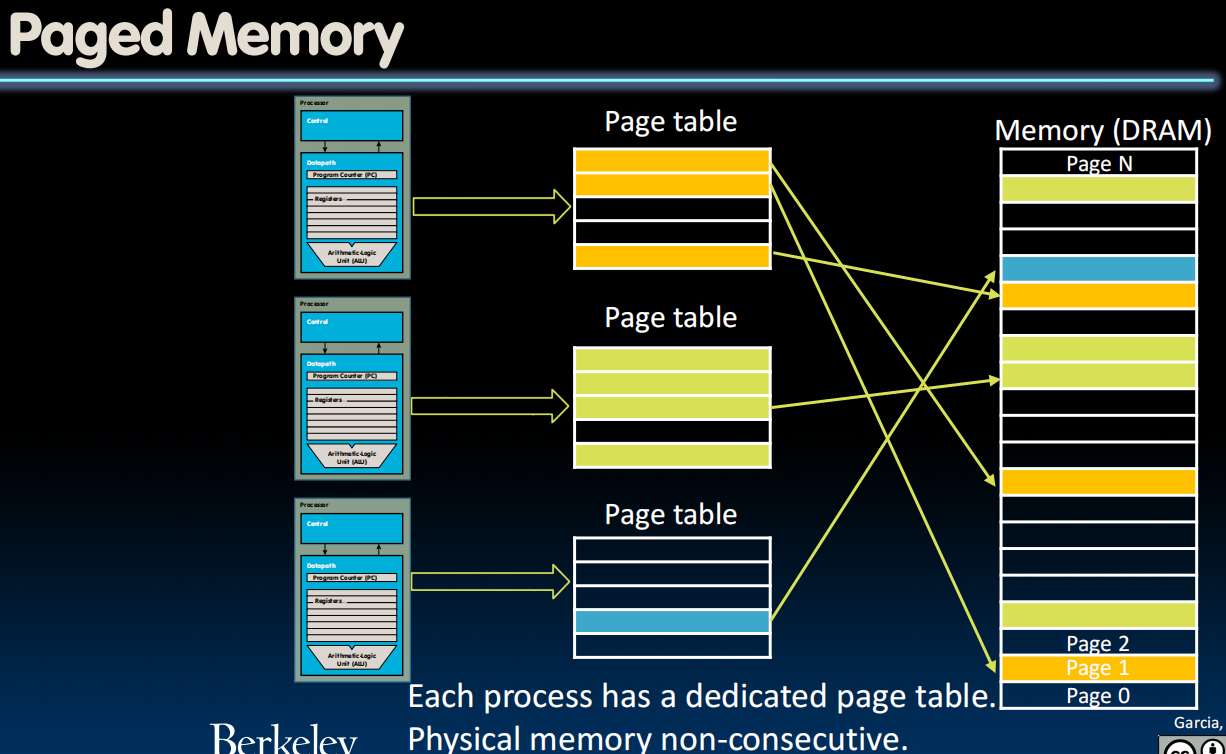
每个进程都被分配了一个page table(由操作系统管理),指向物理地址。
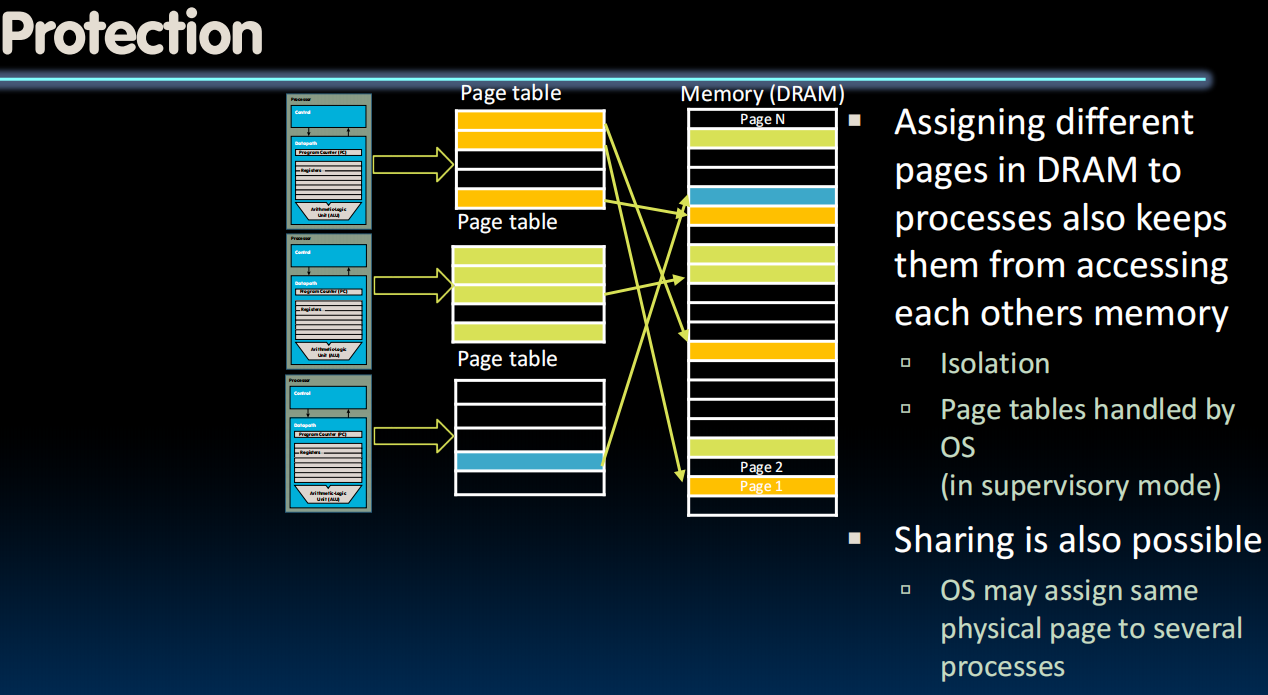
如果一个page被多个进程共享,OS会进行管理(需要一个share flag bit)。
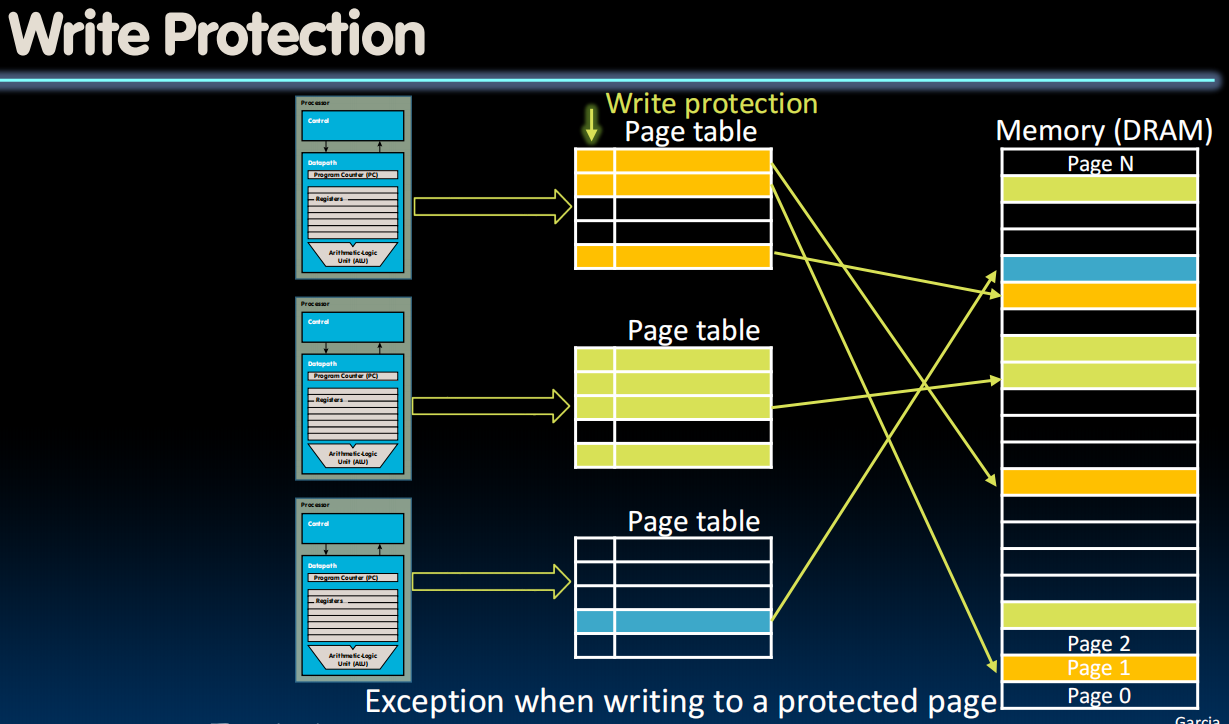
添加一个bit表明这个page正受到保护。
