这是一个CS61C的笔记,由于是边上课边记的,很多地方选择偷懒进行截图,,,
Lecture 31 (I/O Devices)
I/O Devices
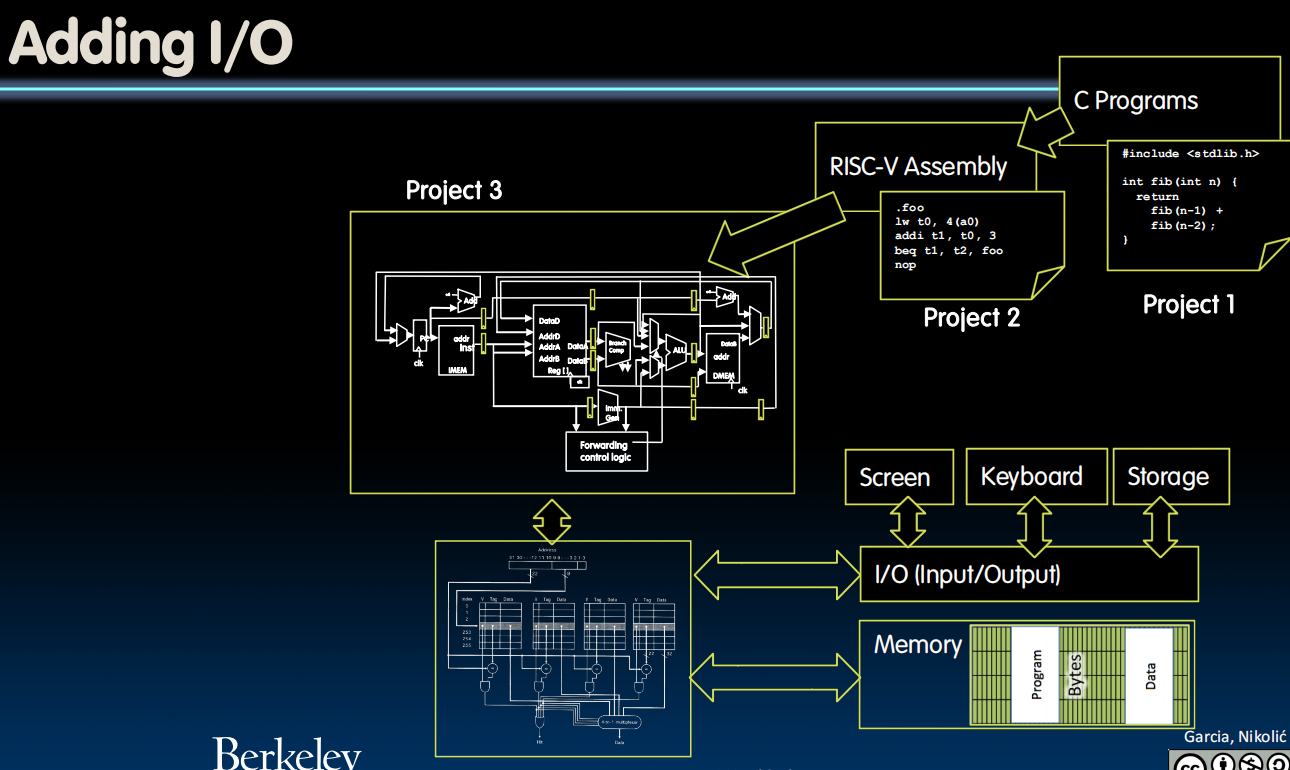
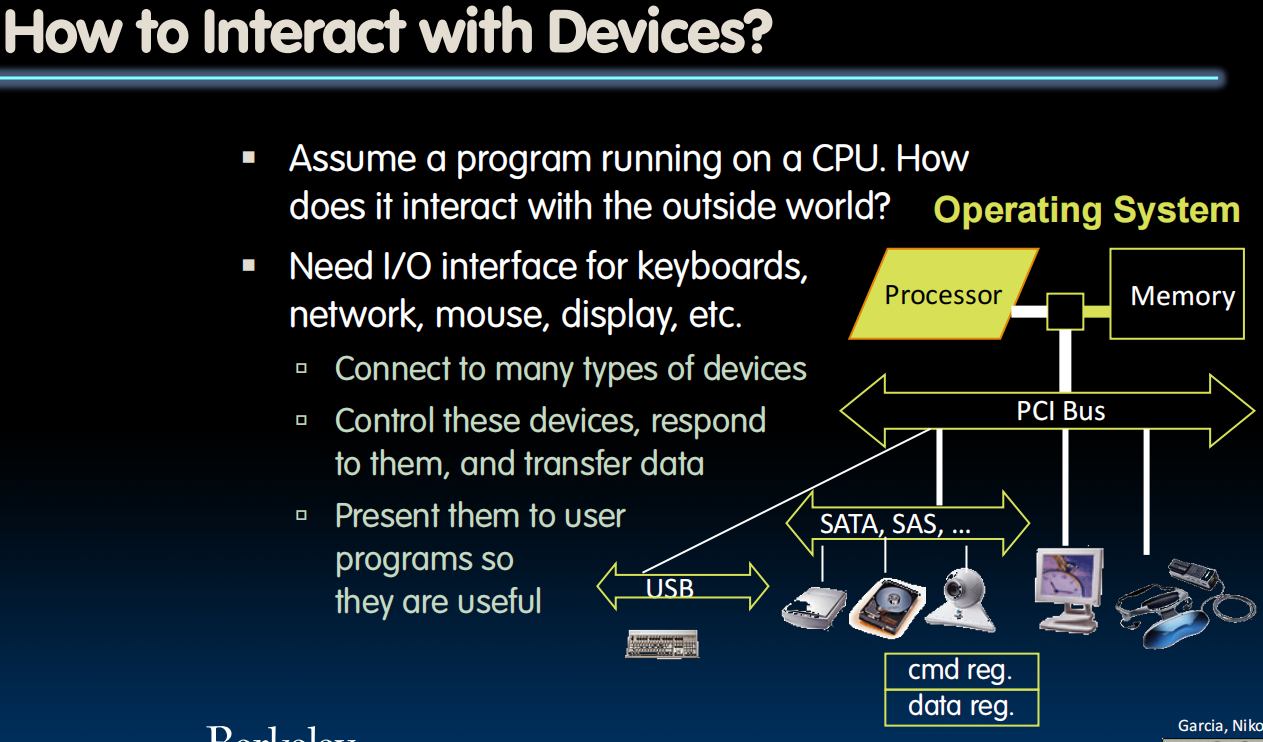
用一种general way连接IO devices (通过某种层次化的总线进行连接,命令和状态寄存器组成的标准化接口)
- Instruction Set Architecture for I/O
- What must the processor do for I/O?
- Input: Read a sequence of bytes
- Output: Write a sequence of bytes
- Interface options
a) Special input/output instructions & hardware
b) Memory mapped I/O ( )- Portion of address space dedicated to I/O (命令和状态寄存器)
- I/O device registers there (no memory)
- Use normal load/store instructions, e.g. lw/sw
- Very common, used by RISC-V
- What must the processor do for I/O?

每个IO设备都有其寄存器副本在这块内存中

那些超出核心读写带宽的设计是为了支持更高端的处理器
I/O Polling
Polling: Processor Checks Status, Then Acts
出于Speed Mismatch
- Device registers generally serve two functions:
- Control Register, says it’s OK to read/write (I/O ready)
[think of a flagman on a road] - Data Register, contains data
- Control Register, says it’s OK to read/write (I/O ready)
- Processor reads from Control Register in loop
- Waiting for device to set Ready bit in Control reg (0 → 1)
- Indicates “data available” or “ready to accept data”
- Processor then loads from (input) or writes to (output) data register
- I/O device resets control register bit (1 → 0)
- Procedure called “Polling” (处理器会反复且定期地检查控制寄存器)
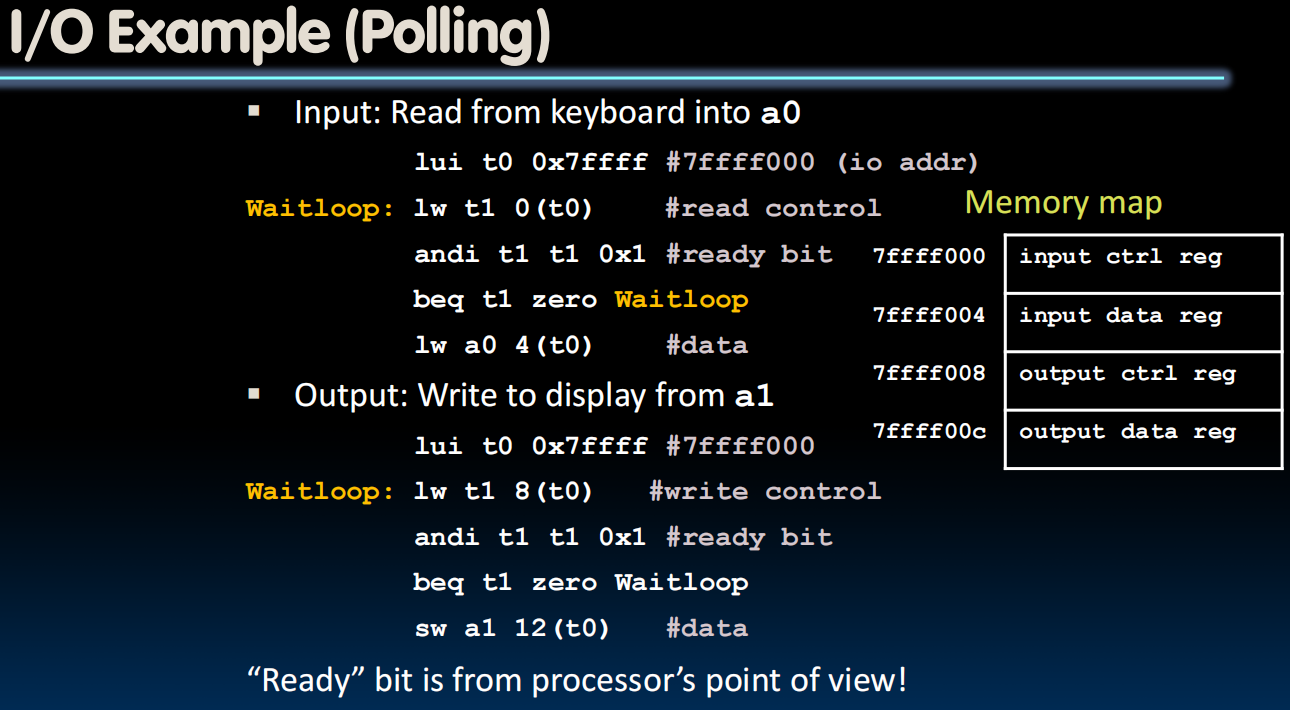
Cost of Polling? (开销)
- Assume for a processor with
- 1 GHz clock rate
- Taking 400 clock cycles for a polling operation
- Call polling routine
- Check device (e.g., keyboard or WiFi input available)
- Return
- What’s the percentage of processor time spent polling?
- Example:
- Mouse
- Poll 30 times per second
- Set by requirement not to miss any mouse motion (which would lead to choppy motion of the cursor on the screen)


I/O Interrupts
Alternatives to Polling: Interrupts
- Polling wastes processor resources
- Akin to waiting at the door for guests to show up
- What about a bell?
- Computer lingo for bell:
- Interrupt
- Occurs when I/O is ready or needs attention
- Interrupt current program
- Transfer control to the trap handler in the operating system
- Interrupts:
- No I/O activity: Nothing to do
- Lots of I/O: Expensive – thrashing caches, VM, saving/restoring state
Polling, Interrupts and DMA
- Low data rate (e.g. mouse, keyboard)
- Use interrupts. Could poll with the timer interrupt, but why?
- Overhead of interrupts ends up being low
- High data rate (e.g. network, disk)
- Start with interrupts...
- If there is no data, you don't do anything!
- Once data starts coming... Switch to Direct Memory Access (DMA)
- Start with interrupts...
Aside: Programmed I/O
- “Programmed I/O”:
- Standard for ATA hard-disk drives
- CPU execs lw/sw instructions for all data movement to/from devicess
- CPU spends time doing two things:
- Getting data from device to main memory
- Using data to compute
- Not ideal because …
- CPU has to execute all transfers, could be doing other work
- Device speeds don’t align well with CPU speed
- Energy cost of using beefy general-purpose CPU where simpler hardware would suffice
- Until now CPU has sole control of main memory
- 5% of CPU cycles on Google Servers spent in memcpy() and memmove() library routines!*
*Kanev et al., “Profiling a warehouse-scale computer,” ICSA 2015, (June 2015), Portland, OR.
DMA
Direct Memory Access (DMA)
寄存器包含放置数据的内存地址、要传输的字节数、应该执行到内存或从内存传输方向的 I/O 设备的数量、应该朝那个方向转移、传输单位以及每次 burst 应执行多少操作。
- Allows I/O devices to directly read/write main memory
- New hardware: The DMA Engine
- DMA engine contains registers written by CPU:
- Memory address to place data
- # of bytes
- I/O device #, direction of transfer
- unit of transfer, amount to transfer per burst
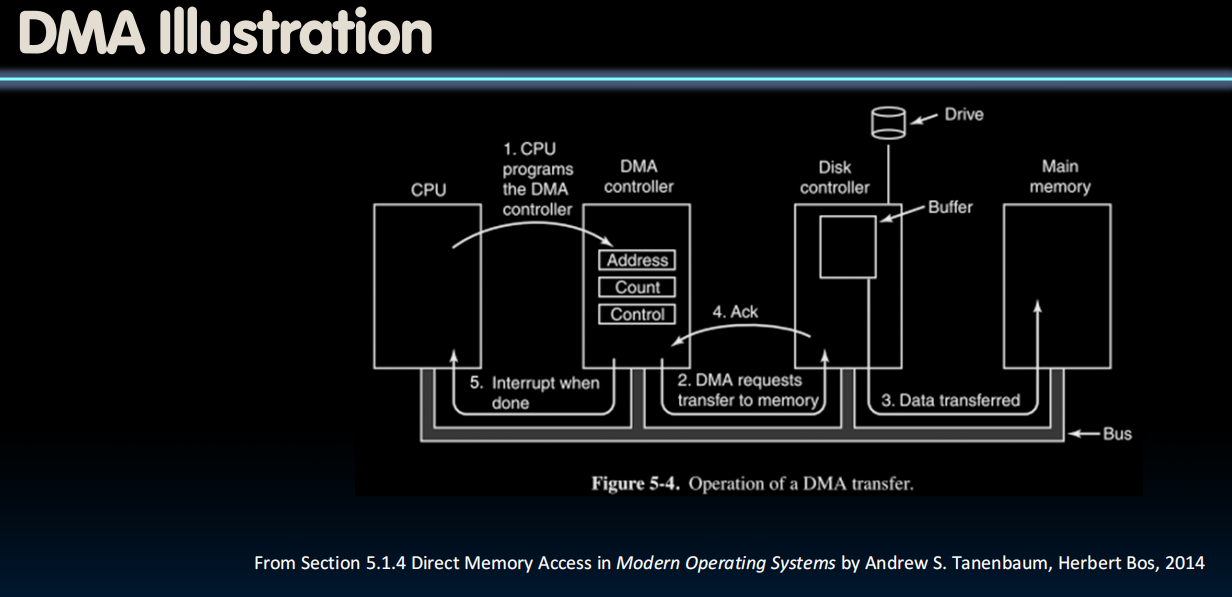
DMA: Incoming Data
- Receive interrupt from device
- CPU takes interrupt, initiates transfer
- Instructs DMA engine/device to place data @ certain address
- Device/DMA engine handle the transfer
- CPU is free to execute other things
- Upon completion, Device/DMA engine interrupt the CPU again
DMA: Outgoing Data
- CPU decides to initiate transfer, confirms that external device is ready
- CPU begins transfer
- Instructs DMA engine/device that data is available @ certain address
- Device/DMA engine handle the transfer
- CPU is free to execute other things
- Device/DMA engine interrupt the CPU again to signal completion
DMA: Some New Problems
- Where in the memory hierarchy do we plug in the DMA engine? Two extremes:
- Between L1$ and CPU:
- Pro: Free coherency
- Con: Trash the CPU’s working set with transferred data
- Between Last-level cache and main memory:
- Pro: Don’t mess with caches
- Con: Need to explicitly manage coherency
- Between L1$ and CPU:
challenge: 需要实现一个新的一致性引擎
Networking
Networks: Talking to the Outside World
- Originally sharing I/O devices between computers
- E.g., printers
- Then communicating between computers
- E.g., file transfer protocol
- Then communicating between people
- E.g., e-mail
- Then communicating between networks of computers
- E.g., file sharing, www, …




Conclusion
- We have figured out how computers work!
- And figured out how the OS works and how to interact with it
- We have built a virtual memory system
- And have developed understanding of physical memory, storage devices
- And we can attach peripherals for I/O!
Lecture 32 (Flynn Taxonomy, SIMD Instructions)
Parallelism
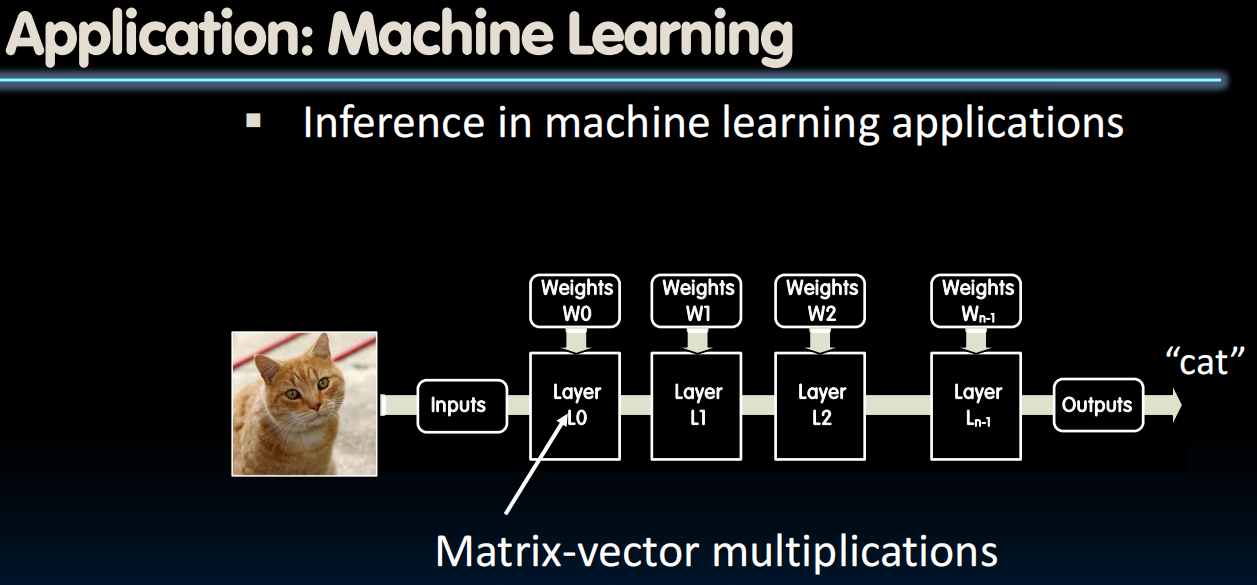
Reference Problem: Matrix Multiplication
- Matrix multiplication
- Basic operation in many engineering, data, and imaging processing tasks
- Image filtering, noise reduction, machine learning…
- Many closely related operations
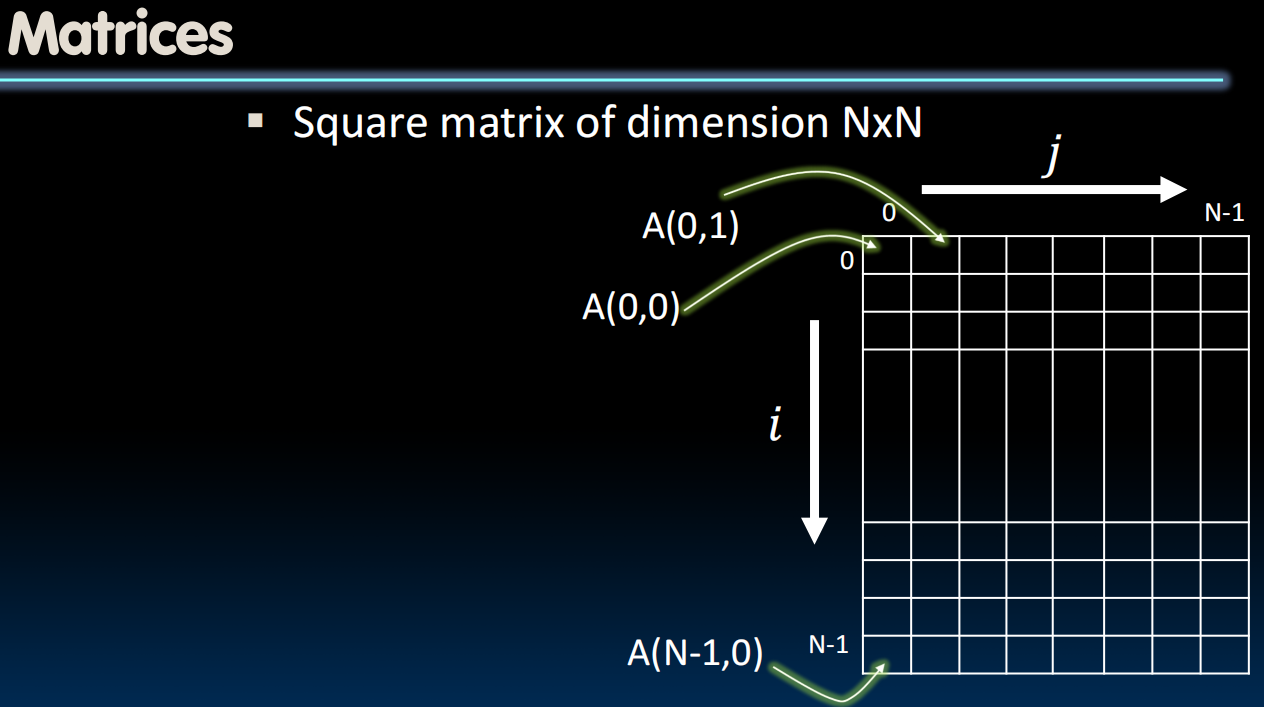
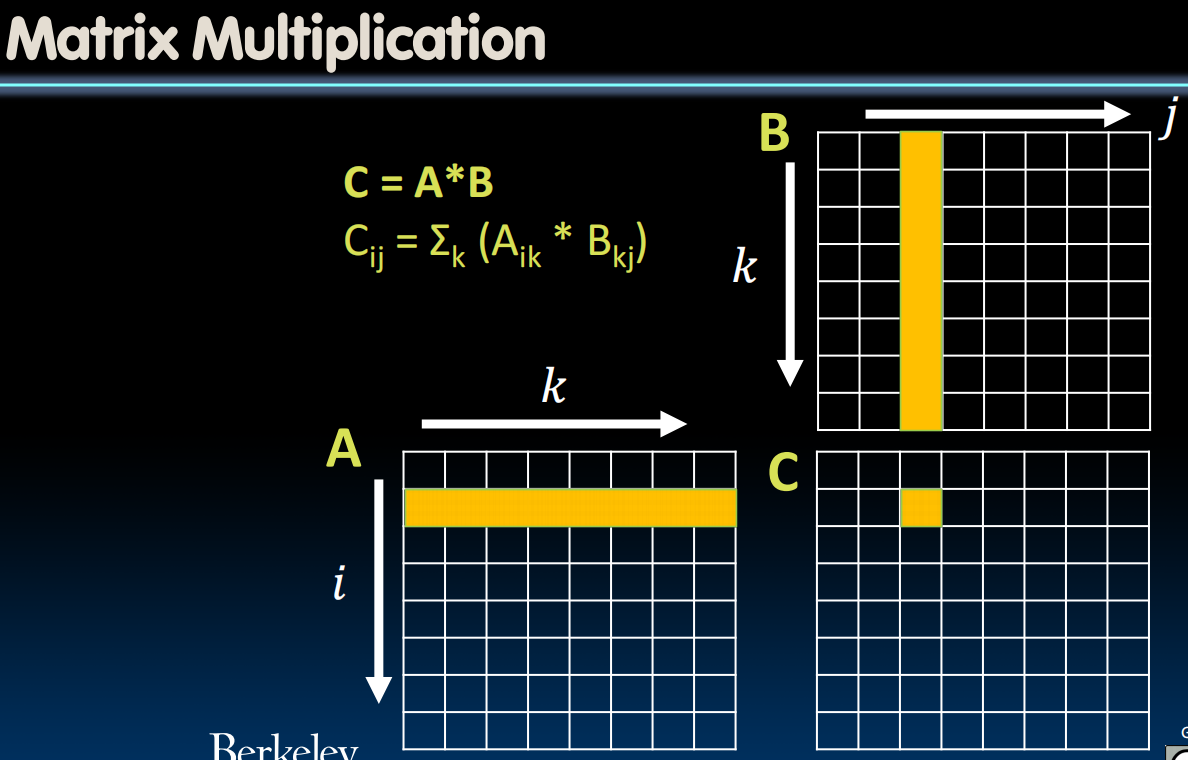
Matrix Multiplication