无法写入会引发exception。
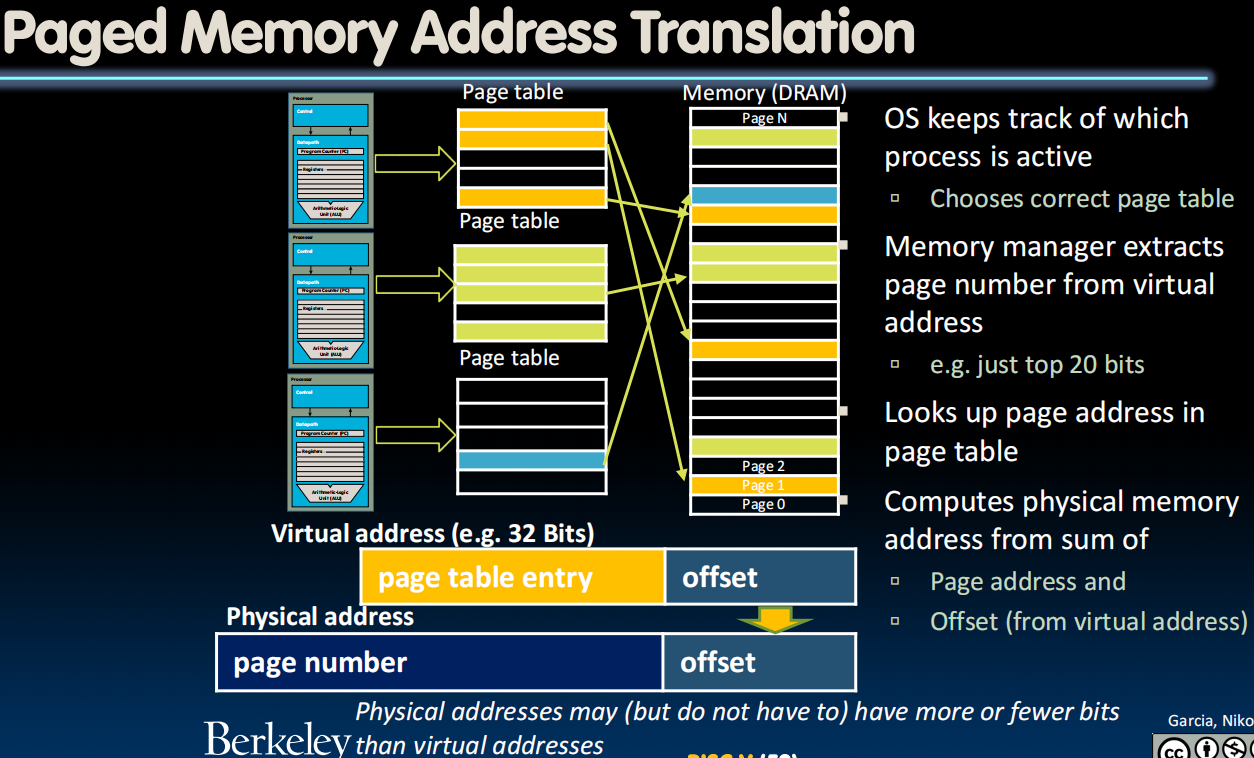
Where Do Page Tables Reside?
- E.g., 32-Bit virtual address, 4-KiB pages
- Single page table size:
- Bytes = 4-MiB
- 0.1% of 4-GiB memory
- But much too large for a cache!