C
void dgemm_scalar(int N, double *a, double *b, double *c)
{
for (int i=0; i<N; i++)
{
for (int j=0; j<N; j++)
{
double cij = 0;
for (int k=0; k<N; k++)
{
// a[i][k] * b[k][j]
cij += a[i+k*N] * b[k+j*N];
}
// c[i][j]
c[i+j*N] = cij;
}
}
}Timing Program Execution
- GFLOPS (Giga Floating-point Operations Per Second): 衡量计算机性能的重要指标,GFLOPS = 10^9 次浮点运算/秒;
# include <stdio.h>
# include <stdlib.h>
# include <time.h>
int main(void){
// start time
// Note: clock() measures exxecution time, not real time
// big difference in shared computer environments
// and with heavy system load
clock_t start = clock();
// task to time gose here:
// dgemm(N, ,,,);
// "stop" the timer
clock_t end = clock();
// compute execution time in seconds
double delta_time = (double)(end-start)/CLOCKS_PER_SEC;
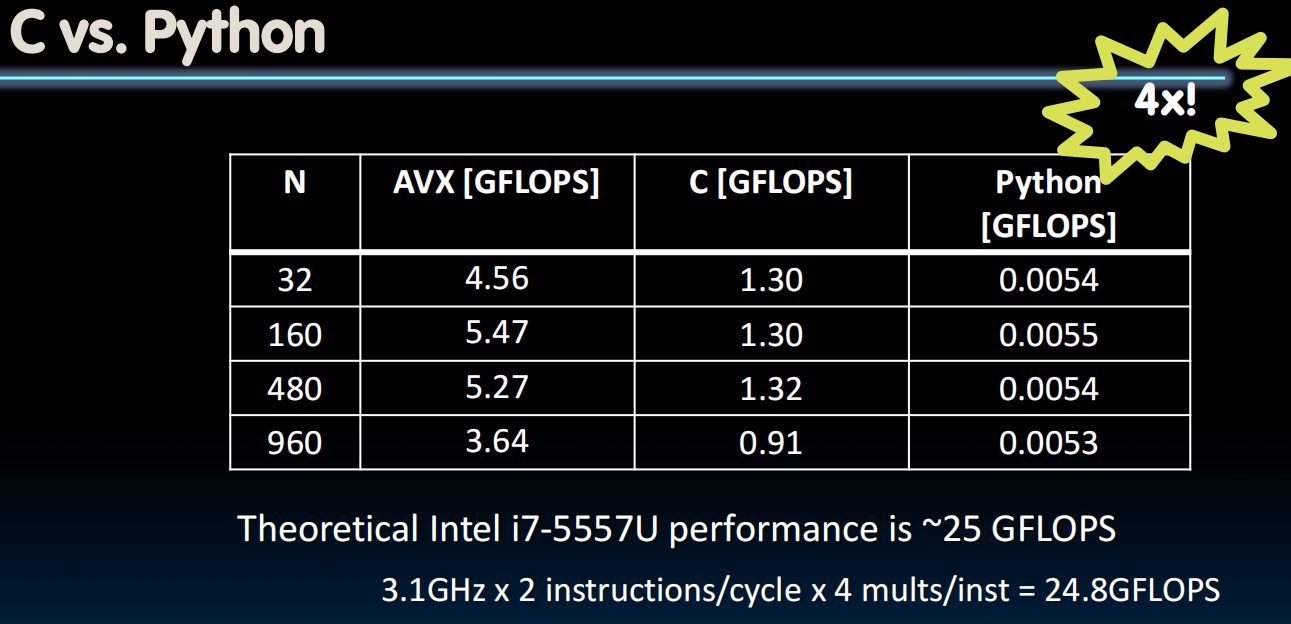
}C远比python快
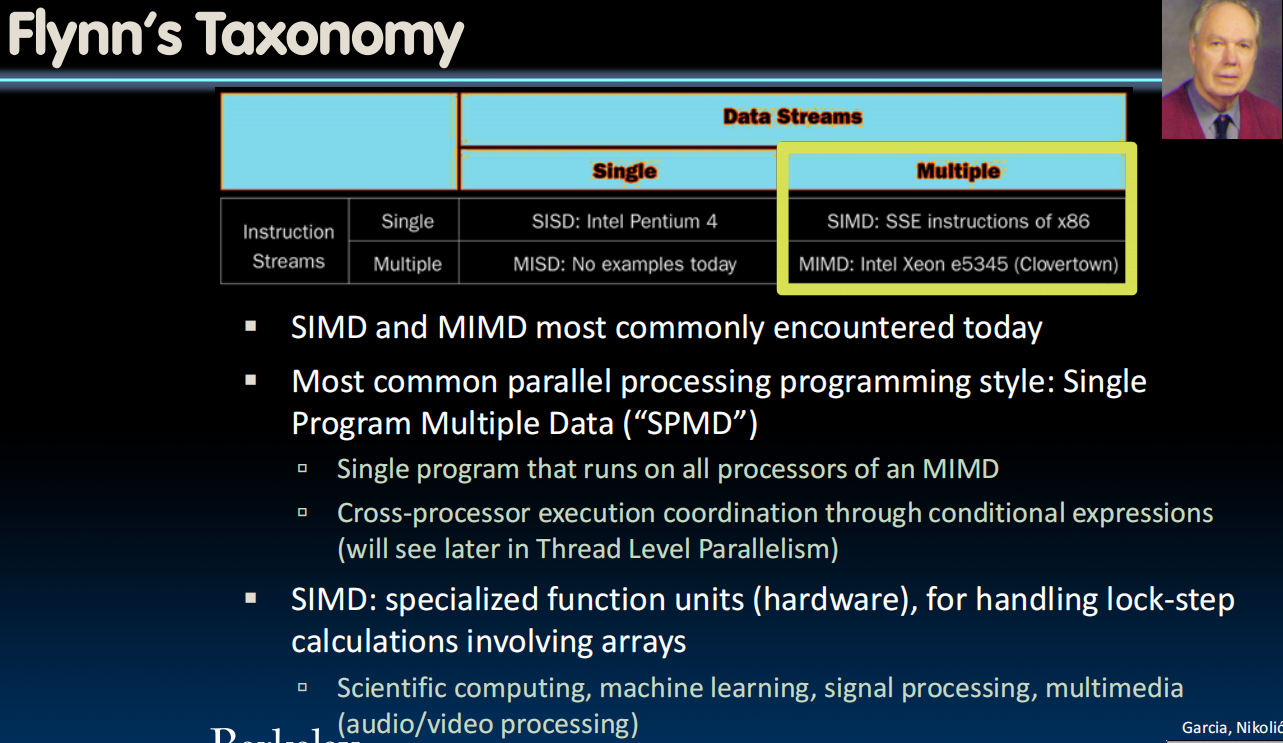
Flynn's Taxonomy

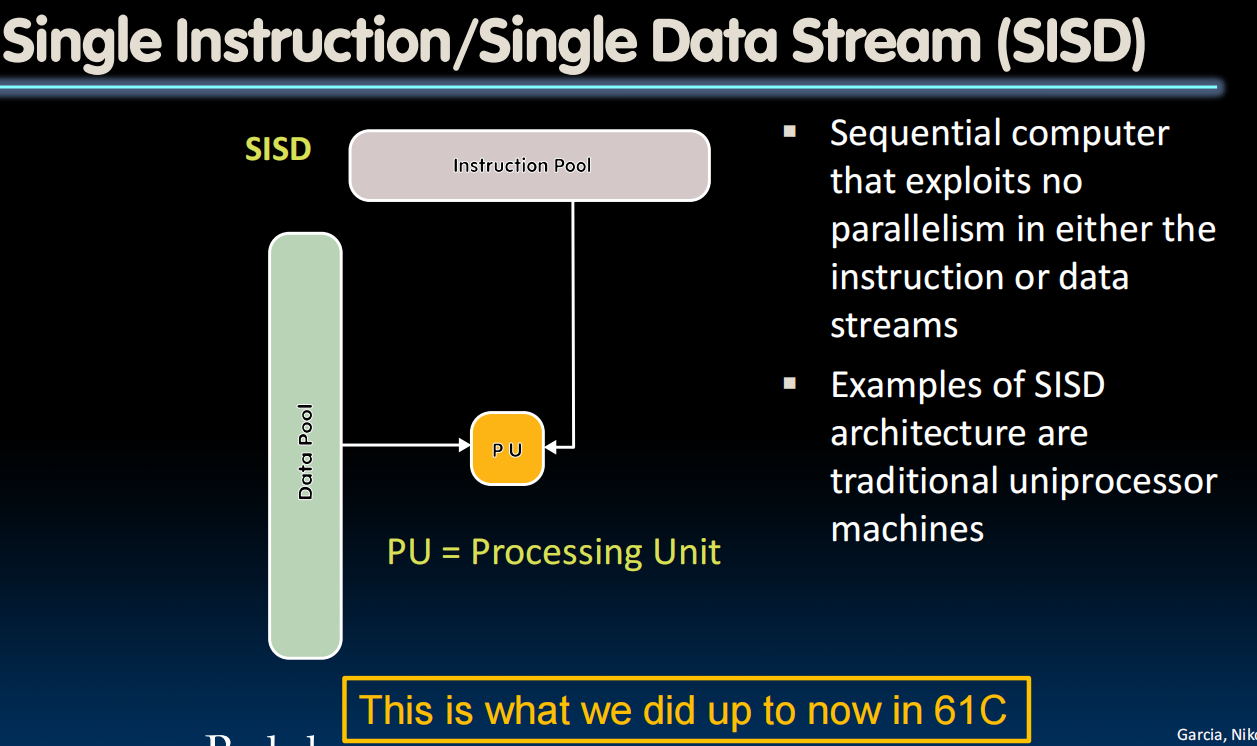
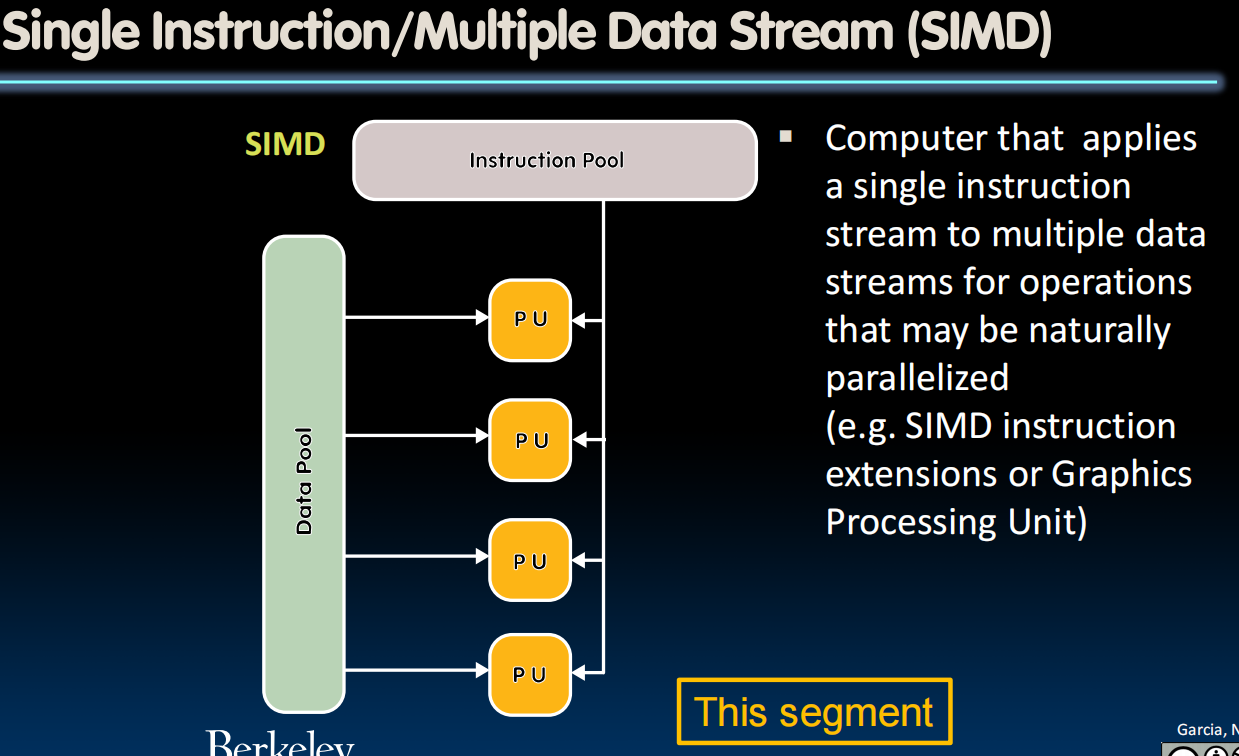
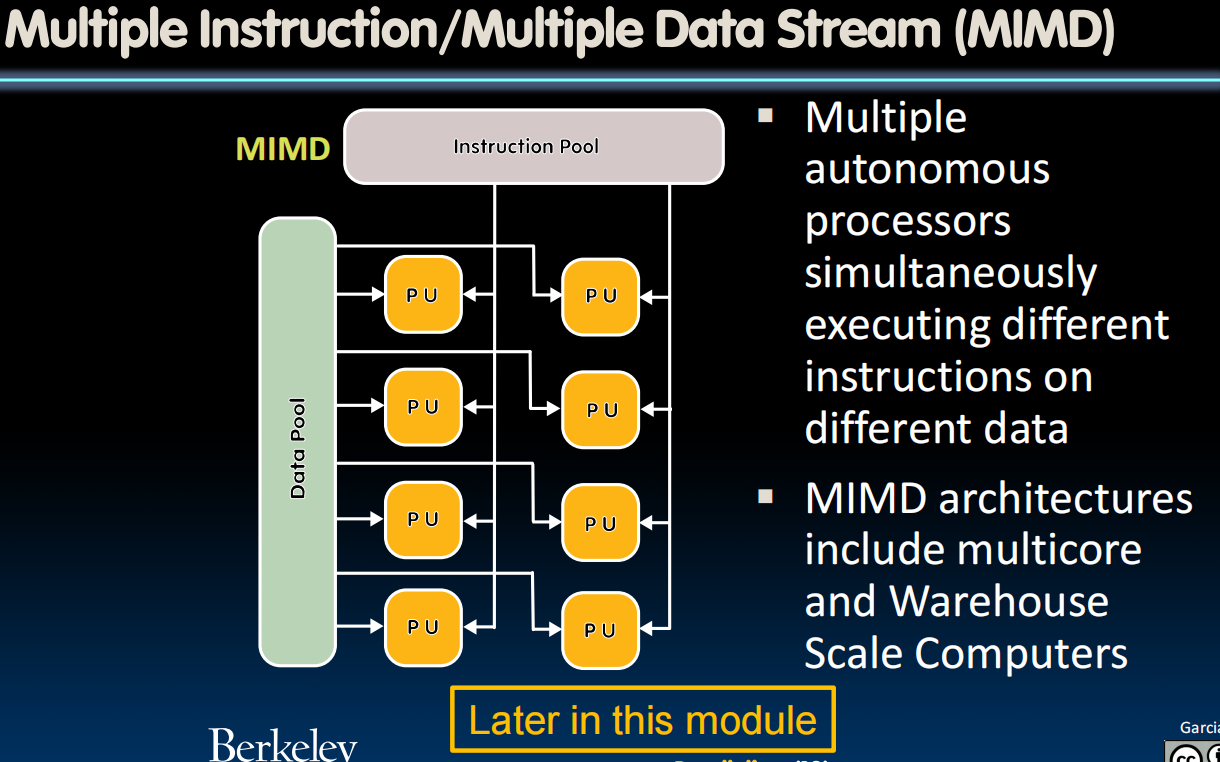
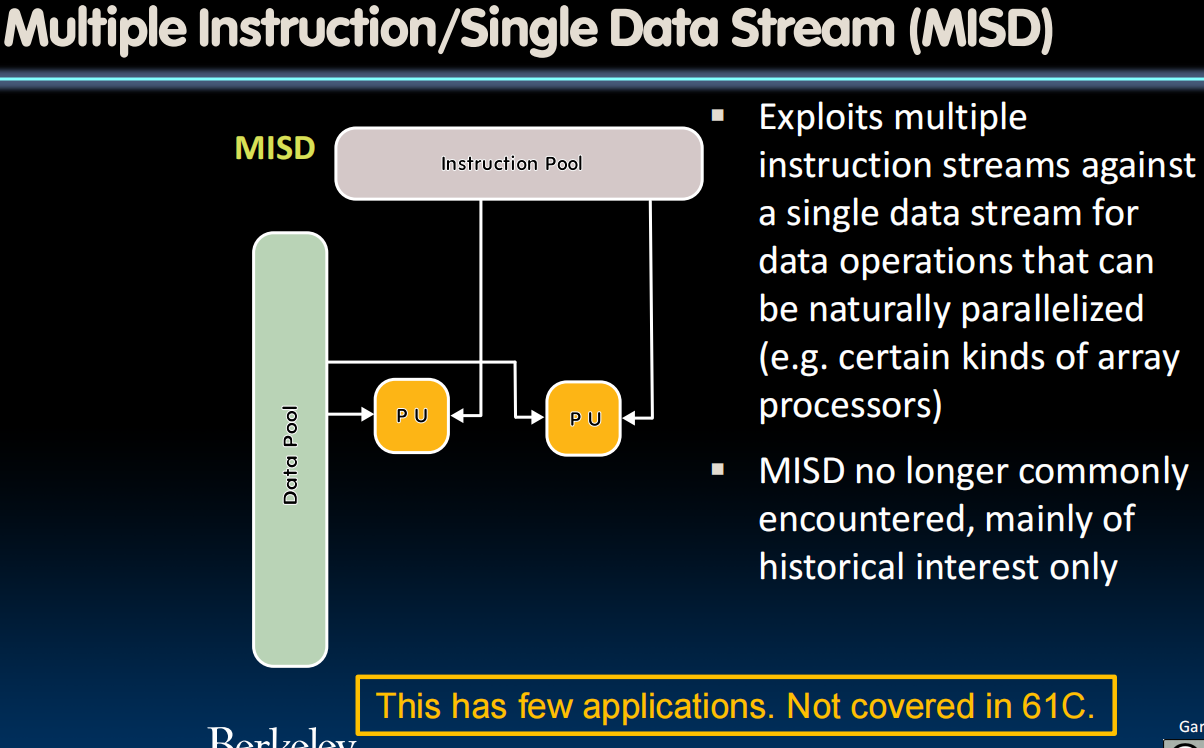
SIMD Architectures