- Single page table size:
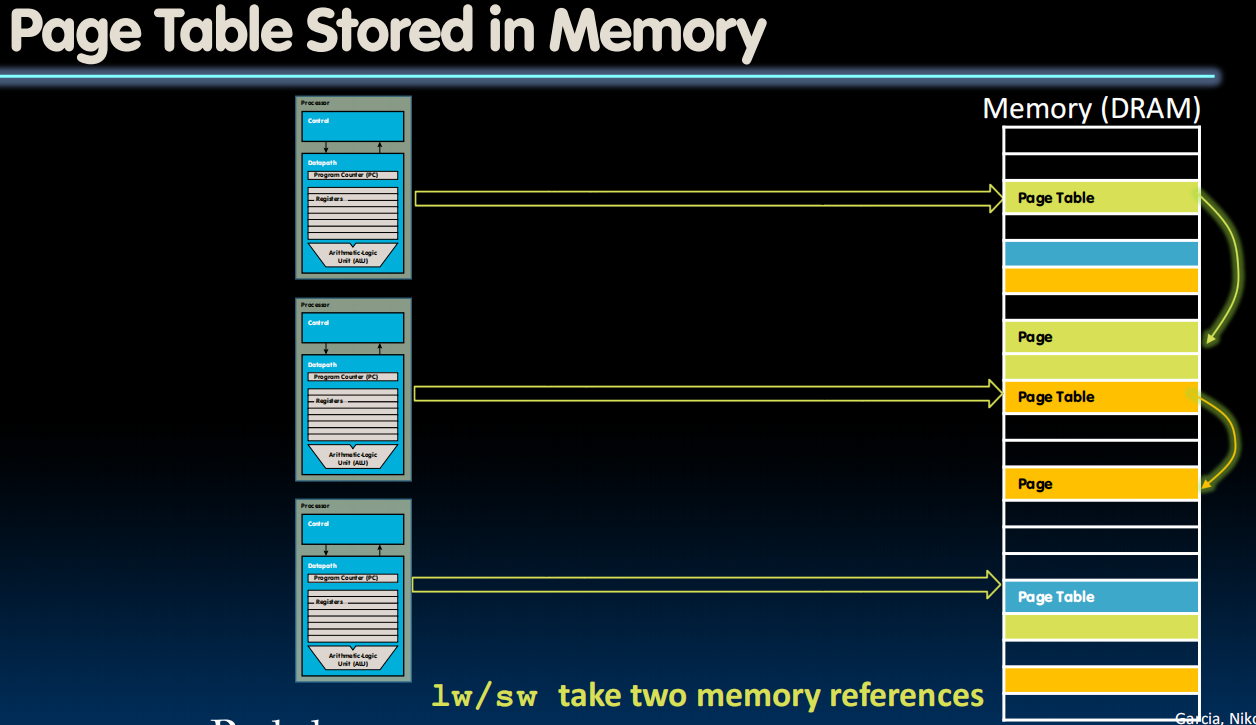
- Store page tables in memory (DRAM)
- Two (slow) memory accesses per lw/sw on cache miss (1.得到page table,2.根据page table实施lw/sw)
- How could we minimize the performance penalty?
- Transfer blocks (not words) between DRAM and processor cache
- Exploit spatial locality
- Use a cache for frequently used page table entries …
- Transfer blocks (not words) between DRAM and processor cache
Page Faults
Blocks vs. Pages
- In caches, we dealt with individual blocks
- Usually ~64B on modern systems
- In VM, we deal with individual pages
- Usually ~4 KiB on modern systems
- Common point of confusion:
- Bytes,
- Words,
- Blocks,
- Pages
- Are all just different ways of looking at memory!
Bytes, Words, Blocks, Pages

Review: Analogy
- Book title like virtual address
- Library of Congress call number like physical address
- Card catalogue like page table, mapping from book title to call #
- On card for book, in local library vs. in another branch like valid bit indicating in main memory vs. on disk (storage)
- On card, available for 2-hour in library use (vs. 2-week checkout) like access rights
Memory Access
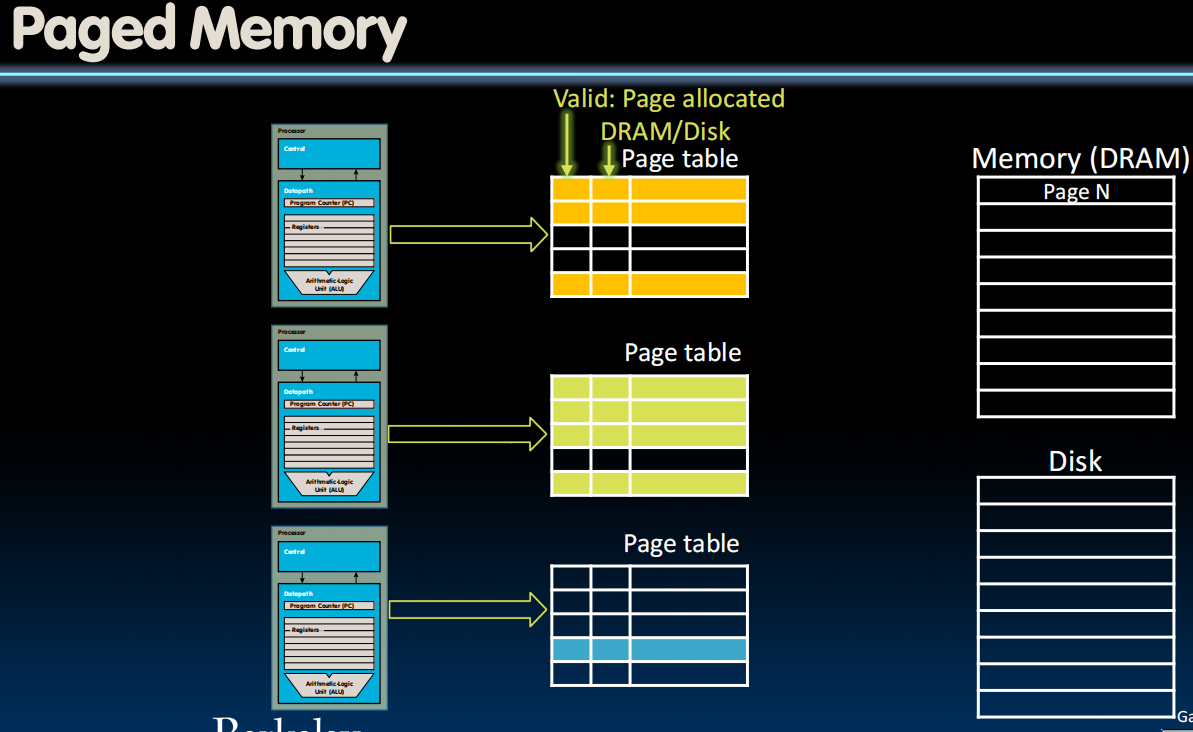
- Check page table entry:
- Valid?
- Yes, valid In DRAM?
- Yes, in DRAM: read/write data
- No, on disk: allocate new page in DRAM (Page fault OS intervention)
- If out of memory, evict a page from DRAM
- Store evicted page to disk
- Read page from disk into memory
- Read/write data
- Not Valid (Page fault OS intervention)
- allocate new page in DRAM
- If out of memory, evict a page
- Read/write data
- allocate new page in DRAM
- Yes, valid In DRAM?
- Valid?
Page Fault
Page faultsare treated as exceptions- Page fault handler (yet another function of the interrupt/trap handler) does the page table updates and initiates transfers
- Updates status bits
- (If page needs to be swapped from disk, perform context switch)
- Following the page fault, the instruction is re-executed
graph TD
A[触发 Page Fault 异常] --> B{进入 Page Fault Handler}
B --> C[检查访问合法性]
C -->|非法访问| D[终止进程 SIGSEGV]
C -->|合法访问| E{页面是否在内存中?}
E -->|已加载| F[更新页表项状态位]
E -->|未加载| G[分配物理页帧]
G --> H{需要从磁盘交换?}
H -->|是| I[发起磁盘I/O请求]
I --> J[阻塞当前进程]
J --> K[执行上下文切换]
K --> L[调度其他进程运行]
H -->|否| M[初始化零页]
M --> F
F --> N[设置Present/ Dirty/ Accessed位]
N --> O[返回用户态]
O --> P[重新执行触发异常的指令]
classDef process fill:#f9f,stroke:#333;
classDef exception fill:#f96,stroke:#333;
classDef handler fill:#6f9,stroke:#333;
classDef disk fill:#69f,stroke:#333;
classDef memory fill:#9f6,stroke:#333;
class A exception;
class B,C,E,F,N handler;
class I,J,K,L disk;
class G,M memory;
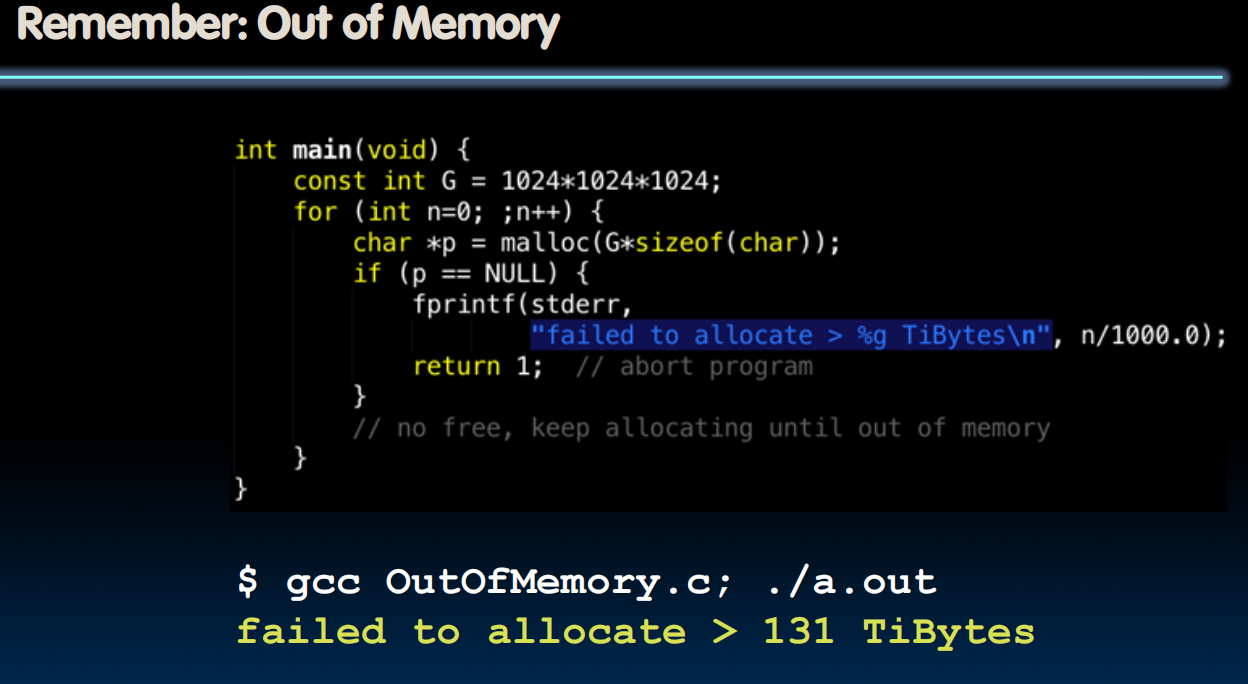
Write-Through or Write-Back?
- DRAM acts like “cache” for disk
- Should writes go directly to disk (write-through)?
- Or only when page is evicted?
- Which option do you propose?