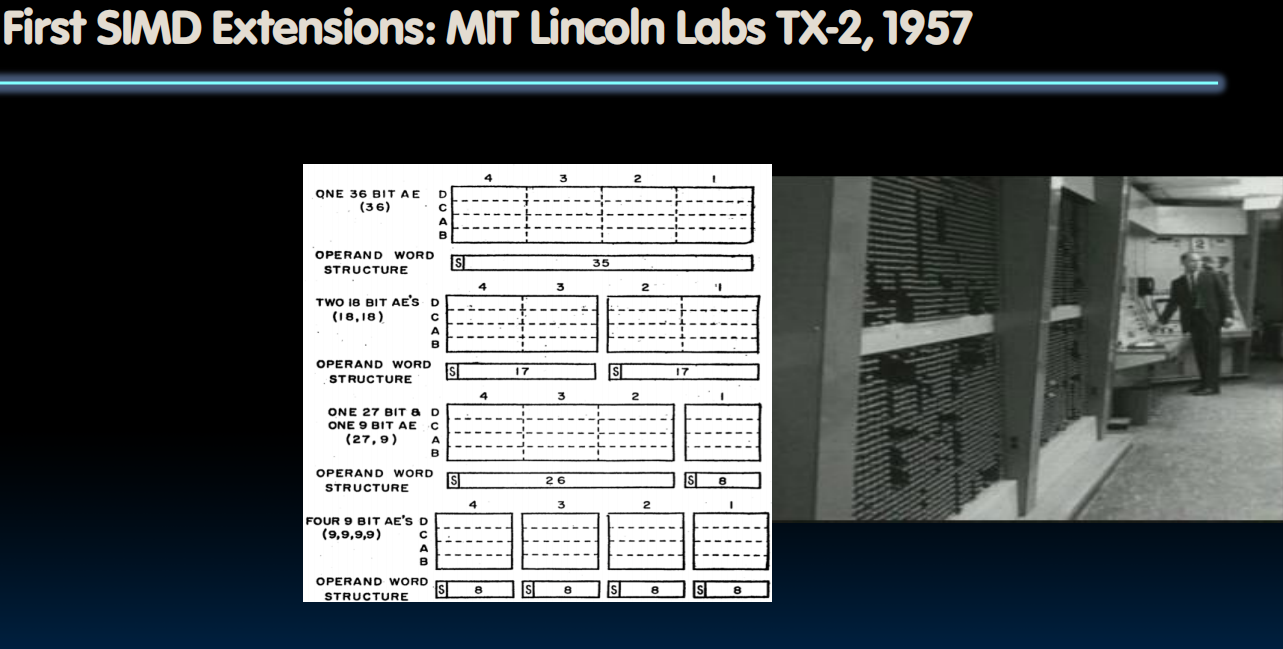


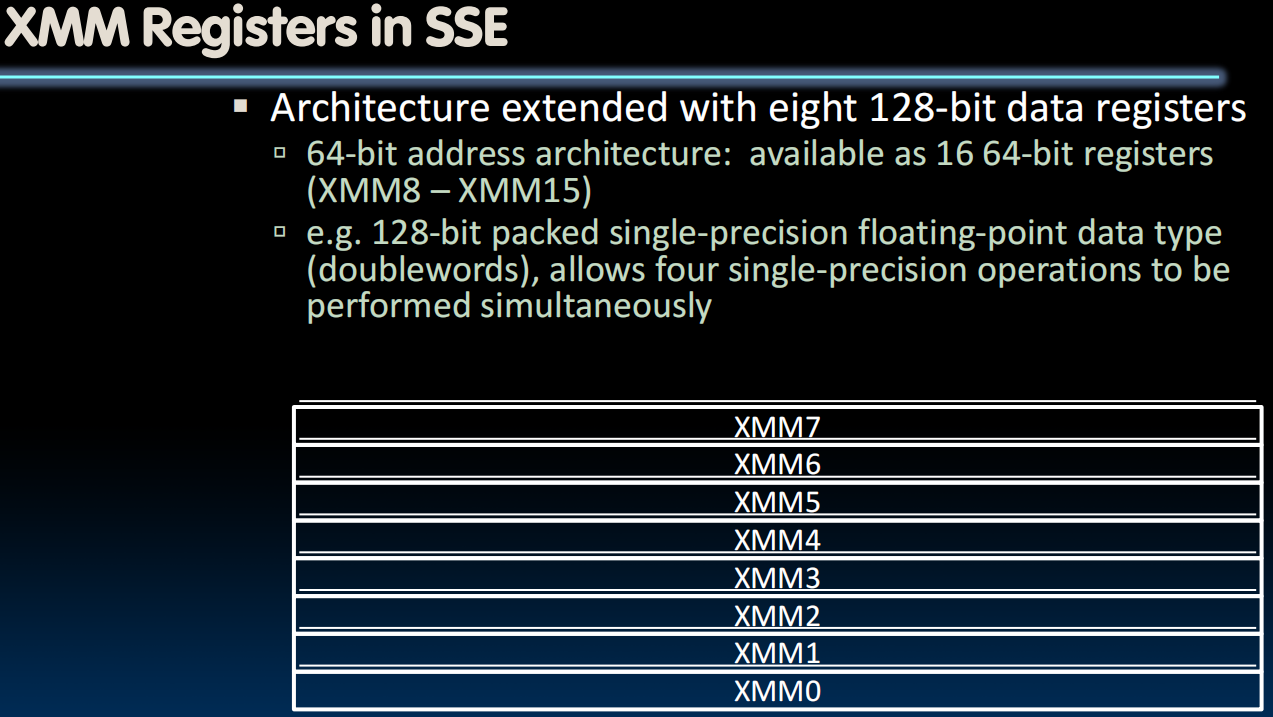


SIMD Array Processing



Matrix Multiply Example

#include <stdio.h>
// header file for SSE compiler intrinsics
#include <emmintrin.h> // SSE2 指令集头文件
// NOTE: vector registers will be represented in
//comments as v1 = [ a | b]
// where v1 is a variable of type __m128d and a, b are doubles
int main(void) {
// allocate A,B,C aligned on 16-byte boundaries
double A[4] __attribute__ ((aligned (16))); // 16 字节对齐
double B[4] __attribute__ ((aligned (16)));
double C[4] __attribute__ ((aligned (16)));
int lda = 2;
int i = 0;
// declare several 128-bit vector variables
__m128d c1,c2,a,b1,b2;
// Initialize A, B, C for example
/* A = (note column order!)
1 0
0 1
*/
A[0] = 1.0; A[1] = 0.0; A[2] = 0.0; A[3] = 1.0;
/* B = (note column order!)
1 3
2 4
*/
B[0] = 1.0; B[1] = 2.0; B[2] = 3.0; B[3] = 4.0;
/* C = (note column order!)
0 0
0 0
*/
C[0] = 0.0; C[1] = 0.0; C[2] = 0.0; C[3] = 0.0;
// used aligned loads to set // c1 = [c_11 | c_21]
c1 = _mm_load_pd(C+0*lda); // c2 = [c_12 | c_22]
c2 = _mm_load_pd(C+1*lda);
for (i = 0; i < 2; i++) { /* a =
i = 0: [a_11 | a_21]
i = 1: [a_12 | a_22]
*/
a = _mm_load_pd(A+i*lda); /* b1 =
i = 0: [b_11 | b_11]
i = 1: [b_21 | b_21]
*/
b1 = _mm_load1_pd(B+i+0*lda); /* b2 =
i = 0: [b_12 | b_12]
i = 1: [b_22 | b_22]
*/
b2 = _mm_load1_pd(B+i+1*lda);
/* c1 =
i = 0: [c_11 + a_11*b_11 | c_21 + a_21*b_11]
i = 1: [c_11 + a_21*b_21 | c_21 + a_22*b_21]
*/
c1 = _mm_add_pd(c1,_mm_mul_pd(a,b1));
/* c2 =
i = 0: [c_12 + a_11*b_12 | c_22 + a_21*b_12]
i = 1: [c_12 + a_21*b_22 | c_22 + a_22*b_22]
*/
c2 = _mm_add_pd(c2,_mm_mul_pd(a,b2));
}
// store c1,c2 back into C for completion
_mm_store_pd(C+0*lda,c1);
_mm_store_pd(C+1*lda,c2);
// print C
printf("%g,%g\n%g,%g\n",C[0],C[2],C[1],C[3]);
return 0;
}
Conclusion
- Flynn Taxonomy of Parallel Architectures
- SIMD: Single Instruction Multiple Data
- MIMD: Multiple Instruction Multiple Data
- SISD: Single Instruction Single Data
- MISD: Multiple Instruction Single Data (unused)
- Intel AVX SIMD Instructions
- One instruction fetch that operates on multiple operands simultaneousl
- 512/256/128/64-bit AVX registers
- Use C intrinsics
Lecture 33 (Thread-level Parallelism 1)
Parallel Computer Architectures
Improving Performance
- Increase clock rate
- Reached practical maximum for today’s technology
- < 5GHz for general purpose computers
- Lower CPI (cycles per instruction)
- SIMD, “instruction level parallelism”
- Perform multiple tasks simultaneously
- Multiple CPUs, each executing different program
- Tasks may be related
- E.g. each CPU performs part of a big matrix multiplication
- or unrelated
- E.g. distribute different web http requests over different computers
- E.g. run pptx (view lecture slides) and browser (youtube) simultaneously
- Do all of the above:
- High , SIMD, multiple parallel tasks
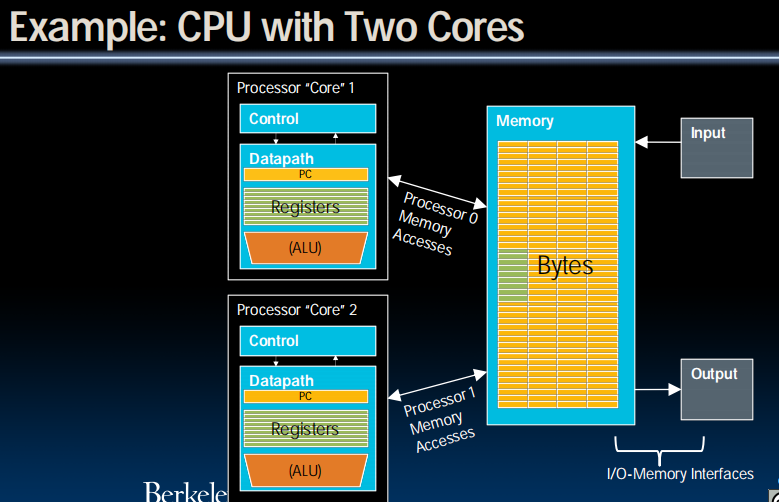
Multiprocessor Execution Model
- Each processor (core) executes its own instructions
-
Separate
resources (not shared) - Datapath (PC, registers, ALU) - Highest level caches (e.g., 1st and 2nd) -
Shared
resourcecs - Memory (DRAM) - Often 3rd level cache - Often on same silicon chip - But not a requirement - Nomenclature
- “Multiprocessor Microprocessor”
- Multicore processor
- E.g., four core CPU (central processing unit)
- Executes four different instruction streams simultaneously
Multicore
Multiprocessor Execution Model
- Shared memory
- Each “core” has access to the entire memory in the processor
- Special hardware keeps caches consistent (next lecture!)
- Advantages:
- Simplifies communication in program via shared variables
- Drawbacks
- Does not scale well:
- “Slow” memory shared by many “customers” (cores)
- May become bottleneck (Amdahl’s Law)
- Does not scale well:
- Two ways to use a multiprocessor:
- Job-level parallelism
- Processors work on unrelated problems
- No communication between programs
- Partition work of single task between several cores
- E.g., each performs part of large matrix multiplication
- Job-level parallelism
Parallel Processing
- It's difficult
- It's inevitable
- Only path to increase performance
- Only path to energy consumption (improve battery life)
- In mobile systems (e.g., smart phones, tablets)
- Multiple cores
- Dedicated processors, e.g.,
- Motion processor, image processor, neural processor in iPhone 8 + X
- GPU (graphics processing unit)
- Warehouse-scale computers (next week!)
- Multiple “nodes”
- “Boxes” with several CPUs, disks per box
- MIMD (multi-core) and SIMD (e.g. AVX) in each node
- Multiple “nodes”
Threads
Programs Running on a typical Computer
unix% ps -xThreads


Thoughts about Threads
“Although threads seem to be a small step from sequential computation, in fact, they represent a huge step. They discard the most essential and appealing properties of sequential computation: understandability, predictability, and determinism. Threads, as a model of computation, are wildly non-deterministic, and the job of the programmer becomes one of pruning that nondeterminism.”
— The Problem with Threads, Edward A. Lee, UC Berkeley, 2006
Operating System Threads
Give illusion of many “simultaneously” active threads
- Multiplex software threads onto hardware threads:
a) Switch out blocked threads (e.g., cache miss, user input, network access)
b) Timer (e.g., switch active thread every 1 ms)避免某个线程stall造成的cost(可以优先执行该线程的其他部分)
- Remove a software thread from a hardware thread by
a) Interrupting its execution
b) Saving its registers and PC to memory - Start executing a different software thread by
a) Loading its previously saved registers into a hardware thread’s registers
b) Jumping to its saved PC

Multithreading
Multithreading
- Typical scenario:
- Active thread encounters cache miss
- Active thread waits ~ 1000 cycles for data from DRAM switch out and run different thread until data available
- Problem
-
Must save current thread state and load new thread state
- PC, all registers (could be many, e.g. AVX)
must perform switch in ≪ 1000 cycles
-
- Can hardware help?
- Moore’s Law: transistors are plenty
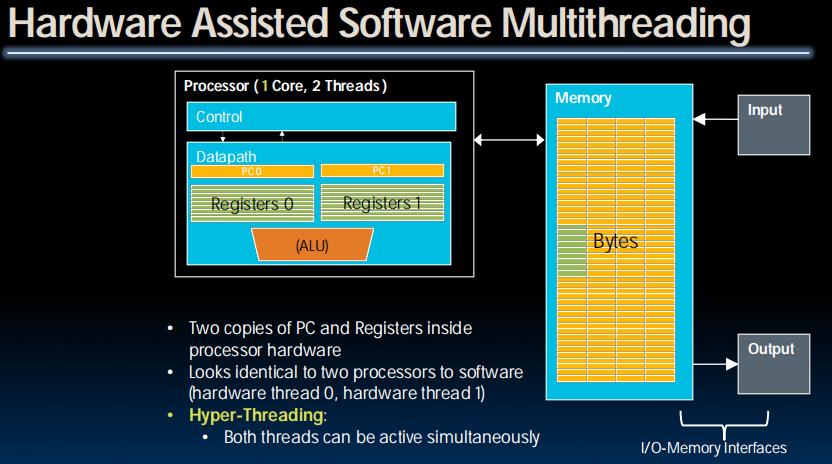
one core, two threads

Multithreading
- Logical threads
- ≈ 1% more hardware
- ≈ 10% (?) better performance
- Separate registers
- Share datapath, ALU(s), caches
- Multicore
- => Duplicate Processors
- 50% more hardware
- 2X better performance?
- Modern machines do both
- Multiple cores with multiple threads per core
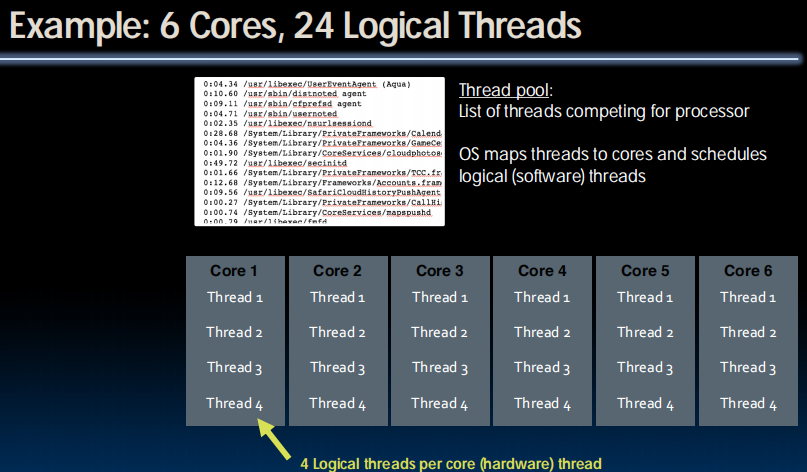
Review: Definitions
- Thread Level Parallelism
- Thread: sequence of instructions, with own program counter and processor state (e.g., register file)
- Multicore:
- Physical CPU: One thread (at a time) per CPU, in software OS switches threads typically in response to I/O events like disk read/write
- Logical CPU: Fine-grain thread switching, in hardware, when thread blocks due to cache miss/memory access
- Hyper-Threading aka Simultaneous Multithreading(SMT): Exploit superscalar architecture to launch instructions from different threads at the same time!
Conclusion
- Sequential software execution speed is limited
- Clock rates flat or declining
- Parallelism the only path to higher performance
- SIMD: instruction level parallelism
- Implemented in all high perf. CPUs today (x86, ARM, …)
- Partially supported by compilers
- 2X width every 3-4 years
- MIMD: thread level parallelism
- Multicore processors
- Supported by Operating Systems (OS)
- Requires programmer intervention to exploit at single program level (we see later)
- Add 2 cores every 2 years (2, 4, 6, 8, 10, …)
- Intel Xeon W- • 3275: 28 Cores, 56 Threads
- SIMD & MIMD for maximum performance
- SIMD: instruction level parallelism
- Key challenge: craft parallel programs with high performance on multiprocessors as # of processors increase – i.e., that scale
- Scheduling, load balancing, time for synchronization, overhead communication
Lecture 34 (Thread-level Parallelism 2)
Parallel Programming Languages
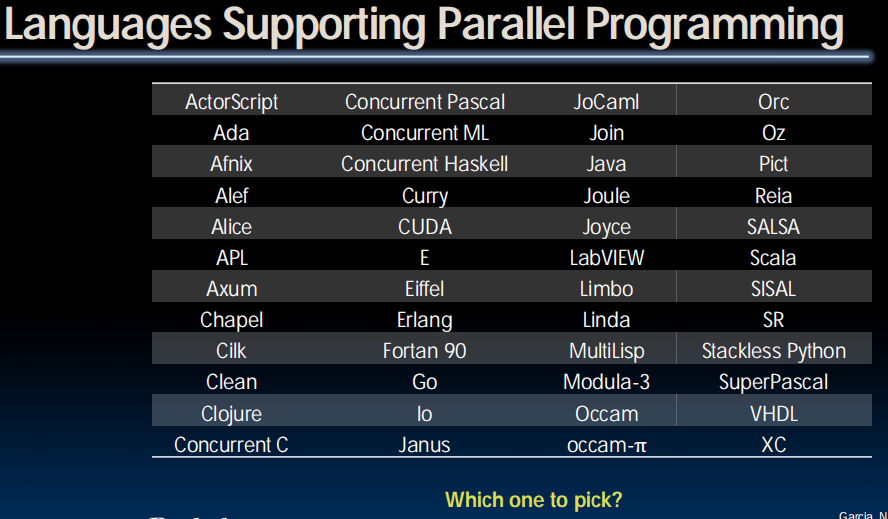
Why So Many Parallel Programming Languages?
- Why “intrinsics”?
- TO Intel: fix your #()&$! compiler, thanks…
- It’s happening ... but
- SIMD features are continually added to compilers (Intel, gcc)
- Intense area of research
- Research progress:
- 20+ years to translate C into good (fast!) assembly
- How long to translate C into good (fast!) parallel code?
- General problem is very hard to solve
- General problem is very hard to solve
- Your opportunity to become famous!
Parallel Programming Languages
- Number of choices is indication of
- No universal solution
- Needs are very problem specific
- E.g.,
- Scientific computing/machine learning (matrix multiply)
- Webserver: handle many unrelated requests simultaneously
- Input / output: it’s all happening simultaneously!
- No universal solution
- Specialized languages for different tasks
- Some are easier to use (for some problems)
- None is particularly “easy” to use
- 61C
- Parallel language examples for high-performance computing
- OpenMP
OpenMP
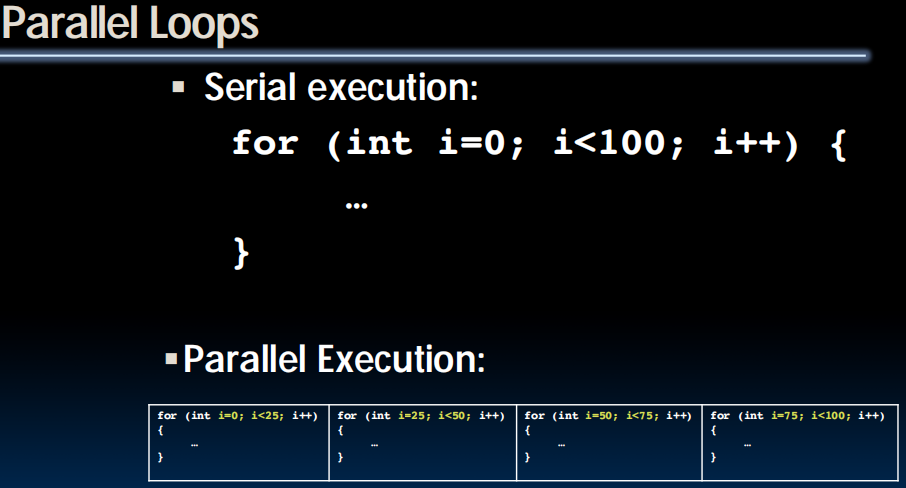
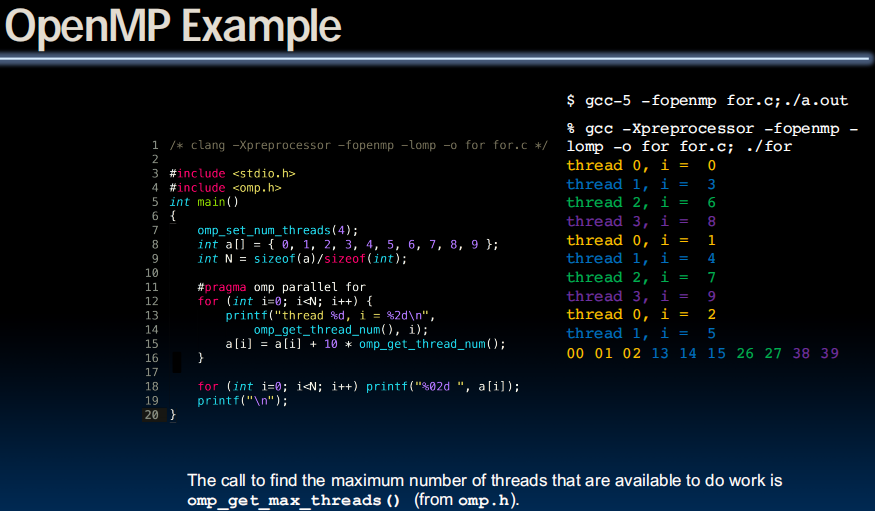
Parallel for in OpenMP
#include <omp.h>
#pragma omp parallel for
for (int i=0; i<100; i++) {
…
}
OpenMP
- C extension: no new language to learn
- Multi-threaded, shared-memory parallelism
- Compiler Directives, #pragma
- Runtime Library Routines, #include <omp.h>
- #pragma
- Ignored by compilers unaware of OpenMP
- Same source for multiple architectures
- E.g., same program for 1 & 16 cores
- Only works with shared memory
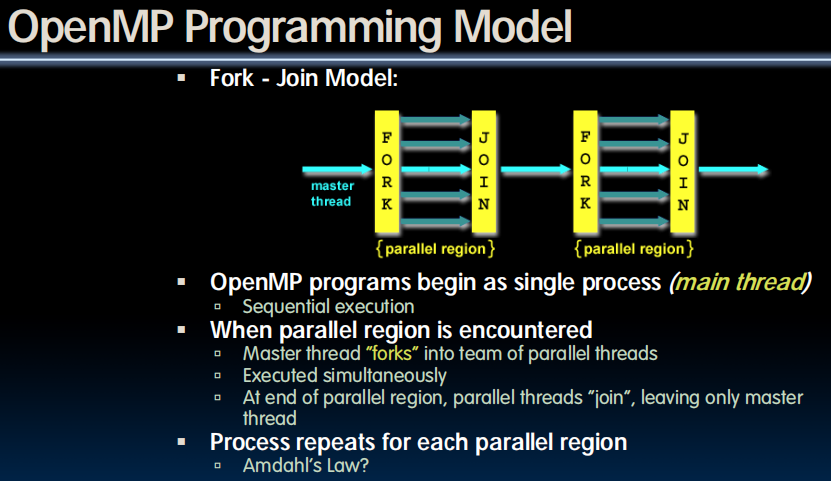
What Kind of Threads?
- OpenMP threads are operating system (software) threads
- OS will multiplex requested OpenMP threads onto available hardware threads
- Hopefully each gets a real hardware thread to run on, so no OS-level time-multiplexing
- But other tasks on machine compete for hardware threads!
- But other tasks on machine compete for hardware threads!
- 5AM?
- Job queue?
Computing