Lecture 30 (Virtual Memory 2)
Hierarchical Page Tables


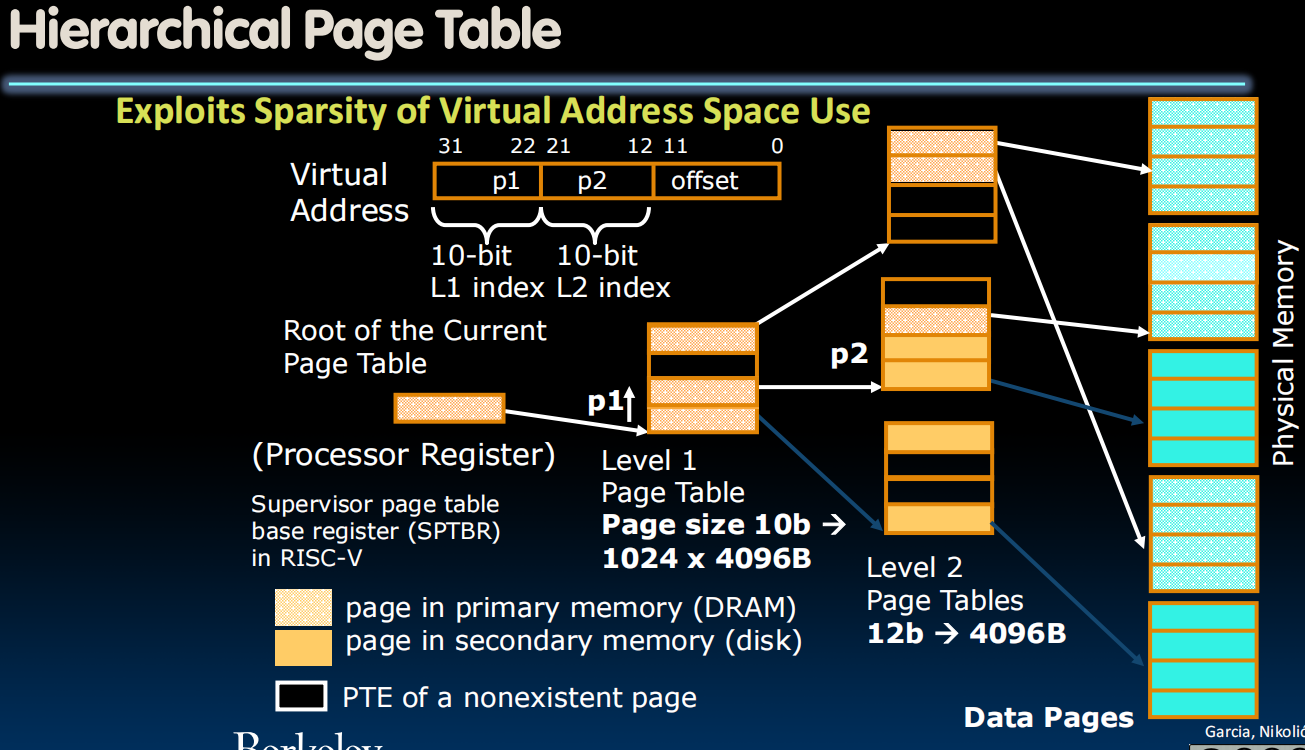
虚拟地址结构
- 虚拟地址被分为三个部分:
- p1 (10-bit L1 index): 用于在第一级页表中索引。
- p2 (10-bit L2 index): 用于在第二级页表中索引。
- offset (12-bit): 用于在数据页中定位具体的数据。
页表结构
- 根页表 (Root of the Current Page Table): 存储在处理器寄存器中,是当前页表的入口。
- 第一级页表 (Level 1 Page Table): 页大小为10b,即1024个条目,每个条目指向一个4096B的数据页。
- 第二级页表 (Level 2 Page Tables): 页大小为12b,即4096个条目,每个条目指向一个4096B的数据页。
- 物理内存:包含映射到物理内存的数据页。
关键组件:
- Supervisor Page Table Base Register (SPTBR):存储当前页表的根地址。
- 主内存(DRAM):存储在主内存中的页面。
- 二级存储(Disk):存储在二级存储(硬盘)中的页面。
- 不存在的页面的PTE:指示页面没有被映射到内存中。
由于分页系统设置得非常严格,我们实际上为偏移量和页表的每个级别分配了精确的位数,因此只要知道从哪里开始就可以按照固定规则构建整个树。
在上下文切换时,当我们想要切换到一个新进程时,我们所需要做的就是恢复前一个进程的状态,只需指向SPTBR (一个特权寄存器,它存储了当前进程页表的基地址)。

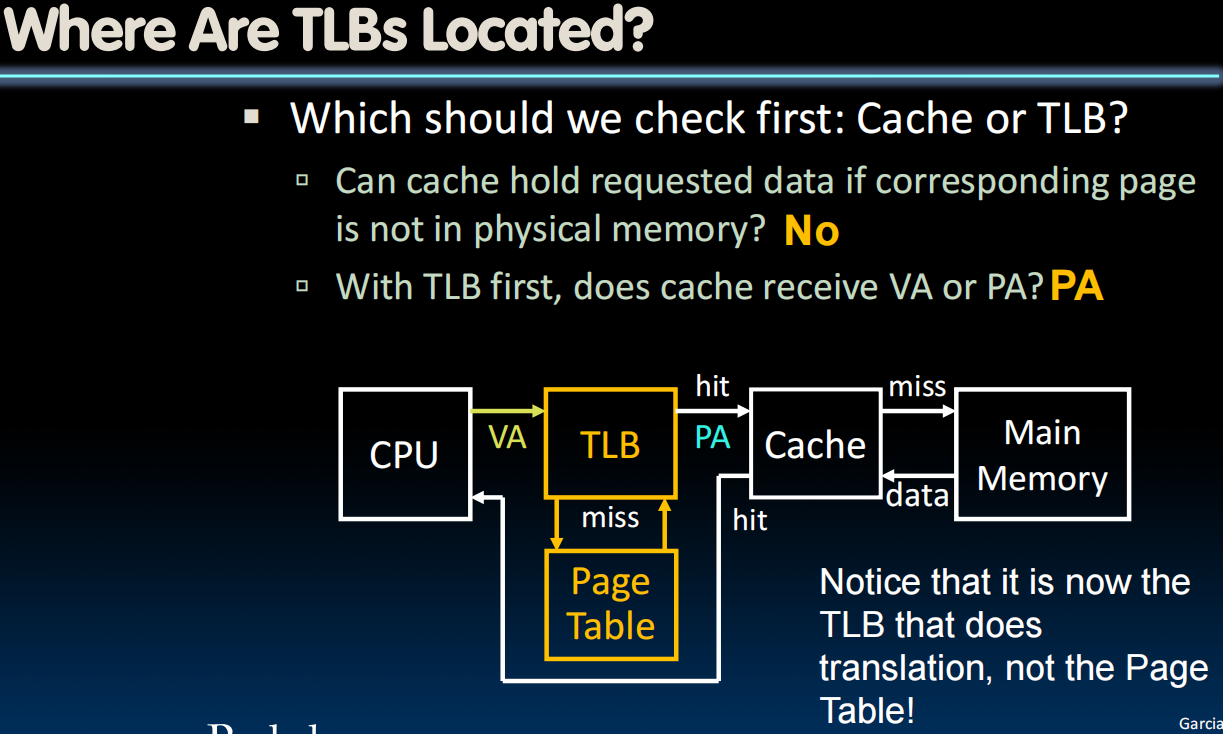
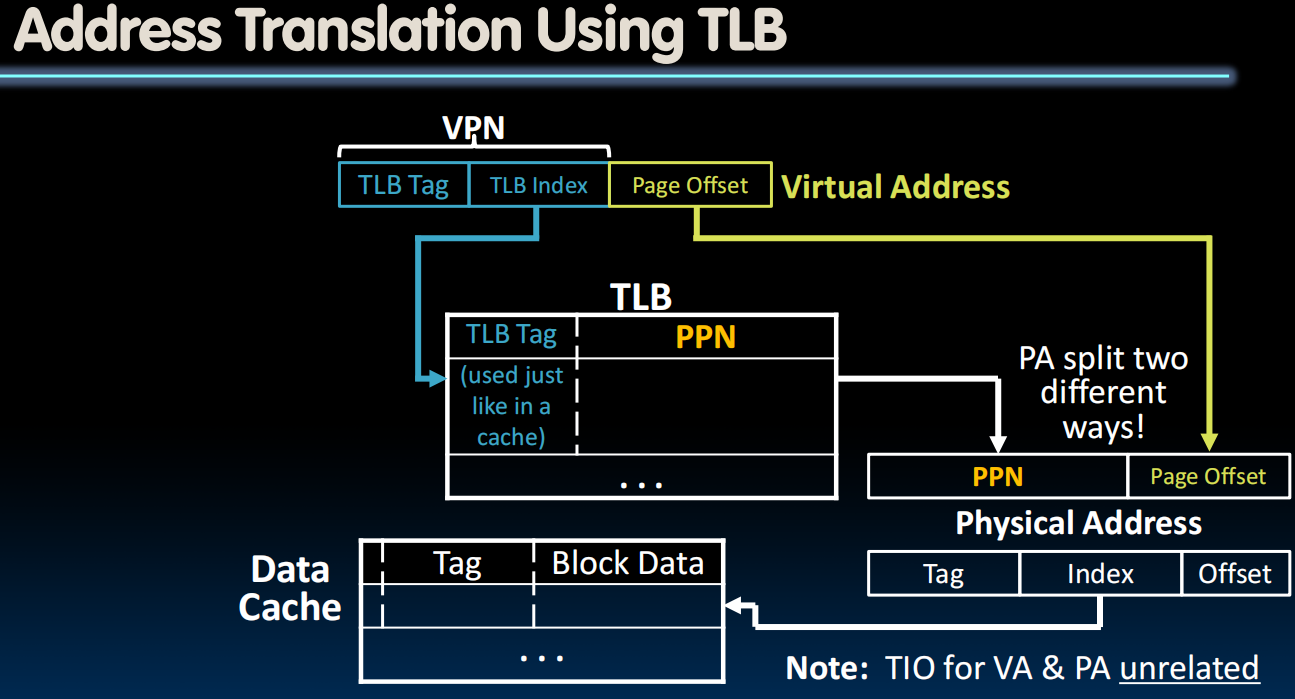
Translation Lookaside Buffers (speed up memory access)
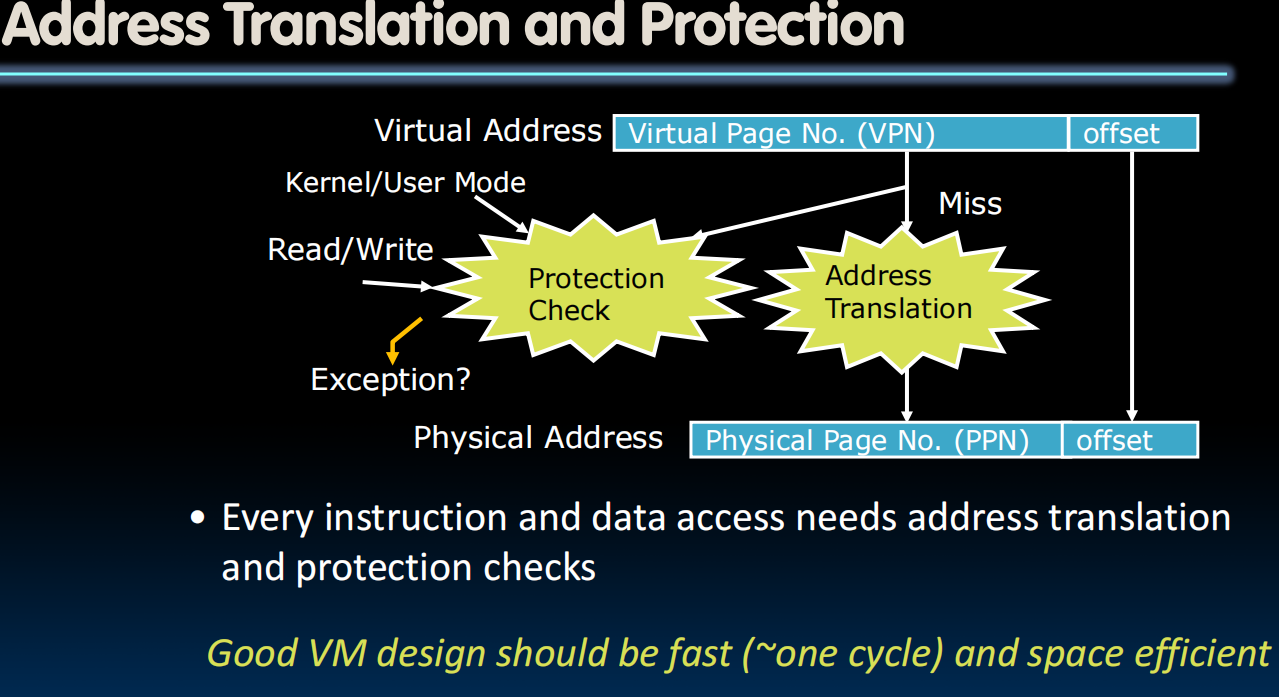
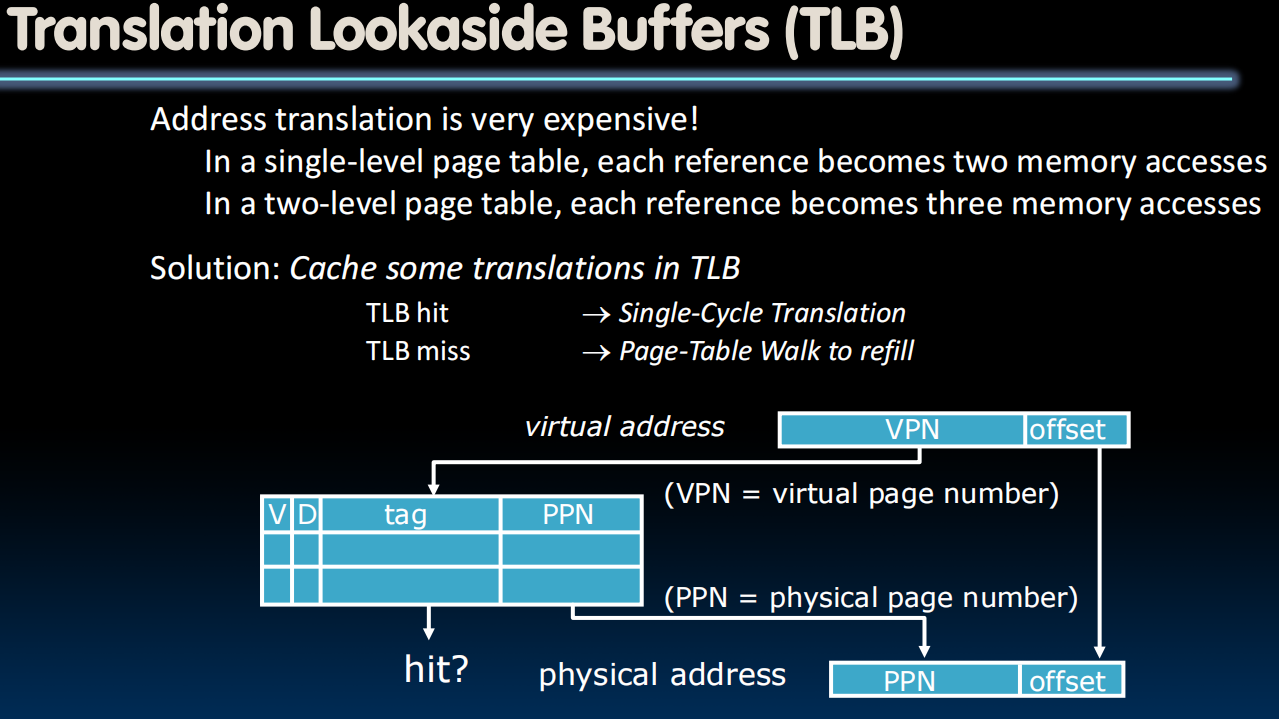
cache some of the memory translations in the TLB.
TLB Designs
- Typically 32-128 entries, usually fully associative
- Each entry maps a large page, hence less spatial locality across pages more likely that two entries conflict
- Sometimes larger TLBs (256-512 entries) are 4-8 way set-associative
- Larger systems sometimes have multi-level (L1 and L2) TLBs
- Random or FIFO replacement policy
- “TLB Reach”: Size of largest virtual address space that can be simultaneously mapped by TLB
TLBs in Datapath
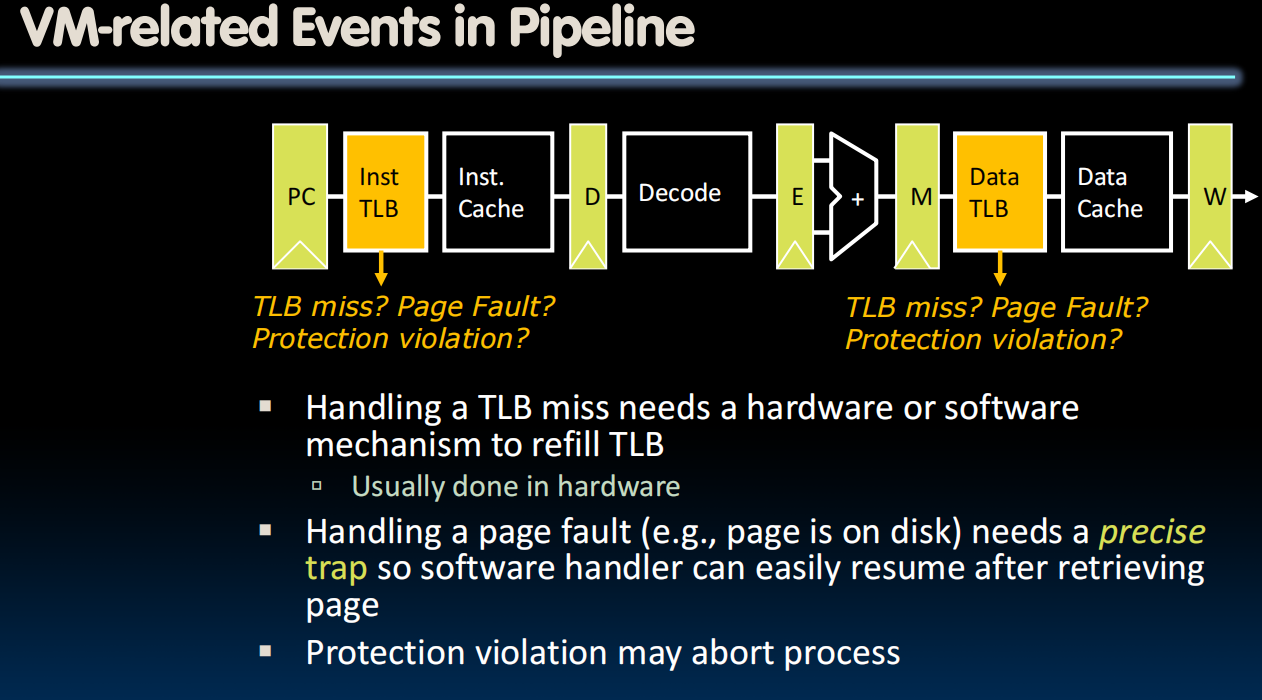
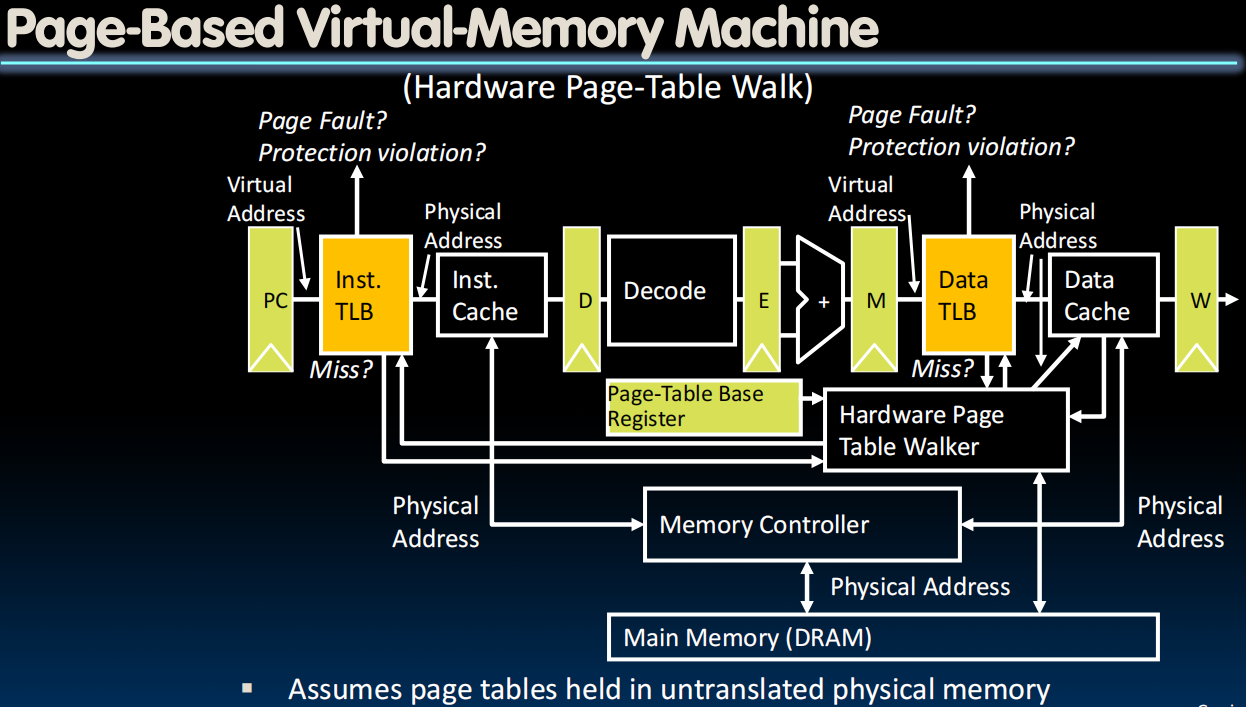