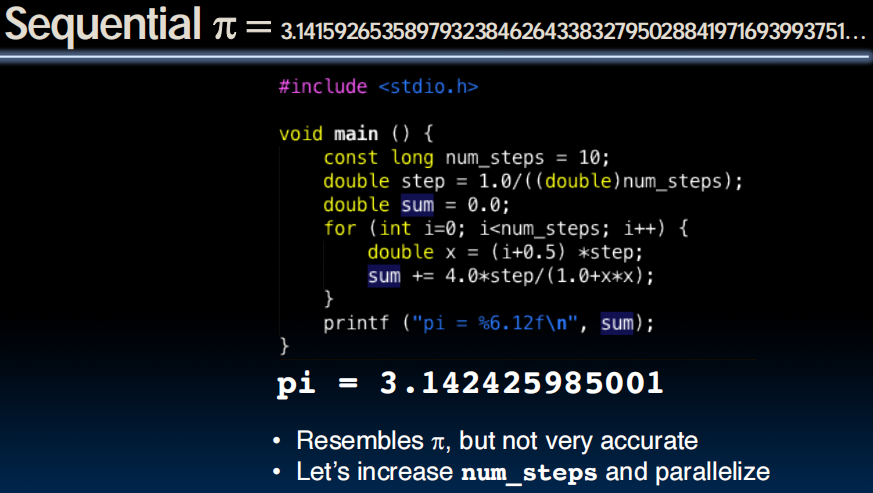
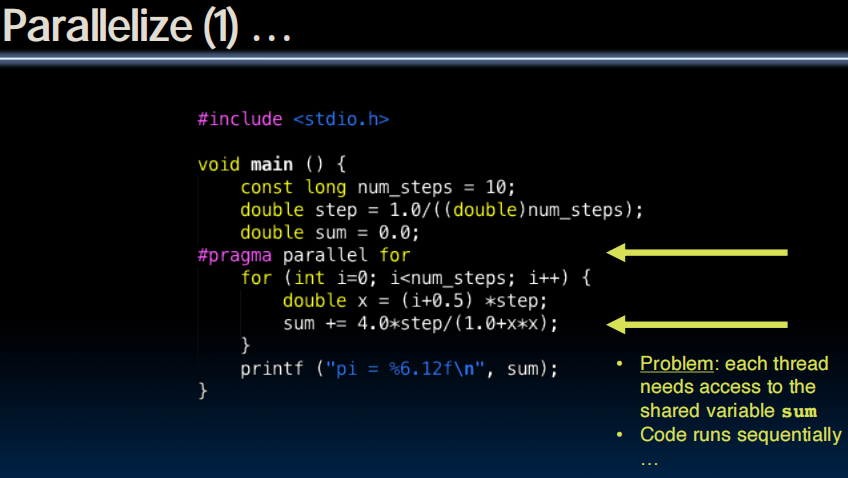
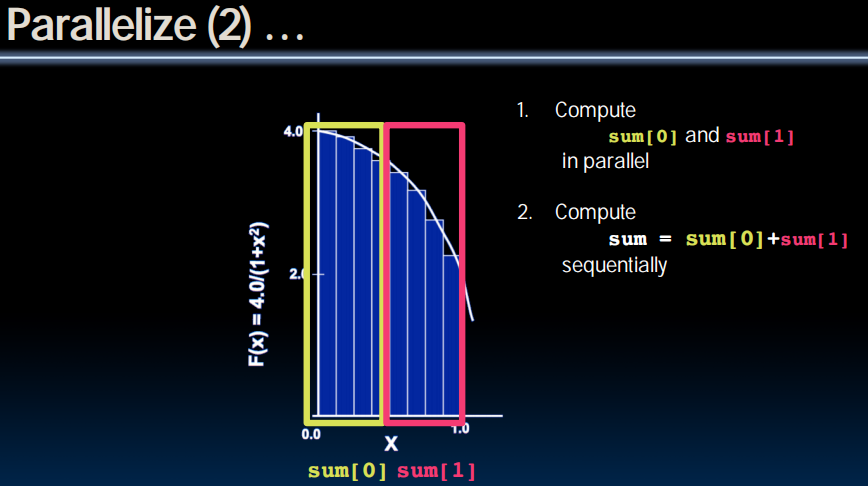
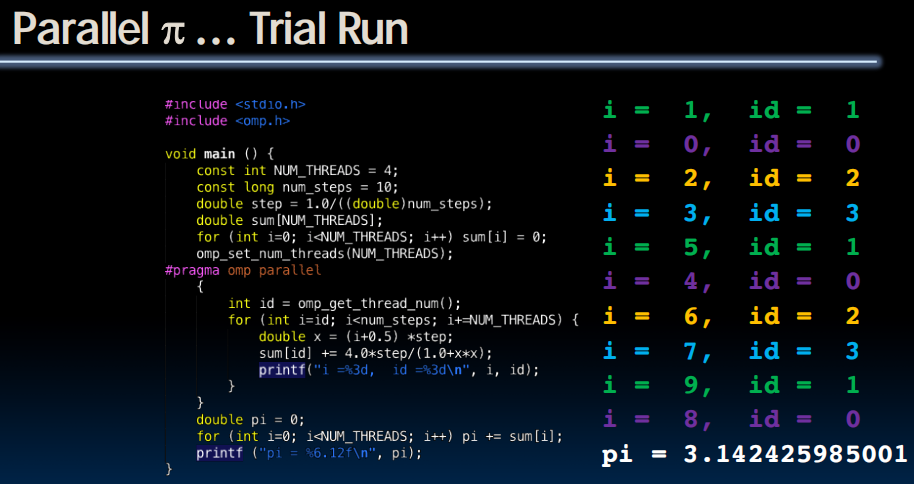
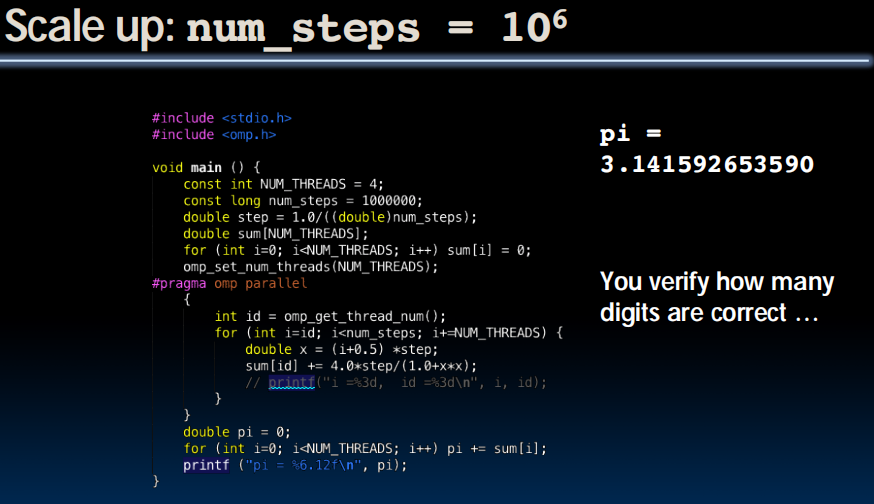
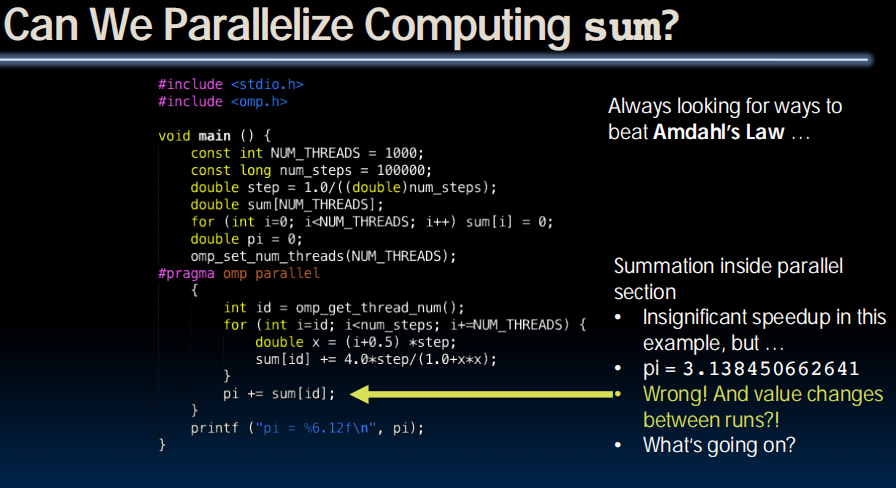
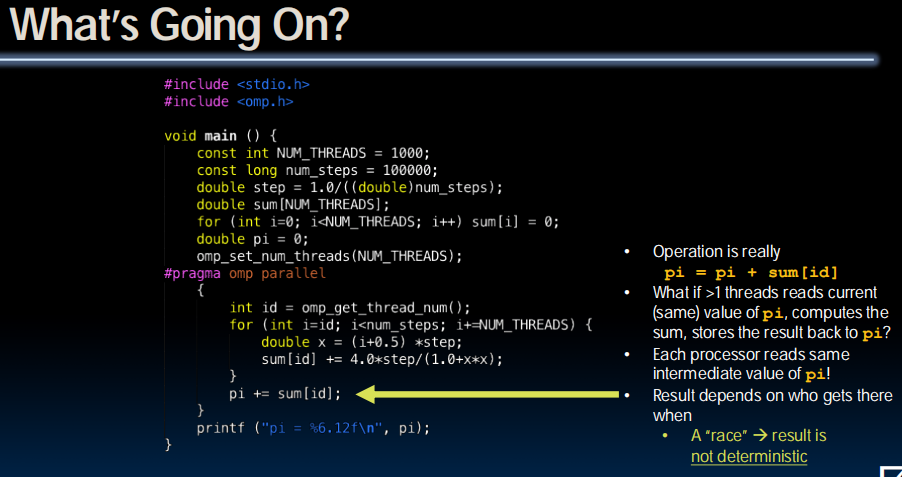
多线程同时访问pi,导致覆盖的发生。
solution: Lock
Synchronization

Locks
- Computers use locks to control access to shared resources
- Serves purpose of microphone in example
- Also referred to as “semaphore”
- Usually implemented with a variable
- int lock;
- 0 for unlocked
- 1 for locked
- int lock;
Synchronization with Locks
// wait for lock released
while (lock!=0);
// lock == 0 now (unlocked)
lock = 1;
// access shared resource ...
// e.g. pi
// sequential execution! (Amdahl ...)
// release lock
lock = 0;
Conclusion
- OpenMP as simple parallel extension to C
- Threads level programming with parallel for pragma
- ≈ C: small so easy to learn, but not very high level and it’s easy to get into trouble
- Race conditions – result of program depends on chance (bad)
- Need assembly-level instructions to help with lock synchronization
- …next time
Lecture 35 (Thread-level Parallelism 3)
Hardware Synchronization
Review: OpenMP Building Block: for loop
- OpenMP as simple parallel extension to C
- Threads level programming with parallel for pragma
- ≈ C: small so easy to learn, but not very high level and it’s easy to get into trouble
for (i=0; i<max; i++) zero[i] = 0;
- Breaks for loop into chunks, and allocate each to a separate thread
- e.g. if max = 100 with 2 threads:
assign 0-49 to thread 0, and 50-99 to thread 1
- e.g. if max = 100 with 2 threads:
- Must have relatively simple “shape” for an OpenMP-aware compiler to be able to parallelize it
- Necessary for the run-time system to be able to determine how many of the loop iterations to assign to each thread
- No premature exits from the loop allowed
- i.e. No break, return, exit, goto statements
In general, don’t jump outside of any pragma block
Review: Data Races and Synchronization
- Two memory accesses form a data race if from different threads access same location, at least one is a write, and they occur one after another
- If there is a data race, result of program varies depending on chance (which thread first?)
- Avoid data races by synchronizing writing and reading to get deterministic behavior
- Synchronization done by user-level routines that rely on hardware synchronization instructions
Hardware Synchronization
- Solution:
- Atomic read/write
- Read & write in single instruction
- No other access permitted between read and write
- Note:
- Must use shared memory (multiprocessing)
- Common implementations:
- Atomic swap of register ↔ memory
- Pair of instructions for “linked” read and write
- write fails if memory location has been “tampered” with after linked read
- RISC-V has variations of both, but for simplicity we will focus on the former
RISC-V Atomic Memory Operations (AMOs)

rd 得到 rs1指向的初始值, rs1指向的值更新为 *rs1 + rs2
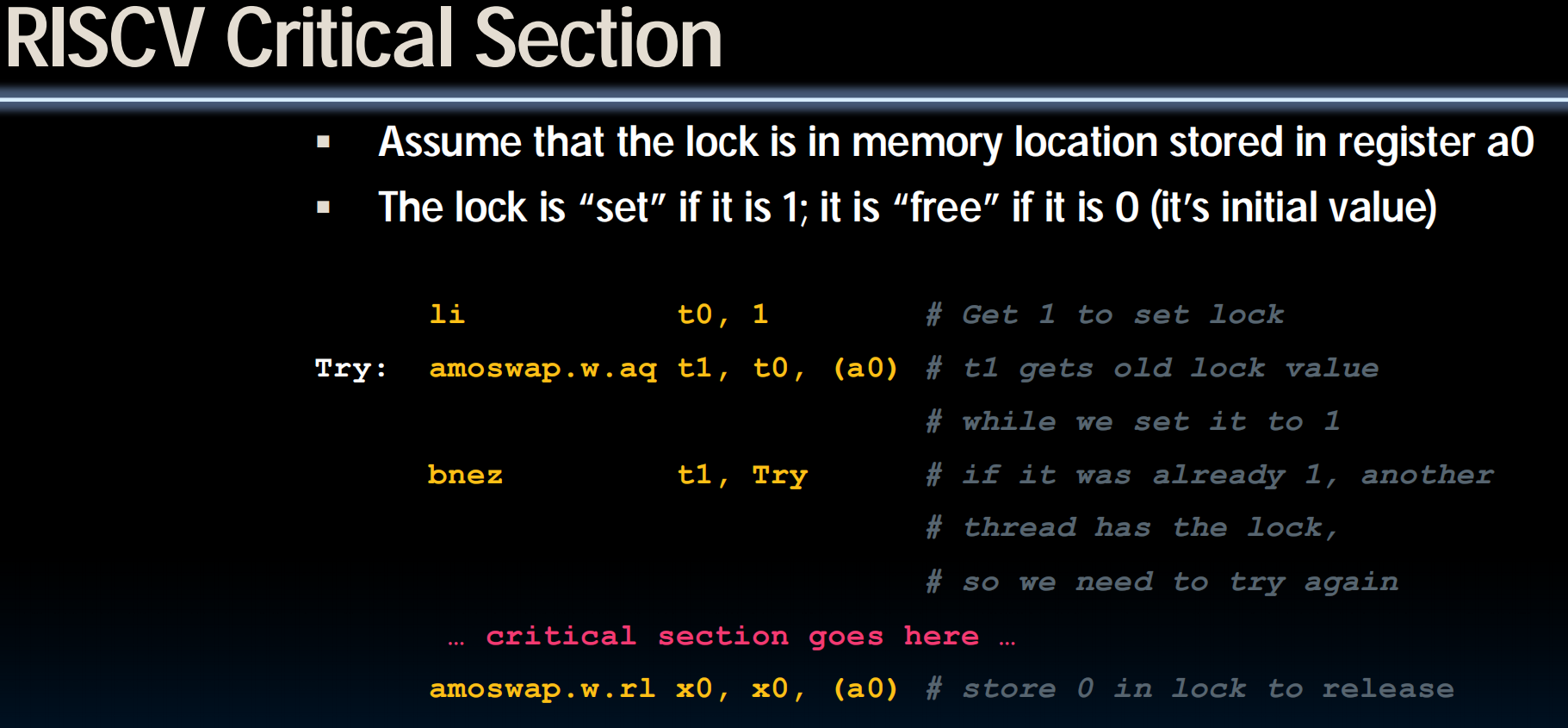
发生在atomic尺度,不会有锁的冲突
Lock Synchronization

OpenMP Locks
#include <stdio.h>
#include <stdlib.h>
#include <omp.h>
int main(void){
opm_lock_t lock;
omp_init_lock(&lock);
#pragma omp parallel
{
int id = omp_get_thread_num();
// parallel section
// ...
omp_set_lock(&lock);
// start sequential section
// ...
printf("id = %d\n", id);
// end sequential section
omp_unset_lock(&lock);
// parallel section
// ...
}
omp_destory_lock(&lock);
}Synchronization in OpenMP
- Typically are used in libraries of higher level parallel programming constructs
- E.g. OpenMP offers #pragmas for common cases:
- critical
- atomic
- barrier
- ordered
- OpenMP offers many more features
- E.g., private variables, reductions
- See online documentation
- Or tutorial at
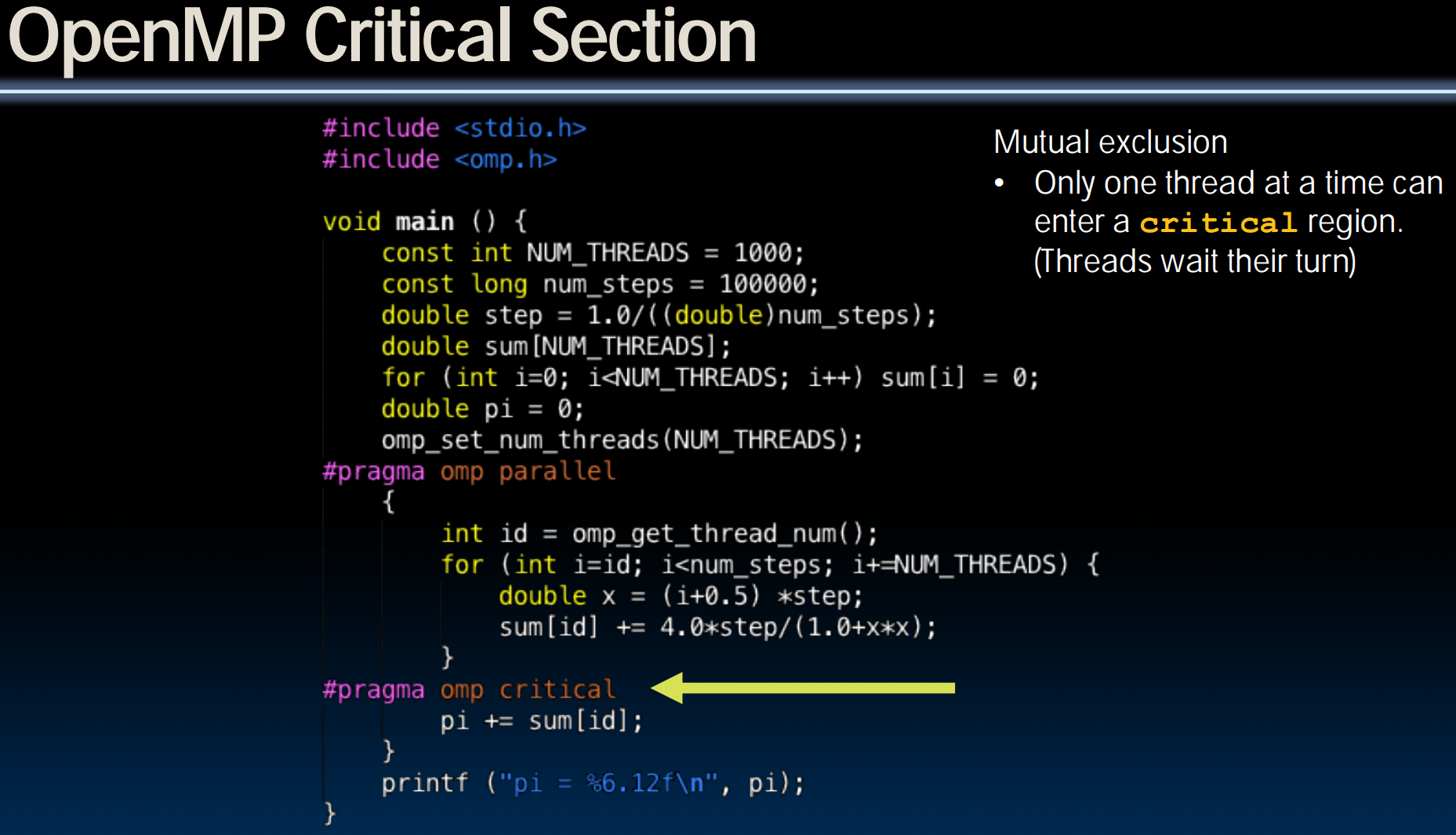

线程之间互相等待的状况,整体停滞
OpenMP Timing
- Elapsed wall clock time:
double omp_get_wtime(void);- Returns elapsed wall clock time in seconds
- Time is measured per thread, no guarantee can be made that two distinct threads measure the same time
- Time is measured from “some time in the past”, so subtract results of two calls to omp_get_wtime to get elapsed time
Shared Memory and Caches
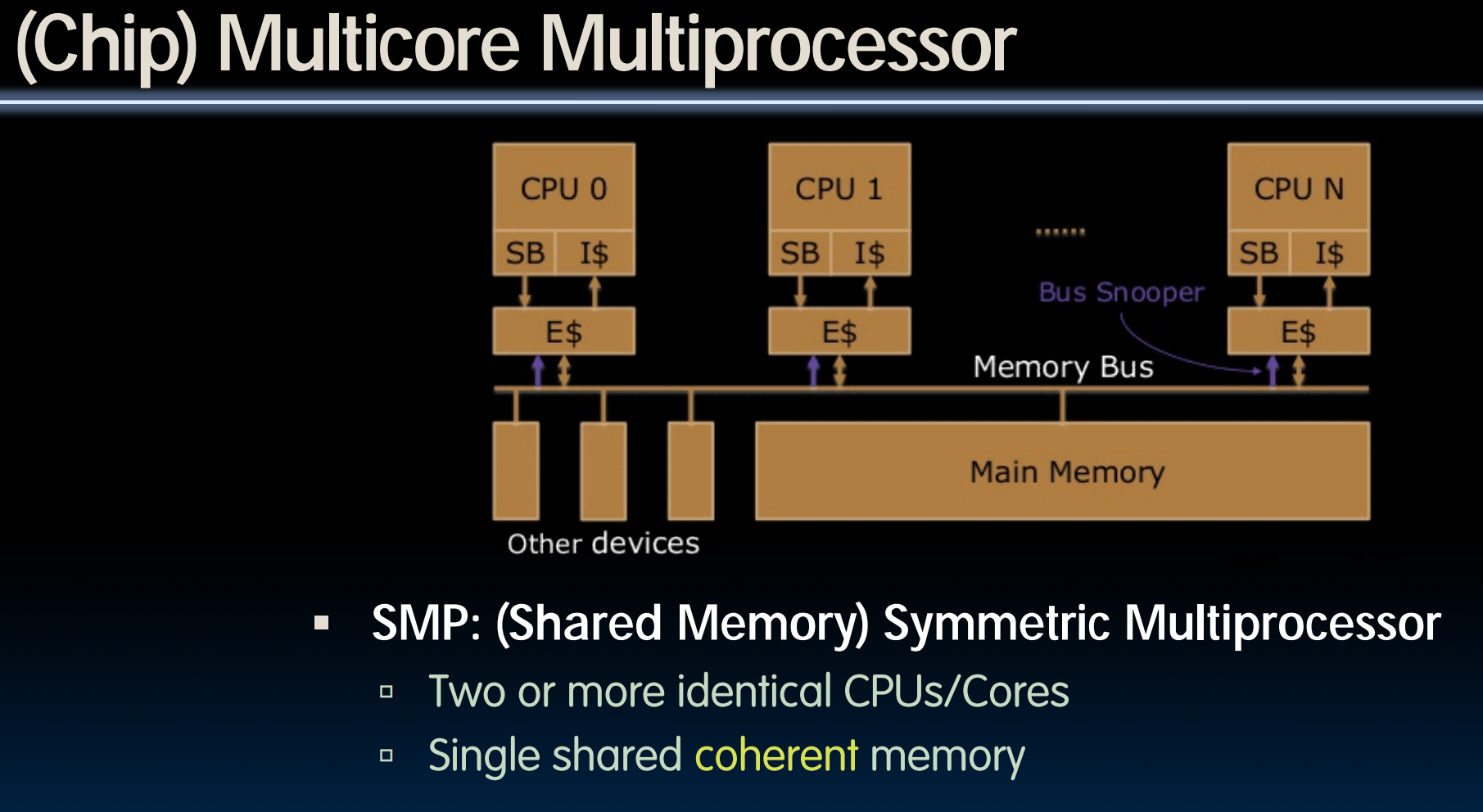
Multiprocessor Key Questions
- Q1 – How do they share data?
- Q2 – How do they coordinate?
- Q3 – How many processors can be supported?
Shared Memory Multiprocessor (SMP)
- Q1 – Single address space shared by all processors/cores
- Q2 – Processors coordinate/communicate through shared variables in memory (via loads and stores)
- Use of shared data must be coordinated via synchronization primitives (locks) that allow access to data to only one processor at a time
- All multicore computers today are SMP

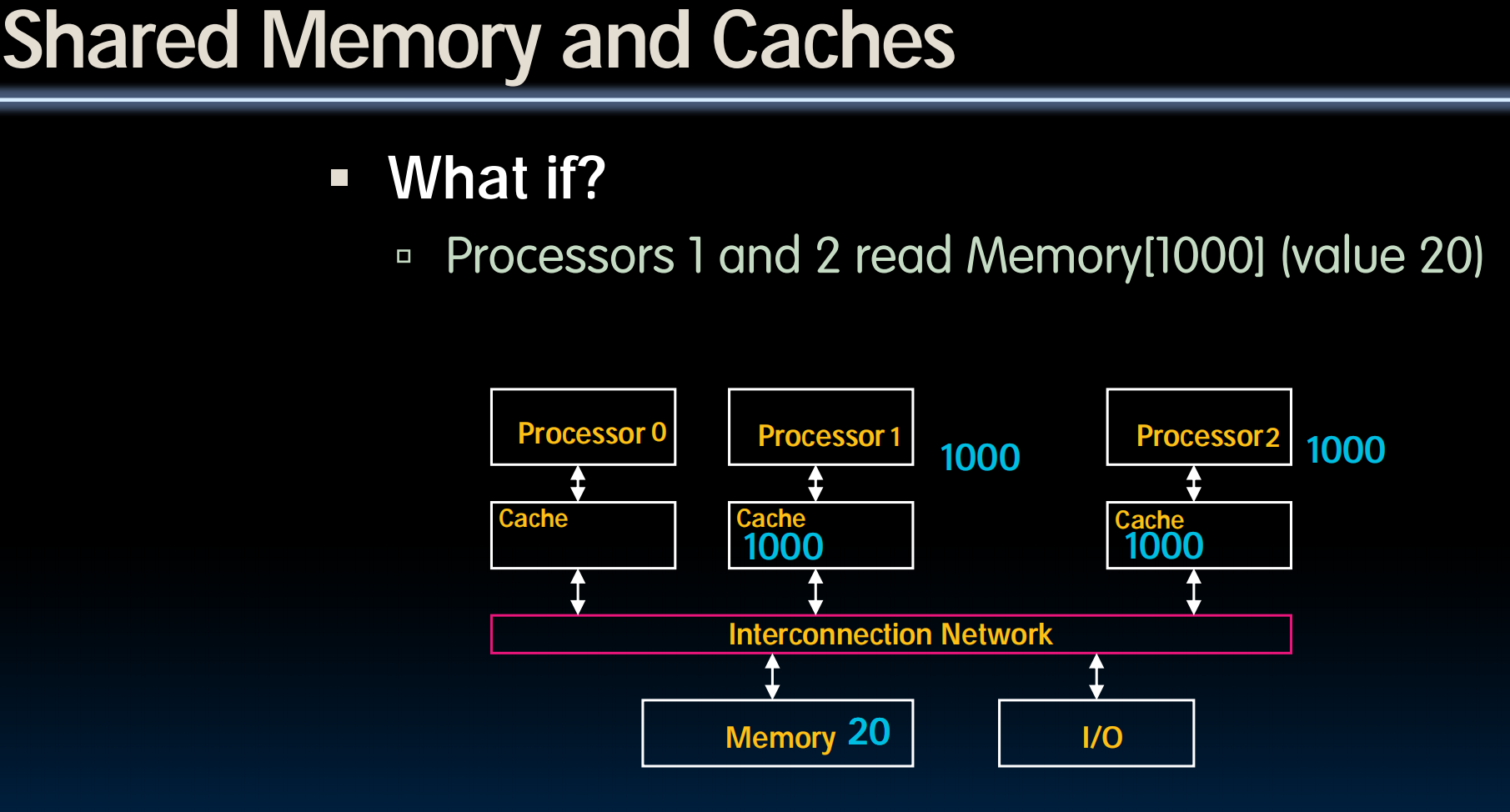

Cache Coherency
Keeping Multiple Caches Coherent
- Architect’s job: shared memory keep cache values coherent
- Idea: When any processor has cache miss or writes, notify other processors via interconnection network
- If only reading, many processors can have copies
- If a processor writes, invalidate any other copies (snoopy protocol)
- Write transactions from one processor, other caches “snoop” the common interconnect checking for tags they hold
- Invalidate any copies of same address modified in other cache
将block分为几种states
How Does HW Keep $ Coherent?
- Each cache tracks state of each block in cache:
- Shared: up-to-date data, other caches may have a copy
- Modified: up-to-date data, changed (dirty), no other cache has a copy, OK to write, memory out-of-date (i.e., write back)
Two Optional Performance Optimizations of Cache Coherency via New States
-
Each cache tracks state of each block in cache:
- Exclusive: up-to-date data, no other cache has a copy, OK to write, memory up-to-date
- Avoids writing to memory if block replaced
- Supplies data on read instead of going to memory
- Owner: up-to-date data, other caches may have a copy (they must be in Shared state)
- This cache is one of several with a valid copy of the cache line, but has the exclusive right to make changes to it. It must broadcast those changes to all other caches sharing the line. The introduction of owned state allows dirty sharing of data, i.e., a modified cache block can be moved around various caches without updating main memory. The cache line may be changed to the Modified state after invalidating all shared copies, or changed to the Shared state by writing the modifications back to main memory. Owned cache lines must respond to a snoop request with data.
- Exclusive: up-to-date data, no other cache has a copy, OK to write, memory up-to-date


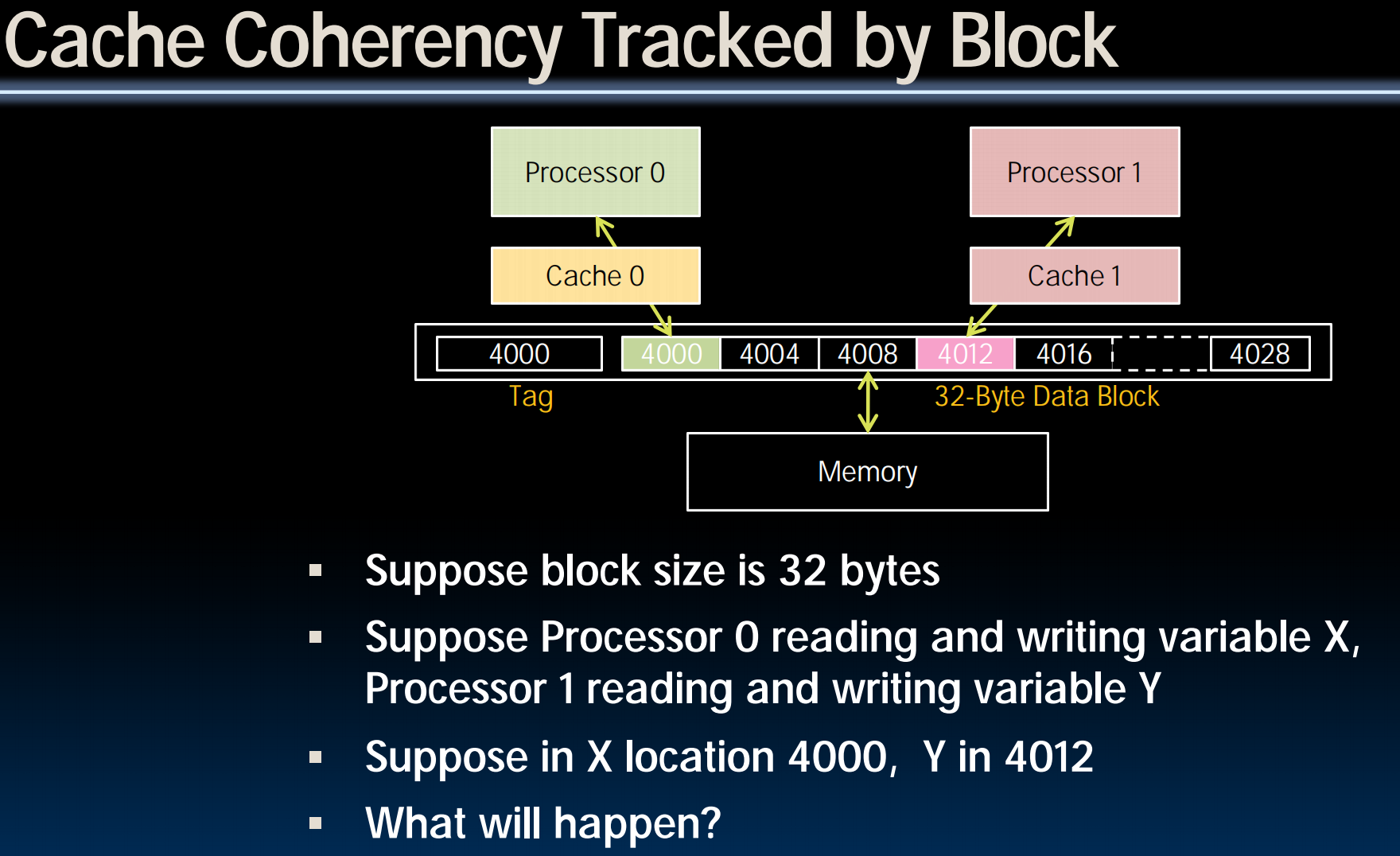
Coherency Tracked by Cache Block
- Block ping-pongs between two caches even though processors are accessing disjoint variables
- Effect called false sharing
- How can you prevent it?
solution: use smaller block
Remember The 3Cs?
- Compulsory (cold start or process migration, 1st reference):
- First access to block, impossible to avoid; small effect for long-running programs
- Solution: increase block size (increases miss penalty; very large blocks could increase miss rate)
- Capacity (not compulsory and…)
- Cache cannot contain all blocks accessed by the program even with perfect replacement policy in fully associative cache
- Solution: increase cache size (may increase access time)
- Conflict (not compulsory or capacity and…):
- Multiple memory locations map to the same cache location
- Solution 1: increase cache size
- Solution 2: increase associativity (may increase access time)
- Solution 3: improve replacement policy, e.g.. LRU
Fourth “C” of Cache Misses! Coherence Misses
- Misses caused by coherence traffic with other processor
- Also known as communication misses because represents data moving between processors working together on a parallel program
- For some parallel programs, coherence misses can dominate total misses
Conclusion
- OpenMP as simple parallel extension to C
- Threads level programming with parallel for pragma, private variables, reductions, …
- ≈ C: small so easy to learn, but not very high level and it’s easy to get into trouble
- TLP
- Cache coherency implements shared memory even with multiple copies in multiple caches
- False sharing a concern; watch block size!
Lecture 36 (MapRecude, Spark)
Amdanl's Law
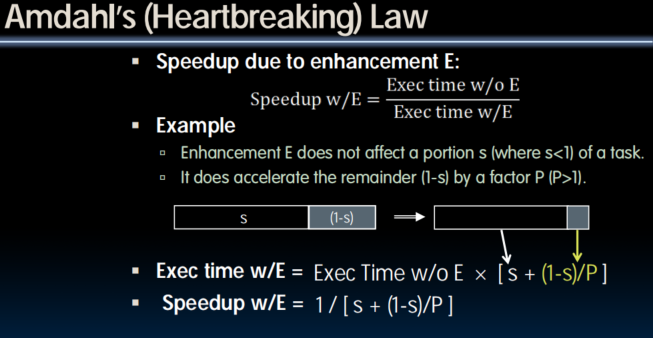

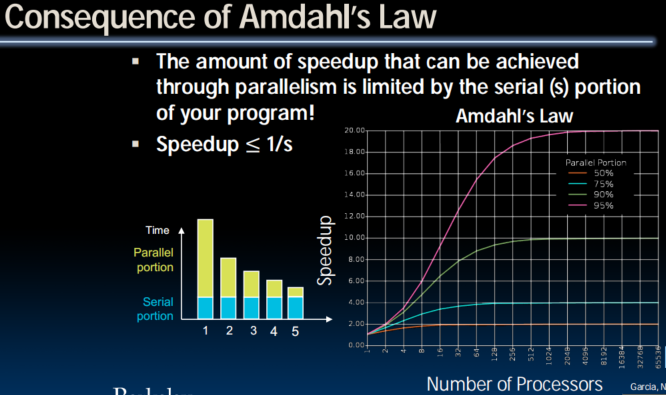
speedup被不可加速部分制约
Request-Level and Data-Level Parallelism
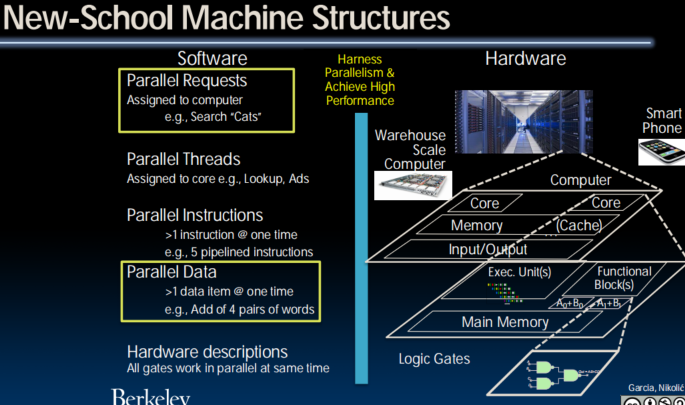
Request-Level Parallelism (RLP)
- Hundreds or thousands of requests/sec
- Not your laptop or cell-phone, but popular Internet services like web search, social networking, …
- Such requests are largely independent
- Often involve read-mostly databases
- Rarely involve strict read–write data sharing or synchronization across requests
- Computation easily partitioned within a request and across different requests
Data-Level Parallelism (DLP)
- Two kinds:
- Lots of data in memory that can be operated on in parallel (e.g. adding together 2 arrays)
- Lots of data on many disks that can be operated on in parallel (e.g. searching for documents)
- Today’s lecture: DLP across many servers and disks using MapReduce
MapReduce
What is MapReduce? (An abstraction)
- Simple data-parallel programming model designed for scalability and fault-tolerance
- Pioneered by Google
- Processes > 25 petabytes of data per day
- Open-source Hadoop project
- Used at Yahoo!, Facebook, Amazon, …
Hadoop
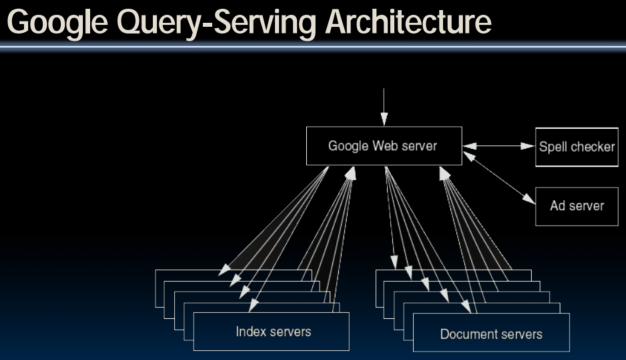
What is MapReduce used for?
- At Google:
- Index construction for Google Search
- Article clustering for Google News
- Statistical machine translation
- For computing multi-layer street maps
- At Yahoo!:
- “Web map” powering Yahoo! Search
- Spam detection for Yahoo! Mail
- At Facebook:
- Data mining
- Ad optimization
- Spam detection
MapReduce Design Goals
- Scalability to large data volumes:
- 1000’s of machines, 10,000’s of disks
- Cost-efficiency:
- Commodity machines (cheap, but unreliable)
- Commodity network
- Automatic fault-tolerance via re-execution (fewer administrators)
- Easy, fun to use (fewer programmers)
- Jeffrey Dean and Sanjay Ghemawat, “MapReduce: Simplified Data Processing on Large Clusters,” 6th USENIX Symposium on Operating Systems Design and Implementation, 2004.
- optional reading, linked on course homepage – a digestible CS paper at the 61C level
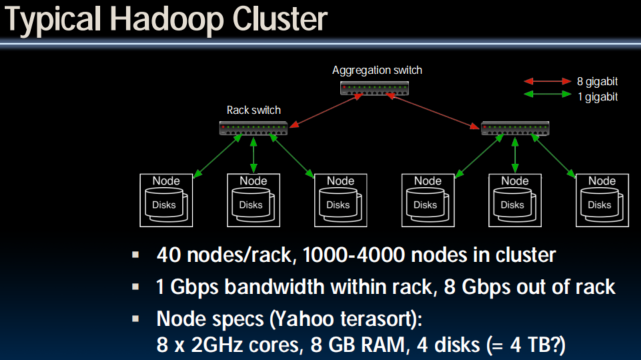
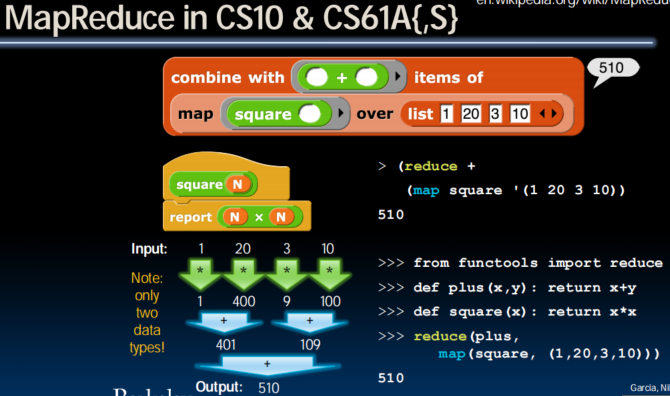
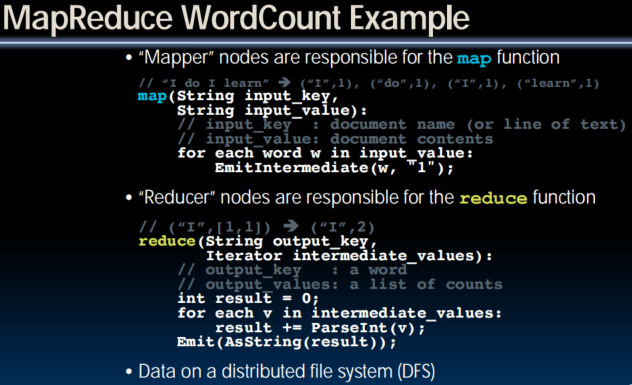
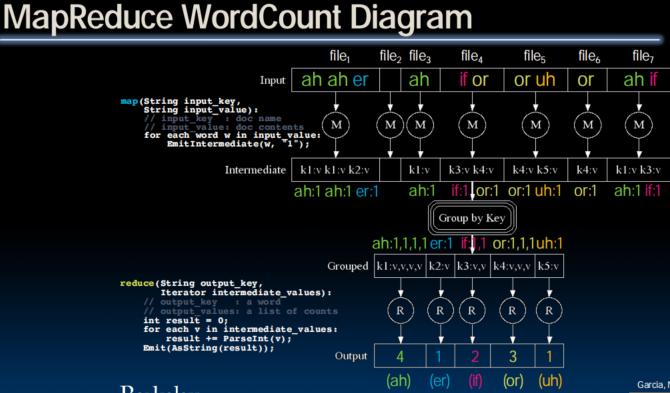
MapReduce Programming Model
Input & Output: each a set of key/value pairs (tagging 上 key 以更好地分发data)
Programmer specifies two functions:
map (in_key, in_value)
list(interm_key, interm_value)
- Processes input key/value pair
- Slices data into “shards” or “splits”; distributed to workers
- Produces set of intermediate pairs
reduce (interm_key, list(interm_value))
list(out_value)
- Combines all intermediate values for a particular key
- Produces a set of merged output values (usu just one)
code.google.com/edu/parallel/mapreduce-tutorial.html