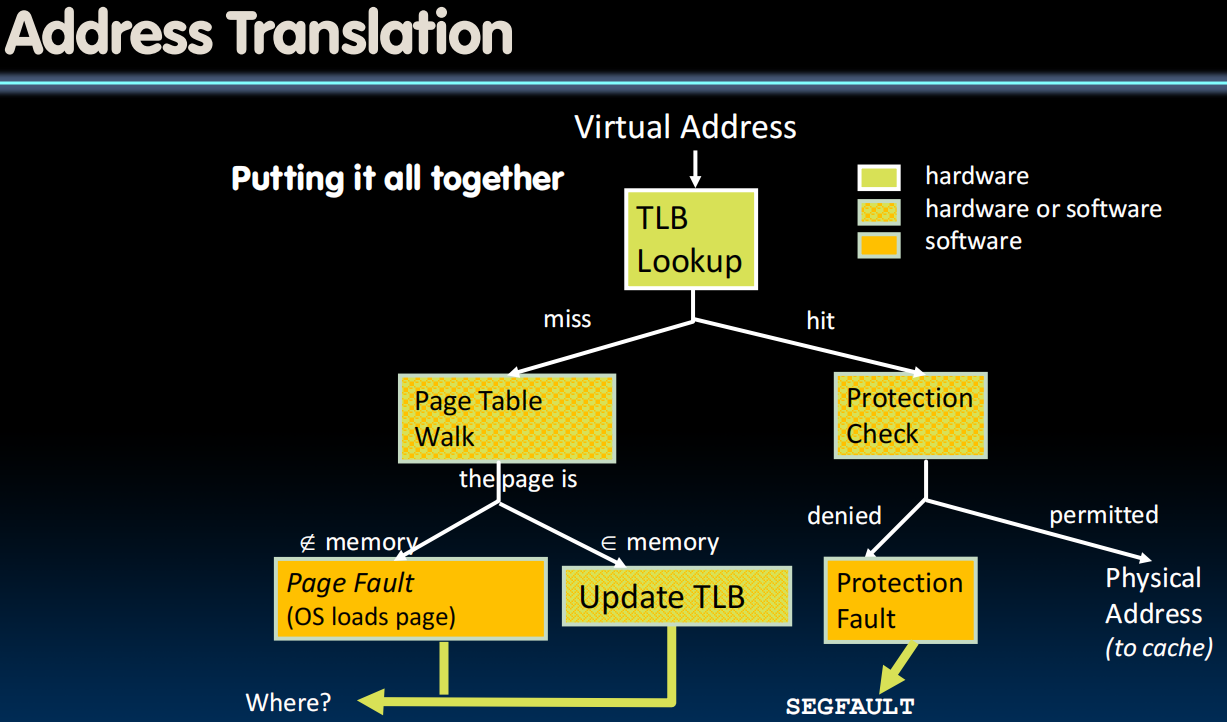

Review: Context Switching
- How does a single processor run many programs at once?
- Context switch: Changing of internal state of processor (switching between processes)
- Save register values (and PC) and change value in Supervisor Page Table Base register (SPTBR)
- What happens to the TLB?
- Current entries are for different process
- Set all entries to invalid on context switch
VM Performance

VM Performance
- Virtual Memory is the level of the memory hierarchy that sits below main memory
- TLB comes before cache, but affects transfer of data from disk to main memory
- Previously we assumed main memory was lowest level, now we just have to account for disk accesses
- Same CPI, AMAT equations apply, but now treat main memory like a mid-level cache

Impact of Paging on AMAT
- Memory Parameters:
- L1 cache hit = 1 clock cycles, hit 95% of accesses
- L2 cache hit = 10 clock cycles, hit 60% of L1 misses
- DRAM = 200 clock cycles (≈100 nanoseconds)
- Disk = 20,000,000 clock cycles (≈10 milliseconds)
- Average Memory Access Time (no paging):
- 1 + 5%×10 + 5%×40%×200 = 5.5 clock cycles
- Average Memory Access Time (with paging):
- 5.5 (AMAT with no paging) + ?
- Average Memory Access Time (with paging) =
- 5.5 + 5%×40%× (1- )×20,000,000
- AMAT if = 99%?
- 5.5 + 0.02×0.01×20,000,000 = 4005.5 (≈728x slower)
- 1 in 20,000 memory accesses goes to disk: 10 sec program takes 2 hours!
- AMAT if = 99.9%?
- 5.5 + 0.02×0.001×20,000,000 = 405.5
- AMAT if = 99.9999%?
- 5.5 + 0.02×0.000001×20,000,000 = 5.9
记得太多了,这个笔记先到这里,接下来会新开一个笔记做