Spark

DAG: Directed Acyclic Graph
Word Count in Spark’s Python API
file.flatMap(lambda line: line.split())
.map(lambda word: (word,1))
.reduceByKey(lambda a, b: a+b)flatMap in Spark’s Python API
def neighbor(n):
return [n-1, n, n+1]
R = sc.parallelize(range(5)) // sc: spark context
R.collect()
// [0, 1, 2, 3, 4]
R.map(neighbor).collect()
// [[-1, 0, 1], [0, 1, 2], [1, 2, 3], [2, 3, 4], [3, 4, 5]]
R.flatMap(neighbor).collect()
// [-1, 0, 1, 0, 1, 2, 1, 2, 3, 2, 3, 4, 3, 4, 5]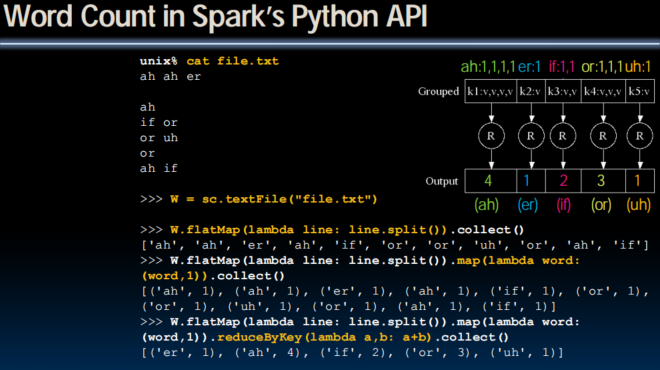
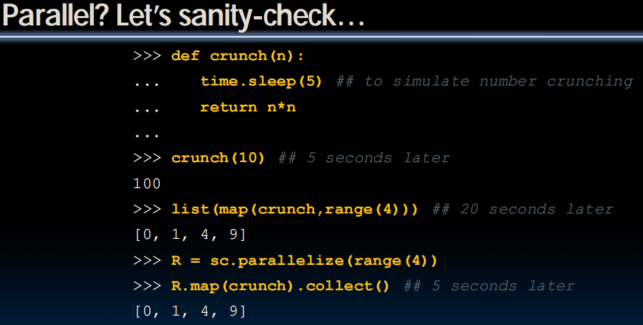
Conclusion
- 4th big idea is parallelism
- Amdahl’s Law constrains performance wins
- With infinite parallelism, Speedup = 1/s (s=serial %)
- MapReduce is a wonderful abstraction for programming thousands of machines
- Hides details of machine failures, slow machines
- File-based
- Spark does it even better
- Memory-based
- Lazy evaluation
Lecture 37 (Data Centers, Cloud Computing)
Eras of Computer Hardware
skip
Warehouse Scale Computer
Why Cloud Computing Now?
- “The Web Space Race”: Build-out of extremely large datacenters (10,000’s of commodity PCs)
- Build-out driven by growth in demand (more users)
- Infrastructure software and Operational expertise
- Discovered economy of scale: 5-7x cheaper than provisioning a medium-sized (1000 servers) facility
- More pervasive broadband Internet so can access remote computers efficiently
- Commoditization of HW & SW
- Standardized software stacks
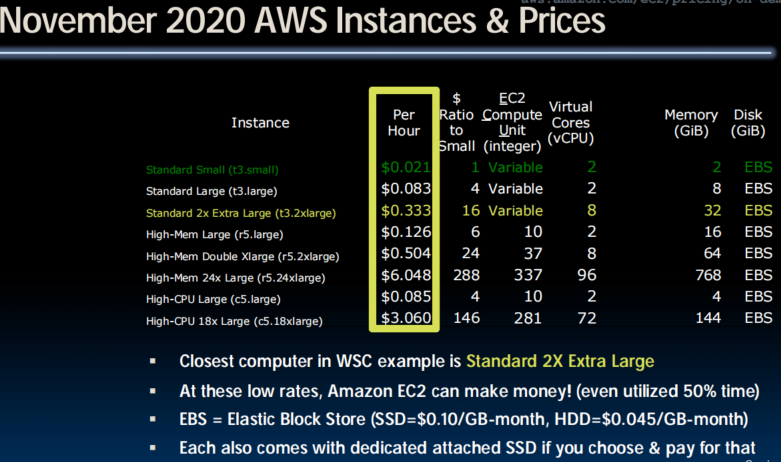
Warehouse Scale Computers
- Massive scale datacenters: 10,000 to 100,000 servers + networks to connect them together
- Emphasize cost-efficiency
- Attention to power: distribution and cooling
- (relatively) homogeneous hardware/software
- Offer very large applications (Internet services): search, social networking, video sharing
- Very highly available: < 1 hour down/year
- Must cope with failures common at scale
- “…WSCs are no less worthy of the expertise of computer systems architects than any other class of machines”
-Barroso and Hoelzle 2009
Design Goals of a WSC
- Unique to Warehouse-scale
- 充足的并行性(Ample Parallelism):
- Batch apps (批处理): large number independent data sets with independent processing.
- Also known as Data-Level Parallelism
- Scale and its Opportunities/Problems
- Relatively small number of these make design cost expensive and difficult to amortize. WSC 的架构设计复杂且成本高昂,但由于其部署次数有限(如全球仅有少数超大规模数据中心),难以通过大规模复制分摊设计成本。
- But price breaks are possible from purchases of very large numbers of commodity servers. 规模化采购优势:通过集中采购数万台商品化服务器(Commodity Servers),可大幅降低硬件单价(如获得厂商折扣)。
- Must also prepare for high # of component failures. 组件数量庞大(如数万块硬盘、CPU、内存条),导致硬件故障常态化(例如每天可能发生数十次磁盘故障)。
- Operational Costs Count (运营成本主导):
- Cost of equipment purchases << cost of ownership
- 充足的并行性(Ample Parallelism):
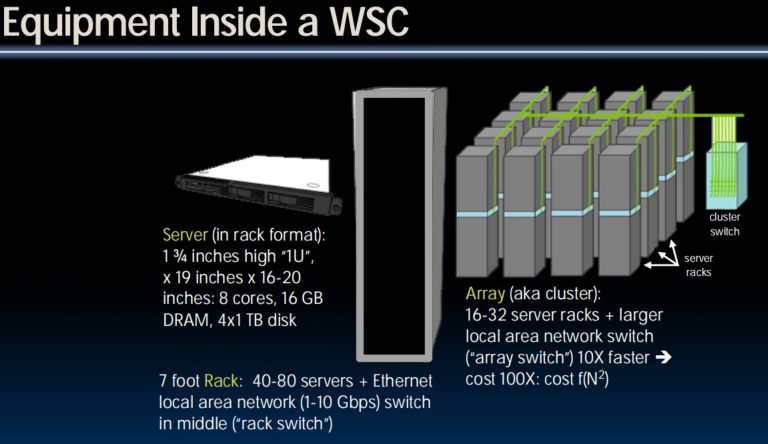
Defining Performance
- What does it mean to say X is faster than Y?
- 2009 Ferrari 599 GTB
- 2 passengers, 11.1 secs for quarter mile (call it 10sec)
- 2009 Type D school bus
- 54 passengers, quarter mile time? (let’s guess 1 min)
- Response Time or Latency
- time between start and completion of a task
- E.g., time to move vehicle ¼ mile
- Throughput or Bandwidth
- total amount of work in a given time
- E.g., passenger-miles in 1 hour

Power Usage Effectiveness (PUE)
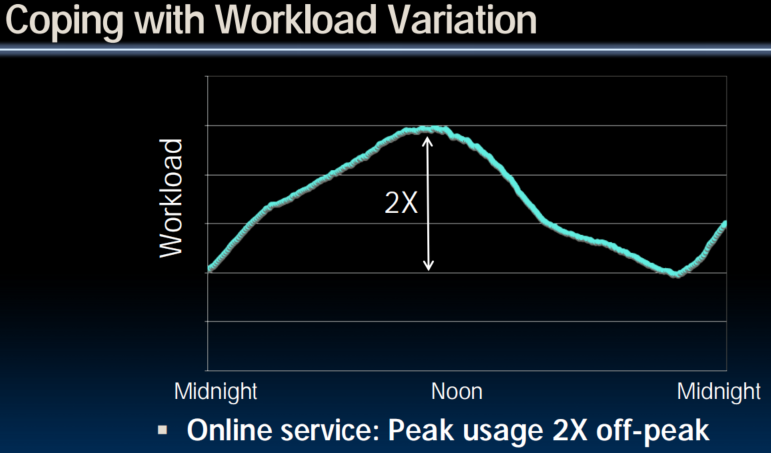
Impact of latency, bandwidth, failure, varying workload on WSC software?
- WSC Software must take care where it places data within an array to get good performance
- WSC Software must cope with failures gracefully
- WSC Software must scale up and down gracefully in response to varying demand
- More elaborate hierarchy of memories, failure tolerance, workload accommodation makes WSC software development more challenging than software for single computer

Power Usage Effectiveness
- Overall WSC Energy Efficiency: amount of computational work performed divided by the total energy used in the process
- Power Usage Effectiveness (PUE): Total building power / IT equipment power
- A power efficiency measure for WSC, not including efficiency of servers, networking gear
- 1.0 = perfection
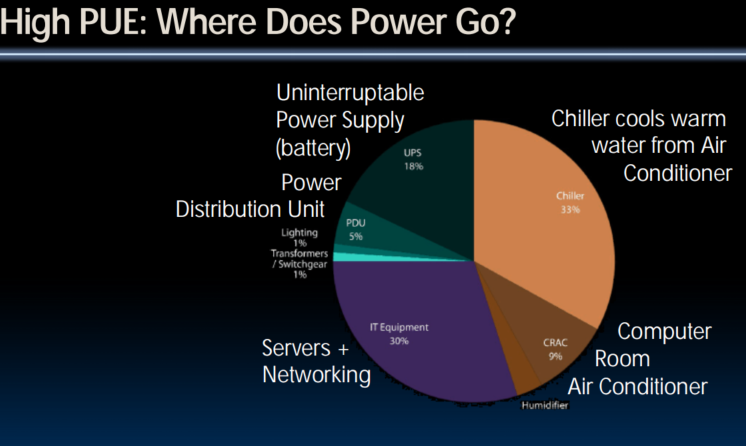
Google WSC A PUE: 1.24
- Careful air flow handling
- Don’t mix server hot air exhaust with cold air (separate warm aisle from cold aisle)
- Short path to cooling so little energy spent moving cold or hot air long distances
- Keeping servers inside containers helps control air flow
- Elevated cold aisle temperatures
- 81°F instead of traditional 65°- 68°F
- Found reliability OK if run servers hotter
- Use of free cooling
- Cool warm water outside by evaporation in cooling towers
- Locate WSC in moderate climate so not too hot or too cold
- Per-server 12-V DC UPS
- Rather than WSC wide UPS, place single battery per server board
- Increases WSC efficiency from 90% to 99%
- Measure vs. estimate PUE, publish PUE, and improve operation
Computing in the News
- 2011 (www.nytimes.com/2011/09/09/technology/google-details-and-defends-its-use-of-electricity.html)
- Google disclosed that it continuously uses enough electricity to power 200,000 homes, but it says that in doing so, it also makes the planet greener.
- Search cost per day (per person) same as running a 60-watt bulb for 3 hours
- 2018 (techcrunch.com/2018/04/04/google-matches-100-percent-of-its-power-consumption-with-renewables/)
- Google: “Over the course of 2017, across the globe, for every kilowatt-hour of electricity we consumed, we purchased a kilowatt-hour of renewable energy from a wind or solar farm that was built specifically for Google. This makes us the first public Cloud, and company of our size, to have achieved this feat”
Summary
- Parallelism is one of the Great Ideas
- Applies at many levels of the system – from instructions to warehouse scale computers
- Post PC Era: Parallel processing, smart phone to WSC
- WSC SW must cope with failures, varying load, varying HW latency bandwidth
- WSC HW sensitive to cost, energy efficiency
- WSCs support many of the applications we have come to depend on
Lecture 38 (Dependability)
6 Great Ideas in Computer Architecture
- Abstraction (Layers of Representation/Interpretation)
- Moore’s Law
- Principle of Locality/Memory Hierarchy
- Parallelism
- Performance Measurement & Improvement
- Dependability via Redundancy
We will discuss hardware failures and methods to mitigate them
Great Idea #6: Dependability via Redundancy
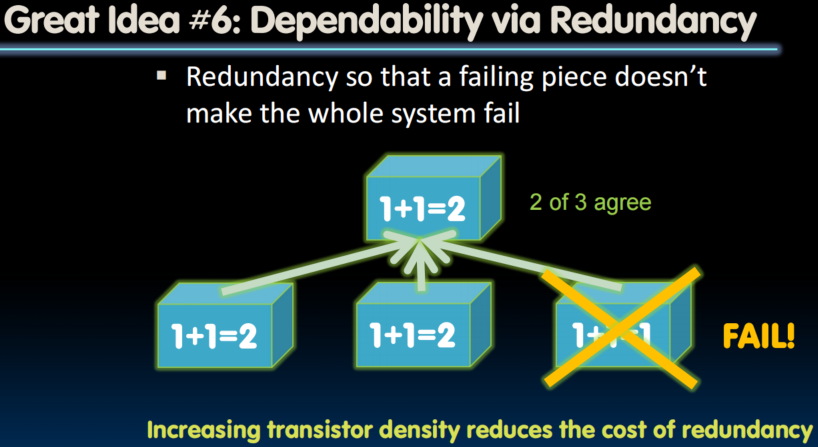

Dependability Metrics

Dependability via Redundancy: Time vs. Space
- Spatial Redundancy – replicated data or check information or hardware to handle hard and soft (transient) failures. (通过复制硬件、数据或校验信息实现冗余)
- Temporal Redundancy – redundancy in time (retry) to handle soft (transient) failures. (通过重复执行操作(重试)实现冗余)
Dependability Measures
- Reliability: Mean Time To Failure (MTTF)
- Service interruption: Mean Time To Repair (MTTR)
- Mean time between failures (MTBF)
- MTBF = MTTF + MTTR
- Availability = MTTF / (MTTF + MTTR)
- Improving Availability
- Increase MTTF: More reliable hardware/software + Fault Tolerance
- Reduce MTTR: improved tools and processes for diagnosis and repair
Availability Measures
- Availability = MTTF / (MTTF + MTTR) as %
- MTTF, MTBF usually measured in hours
- Since hope rarely down, shorthand is “number of 9s of availability per year”
- 1 nine: 90% => 36 days of repair/year
- 2 nines: 99% => 3.6 days of repair/year
- 3 nines: 99.9% => 526 minutes of repair/year
- 4 nines: 99.99% => 53 minutes of repair/year
- 5 nines: 99.999% => 5 minutes of repair/year
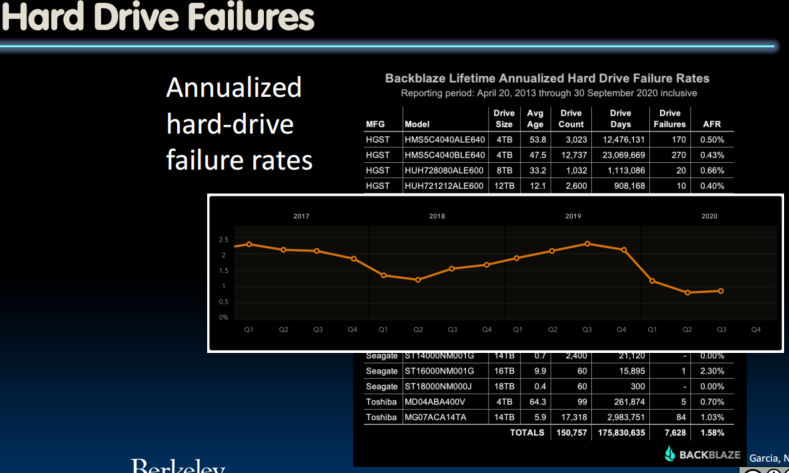
Reliability Measures
- Another is average number of failures per year: Annualized Failure Rate (AFR)
- E.g., 1000 disks with 100,000 hour MTTF
- 365 days * 24 hours = 8760 hours
- (1000 disks * 8760 hrs/year) / 100,000
= 87.6 failed disks per year on average - 87.6/1000 = 8.76% annual failure rate
- Google’s 2007 study* found that actual AFRs for individual drives ranged from 1.7% for first year drives to over 8.6% for three-year old drives
research.google.com/archive/disk_failures.pdf
Failures In Time (FIT) Rate
- The Failures In Time (FIT) rate of a device is the number of failures that can be expected in one billion ( ) device-hours of operation
- Or 1000 devices for 1 million hours, 1 million devices for 1000 hours each
- MTBF = 1,000,000,000 x 1/FIT
- Relevant: Automotive safety integrity level (ASIL) defines FT rates for different classes of components in vehicles
Dependability Design Principle
- Design Principle: No single points of failure
- “Chain is only as strong as its weakest link”
- Dependability corollary of Amdahl’s Law
- Doesn’t matter how dependable you make one portion of system
- Dependability limited by part you do not improve
Error Detection
Error Detection/Correction Codes
- Memory systems generate errors (accidentally flipped bits)
- DRAMs store very little charge per bit
- “Soft” errors occur occasionally when cells are struck by alpha particles or other environmental upsets
- “Hard” errors can occur when chips permanently fail
- Problem gets worse as memories get denser and larger
- Memories protected against soft errors with EDC/ECC
- Extra bits are added to each data-word
- Used to detect and/or correct faults in the memory system
- Each data word value mapped to unique code word
- A fault changes valid code word to invalid one, which can be detected



Error Detection and Correction
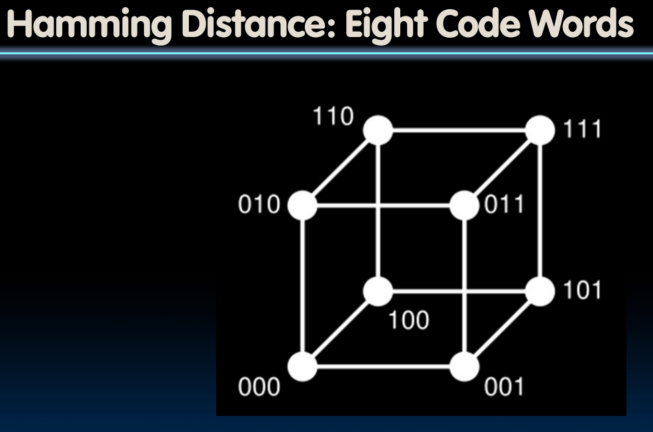
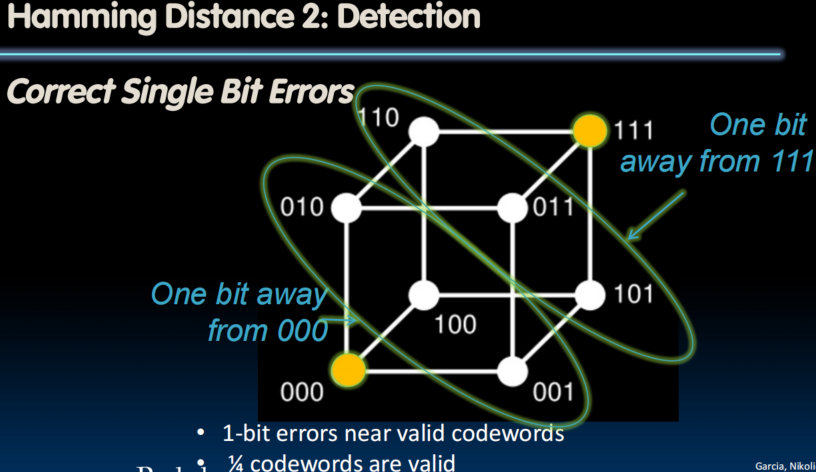
Suppose Want to Correct One Error?
- Hamming came up with simple to understand mapping to allow Error Correction at minimum distance of three
- Single error correction, double error detection
- Called “Hamming ECC”
- Worked weekends on relay computer with unreliable card reader, frustrated with manual restarting
- Got interested in error correction; published 1950
- R. W. Hamming, “Error Detecting and Correcting Codes,” The Bell System Technical Journal, Vol. XXVI, No 2 (April 1950) pp 147-160.


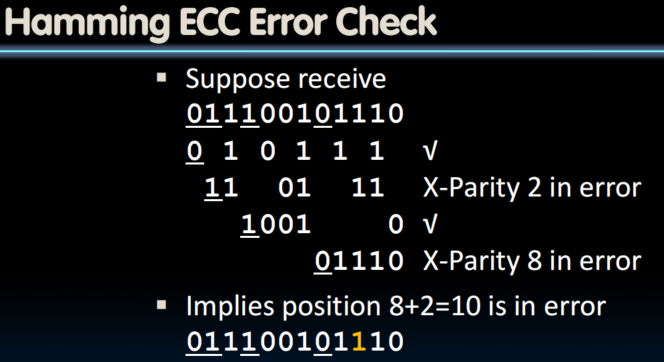
ECC Example

Set parity bits to create even parity for each group
- A byte of data: 10011010
- Create the coded word, leaving spaces for the parity bits:
- _ _ 1 _ 0 0 1 _ 1 0 1 0
1 2 3 4 5 6 7 8 9 a b c – bit position - Calculate the parity bits

- Final code word: 011100101010
- Data word: 1 001 1010


What if More Than 2-Bit Errors?
- Use double-error correction, triple-error detection (DECTED)
- Network transmissions, disks, distributed storage common failure mode is bursts of bit errors, not just one or two bit errors
- Contiguous sequence of B bits in which first, last and any number of intermediate bits are in error
- Caused by impulse noise or by fading in wireless
- Effect is greater at higher data rates
- Solve with Cyclic Redundancy Check (CRC), interleaving or other more advanced codes
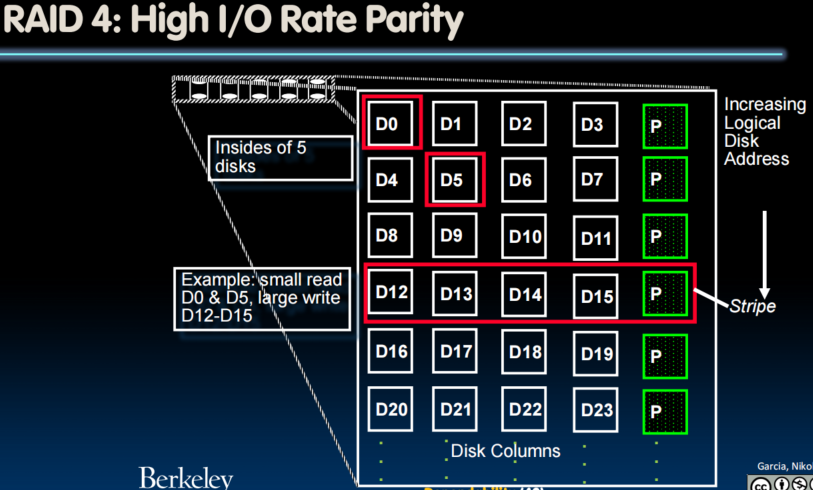
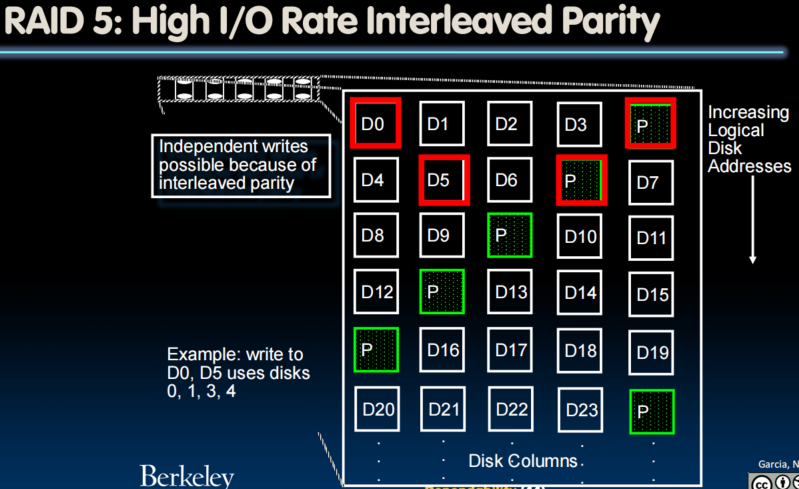
Redundancy with RAID
RAID: Redundant Arrays of (Inexpensive) Disks
- Data is stored across multiple disks
- Files are "striped" across multiple disks
- Redundancy yields high data availability
- Availability: service still provided to user, even if some components failed
- Disks will still fail
- Contents reconstructed from data redundantly stored in the array
- Capacity penalty to store redundant info
- Bandwidth penalty to update redundant info



Conclusion
- Great Idea: Redundancy to Get Dependability
- Spatial (extra hardware) and Temporal (retry if error)
- Reliability: MTTF, Annualized Failure Rate (AFR), and FIT
- Availability: % uptime (MTTF/MTTF+MTTR)
- Memory
- Hamming distance 2: Parity for Single Error Detect
- Hamming distance 3: Single Error Correction Code + encode bit position of error
- Treat disks like memory, except you know when a disk has failed—erasure makes parity an Error Correcting Code
- RAID-2, -3, -4, -5 (and -6, -10): Interleaved data and parity
Lecture 39
What is a GPU
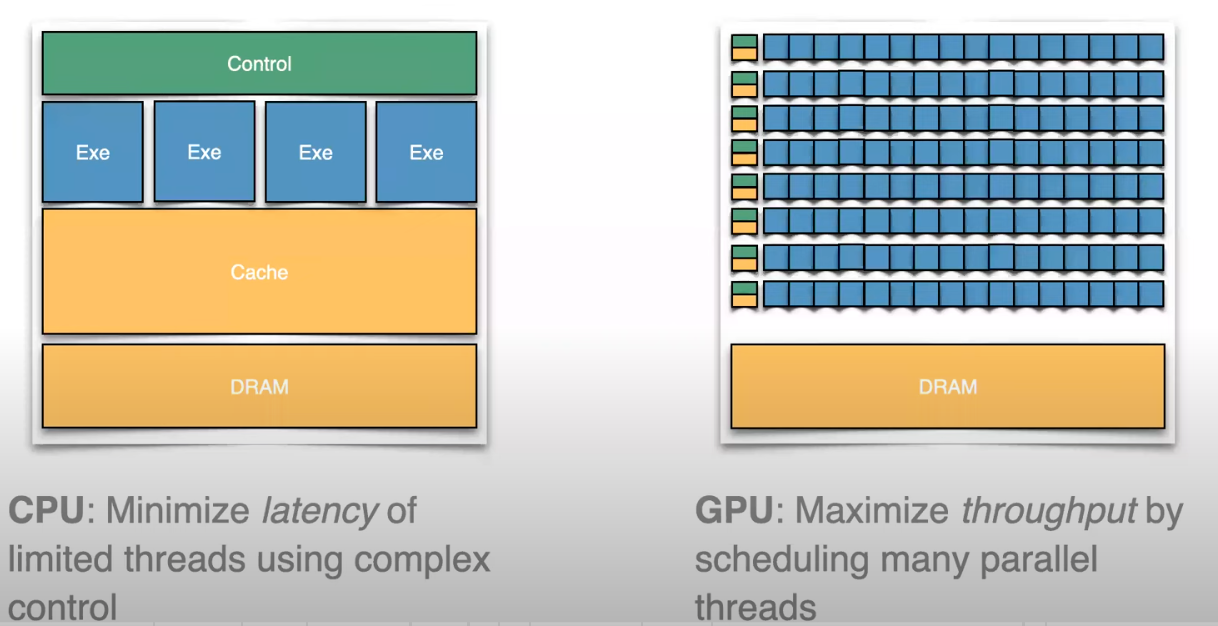
- 相比CPU: 通过规划并行threads最大化Throughput。
- 更多的cores,更低的frequency,更简单,Software Managed Coherency。
- 更高的Memory Latency,但是更高的Bandwidth。
- High throughput SIMD leveraging。
- 线程被分组为Threadgroups (aka Blocks or Workgroups)
Graphics Pipeline Overview
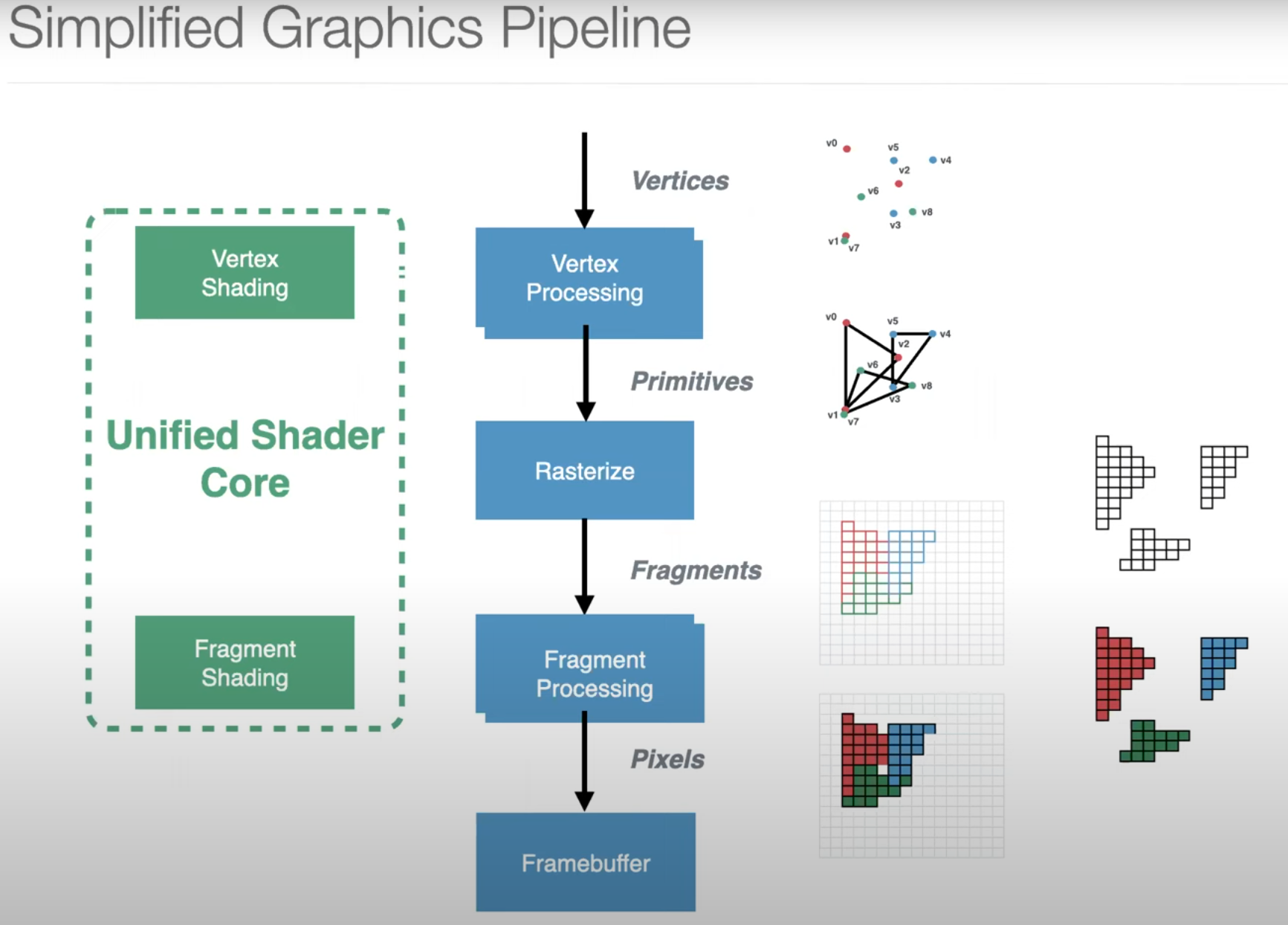
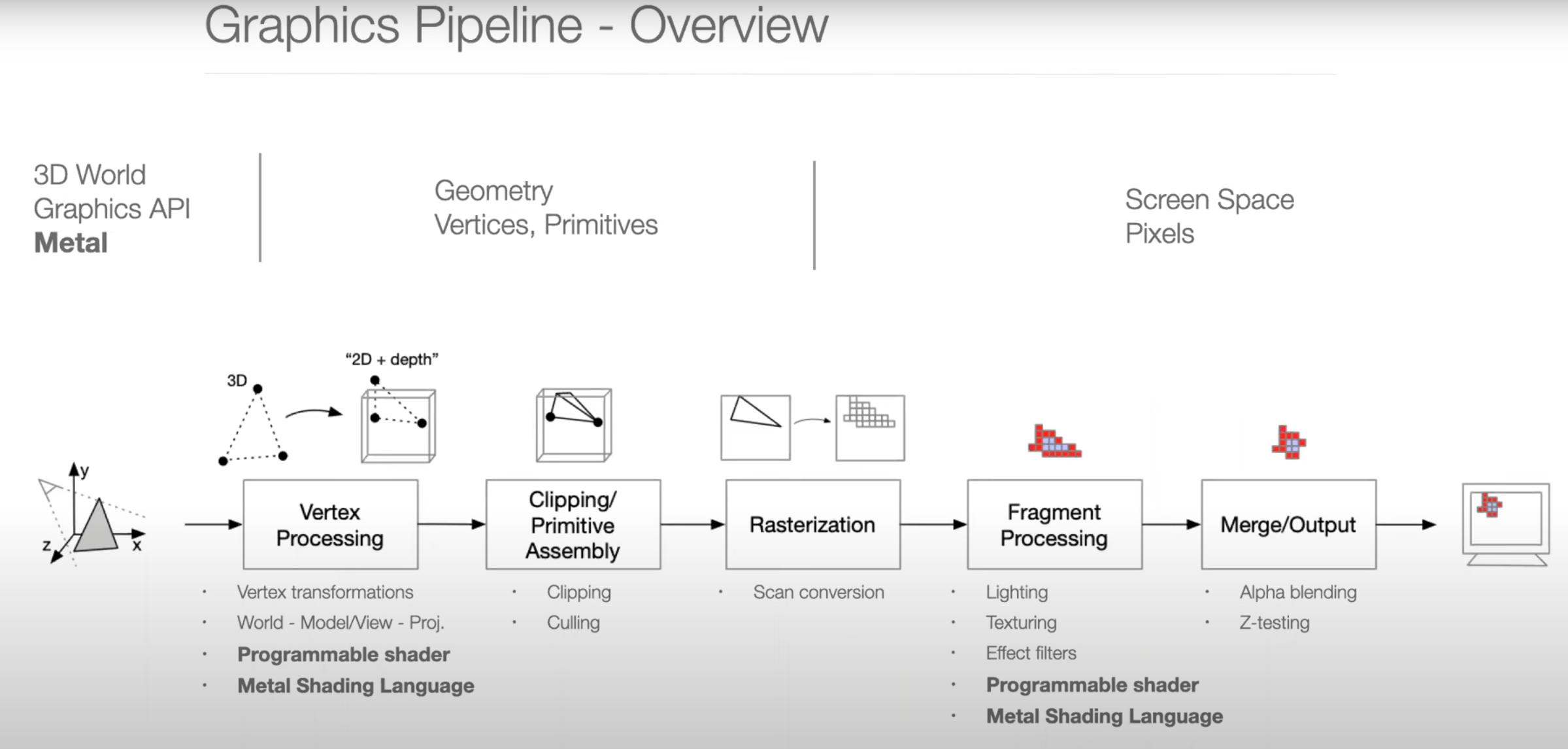
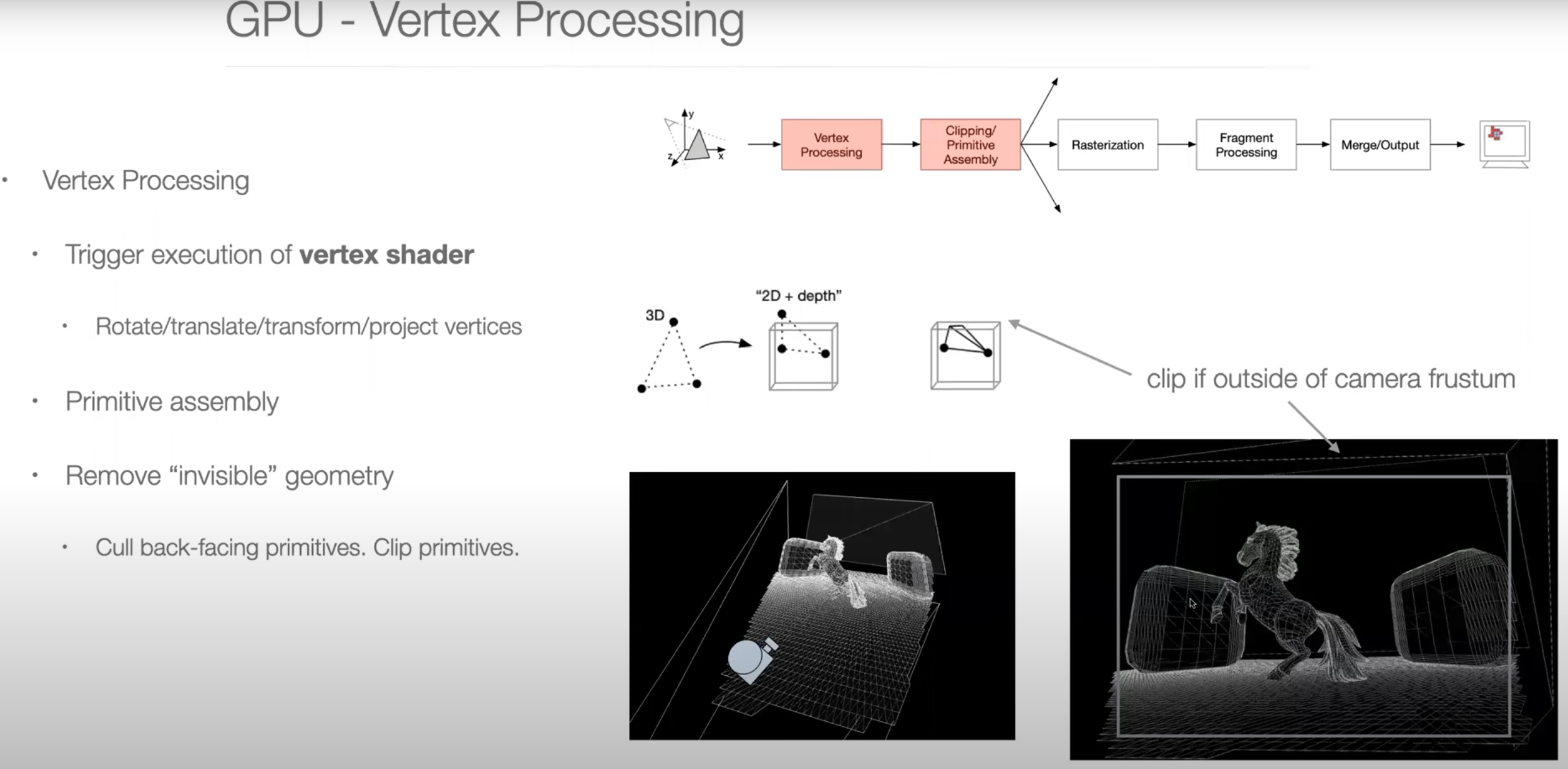
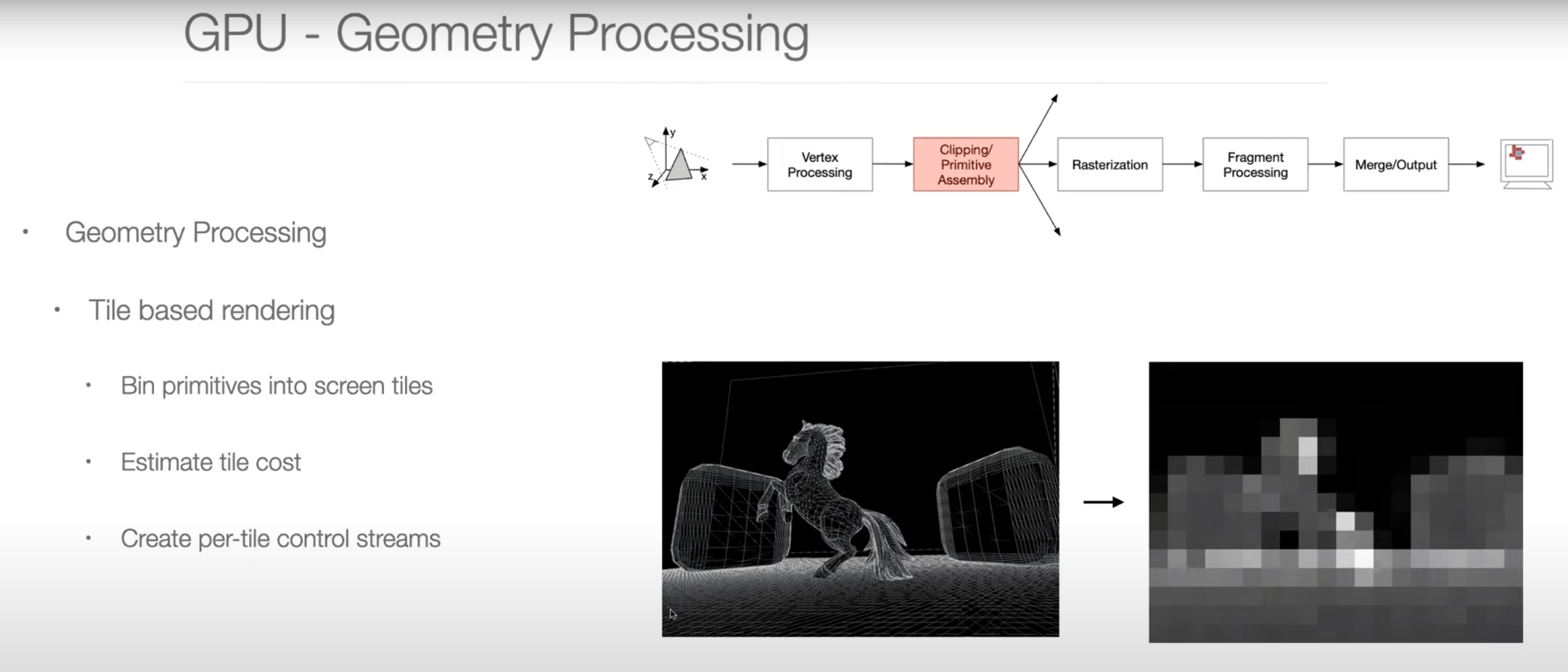
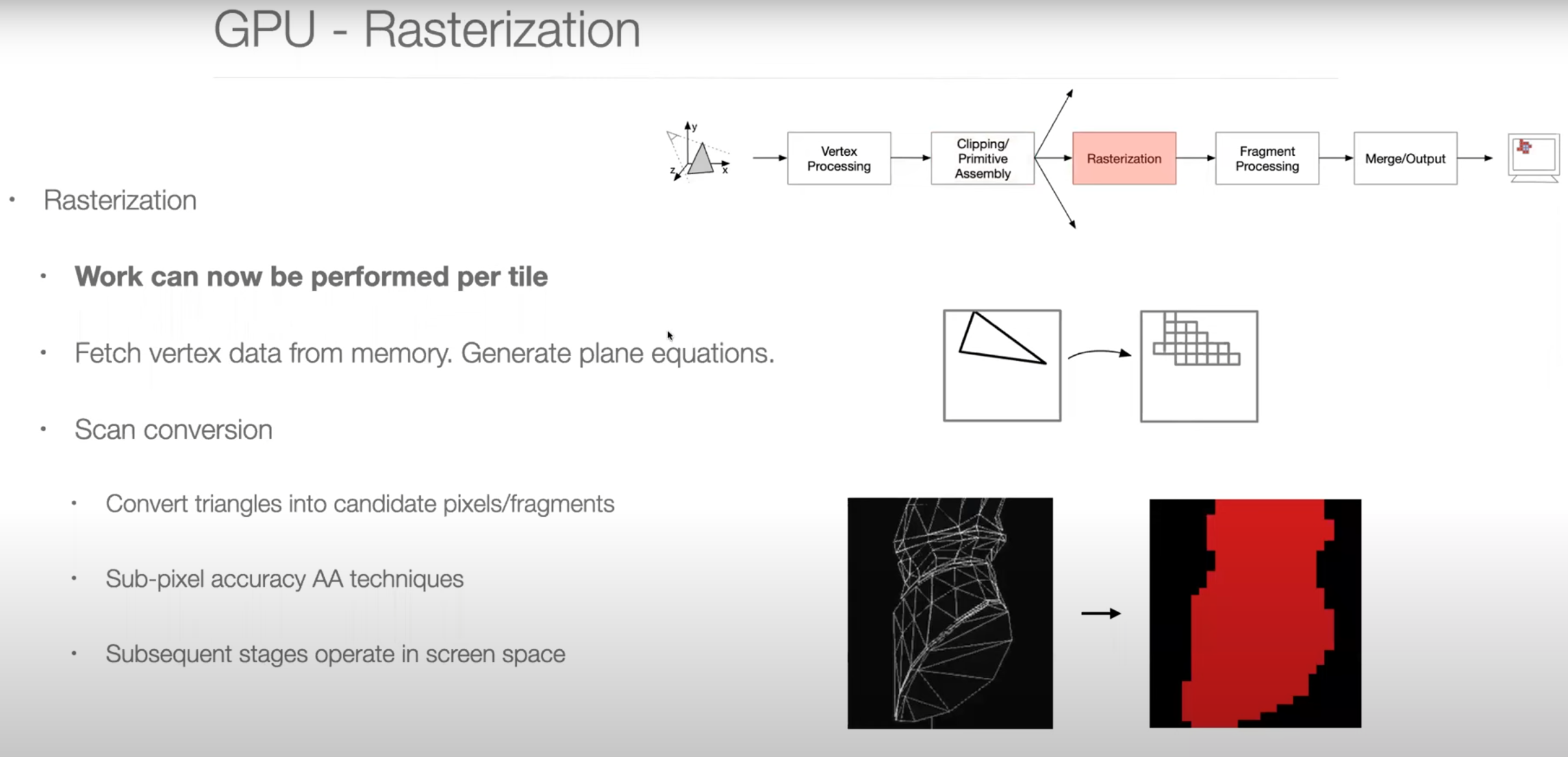
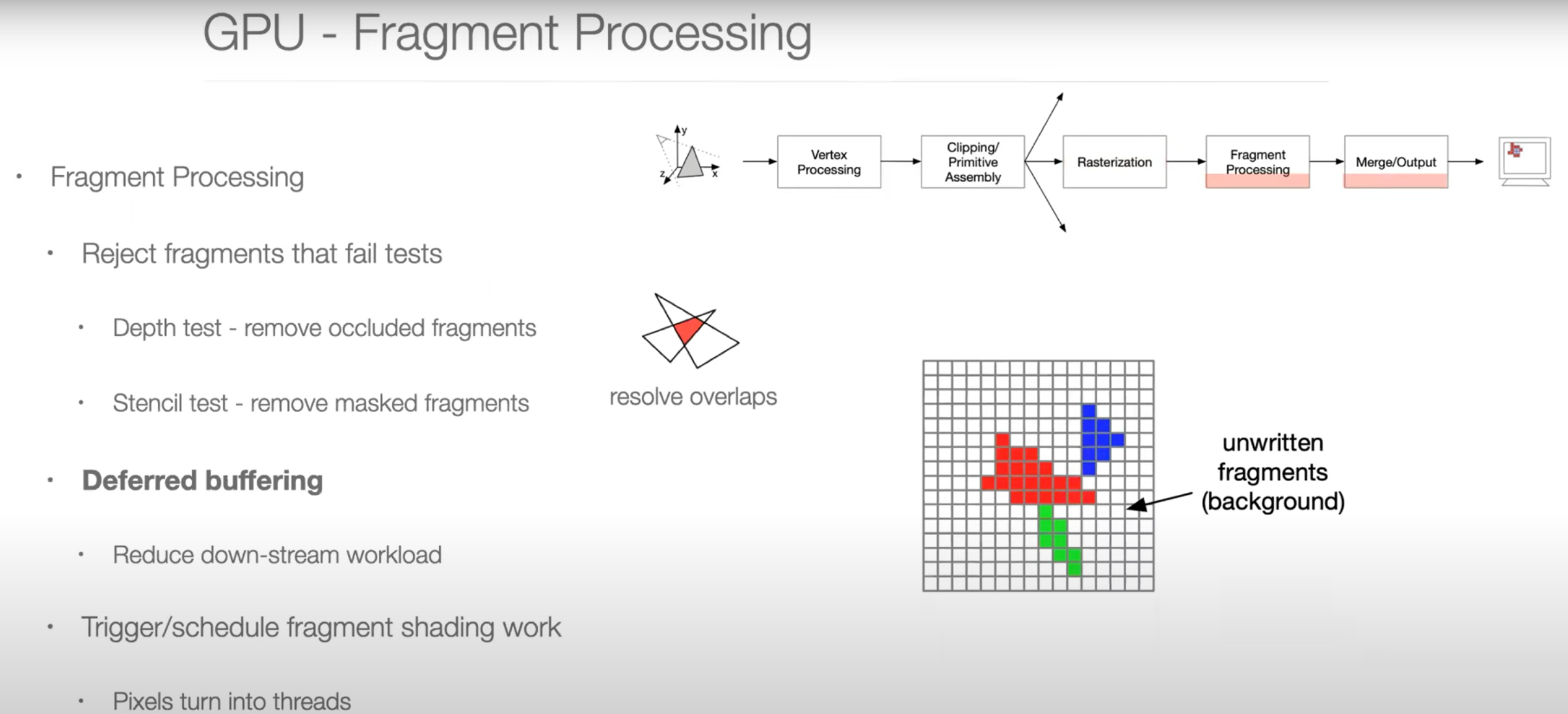
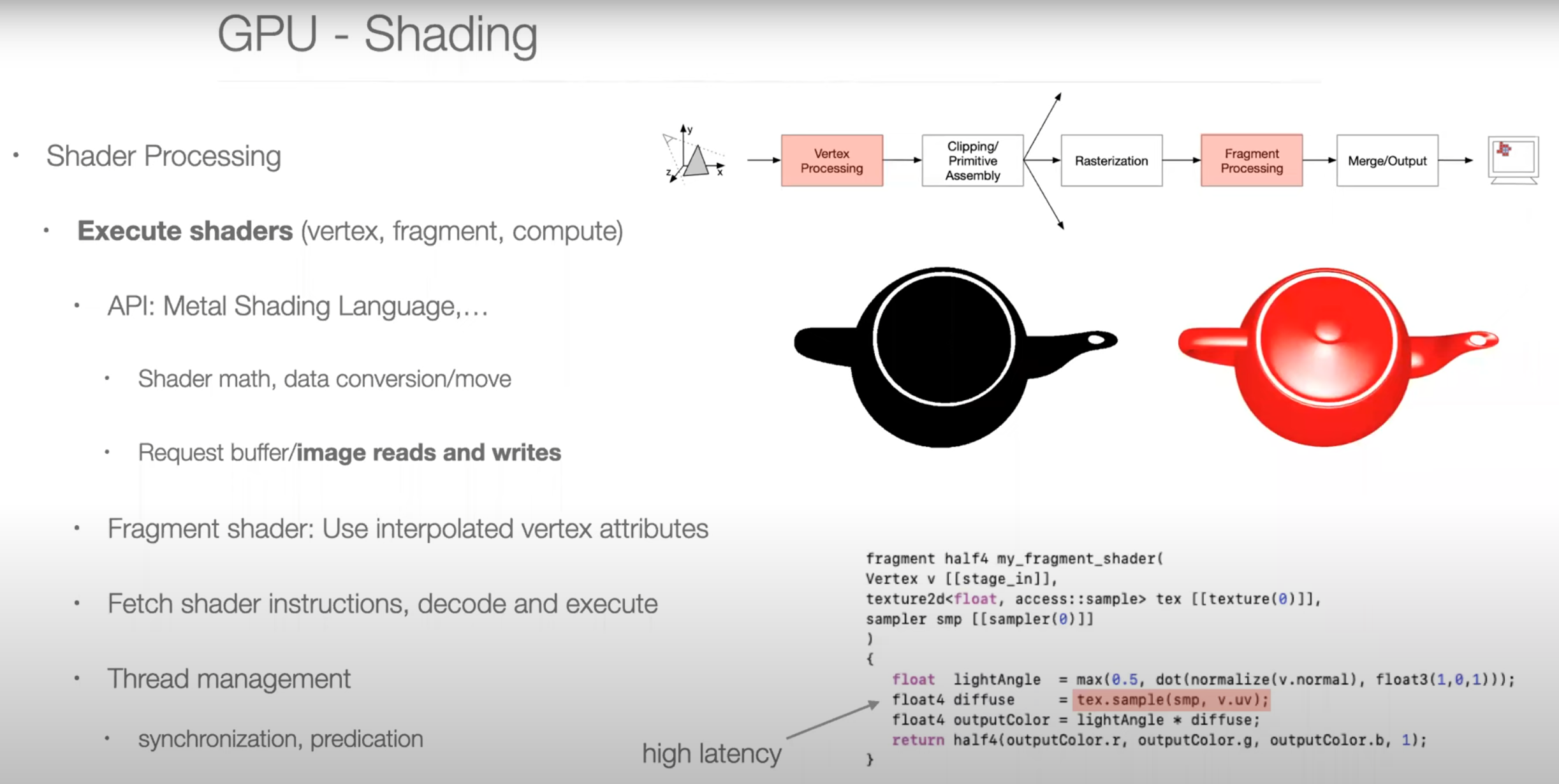
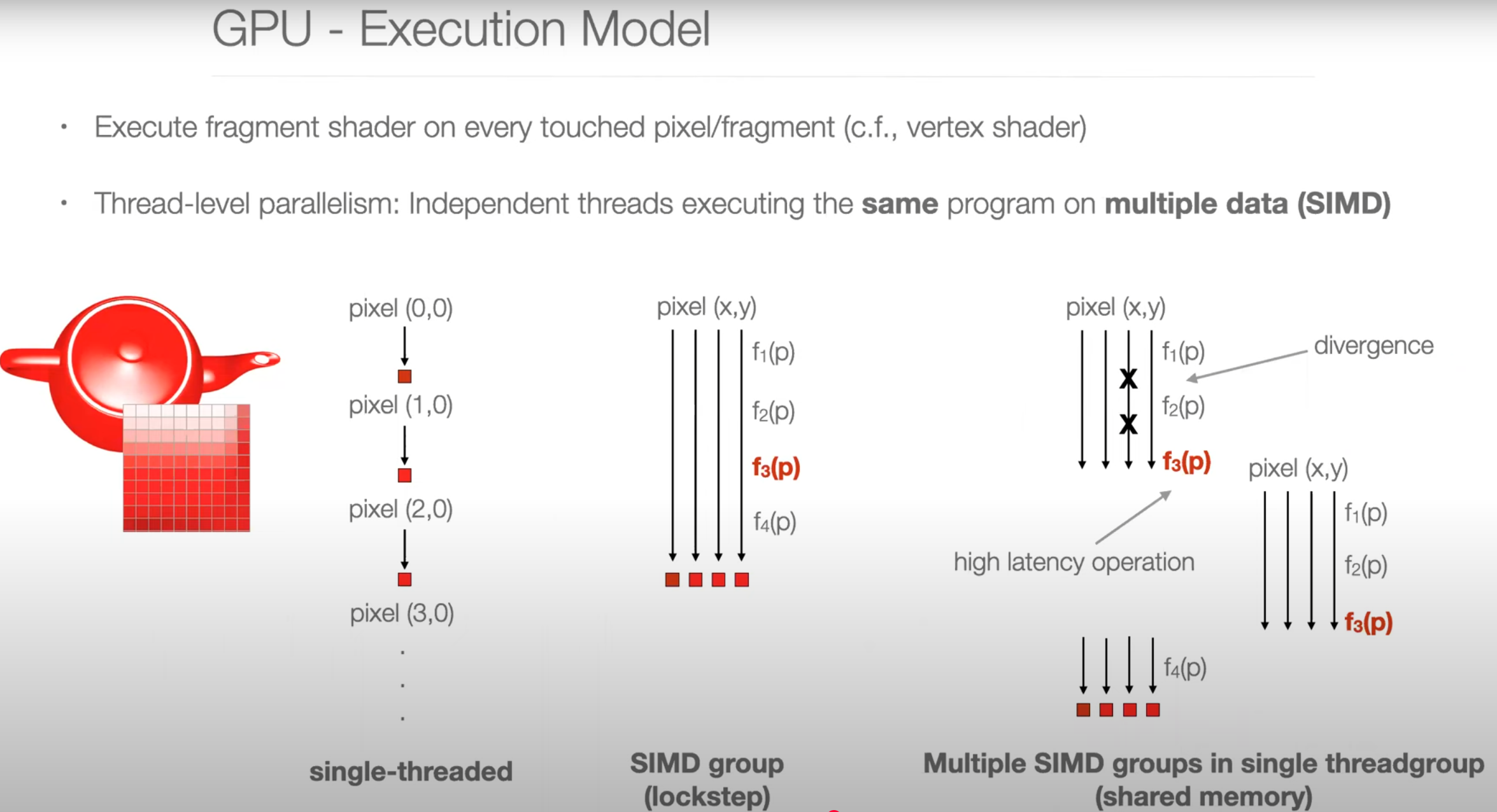
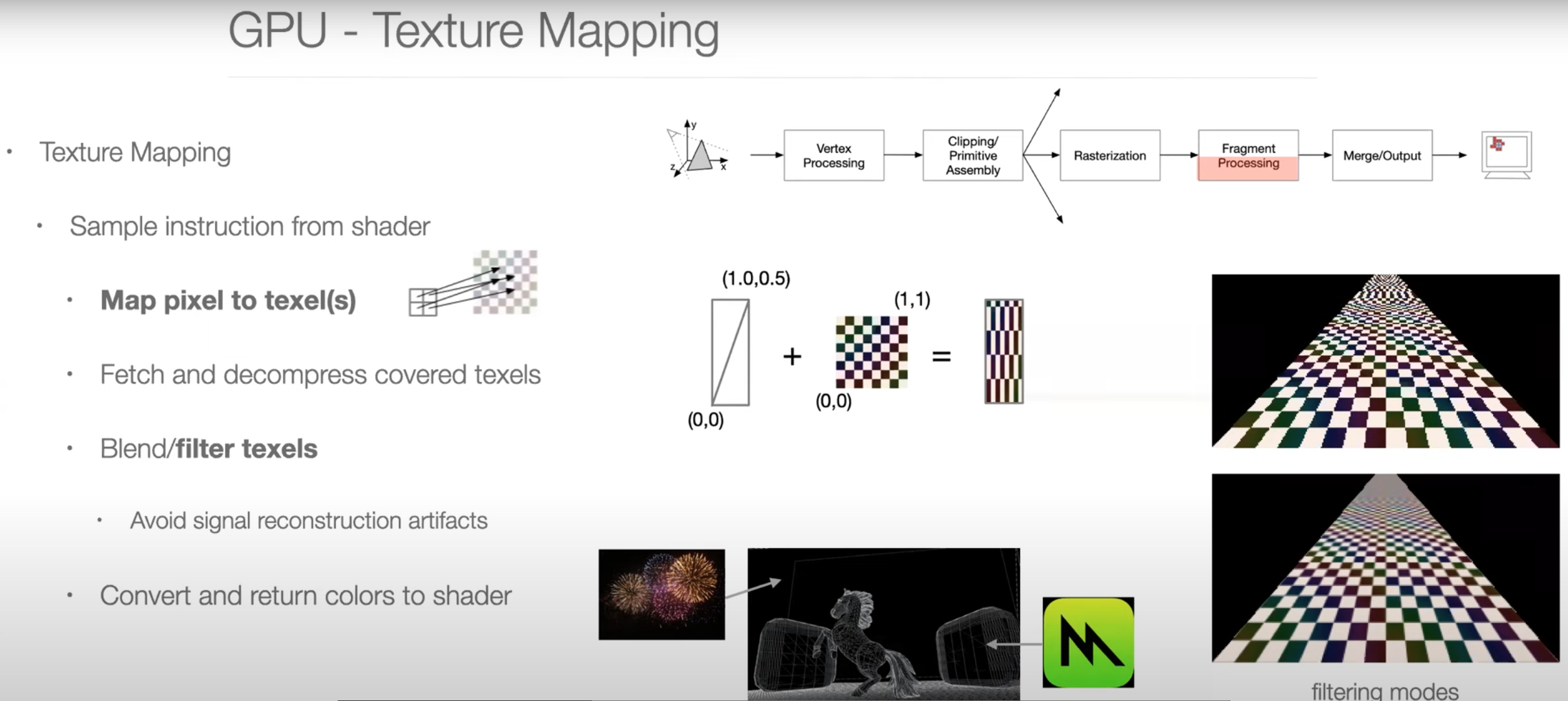
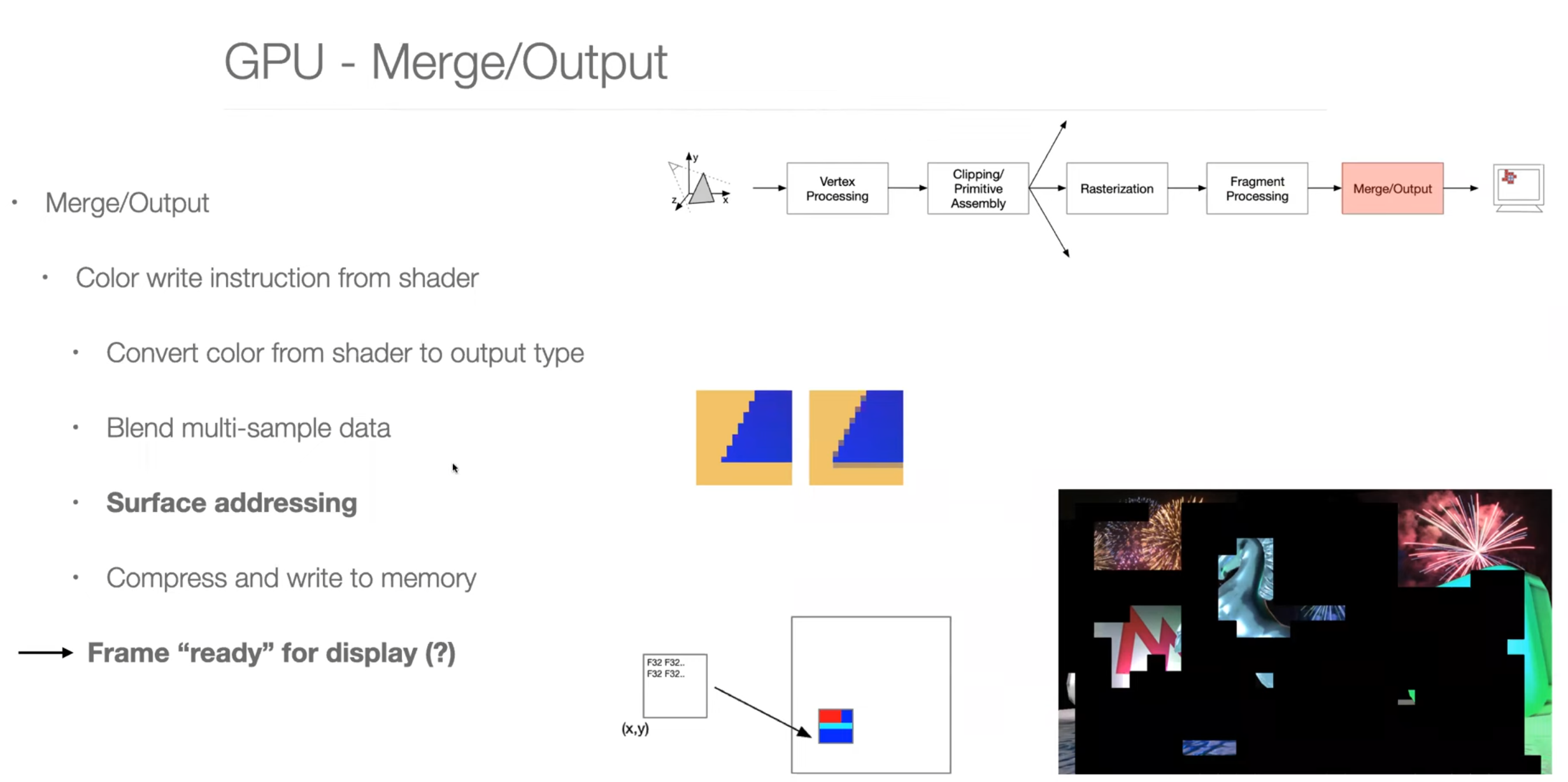
Parallel Programming Example
- 当data变大时,GPU上比CPU快得多
完结撒花,lab和proj有空整理了再发!

